0x01 安装beautifulsoup4库
pip3 install beautifulsoup4
0x02 初始化操作
通过BeautifulSoup初始化要操作的字符串
from bs4 import BeautifulSoupimport requestsurl = "https://www.dandanzan10.top/dianying/index.html"heads = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',}r = requests.get(url, headers=heads)str = r.textsp=BeautifulSoup(str,'lxml')print(sp)
0x03 获取电影名字
1、右击要获取的字符串,选择审查元素
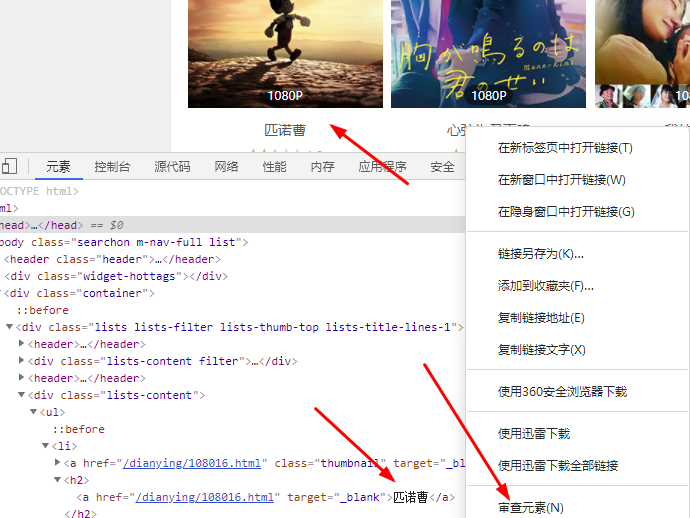
2、匹诺曹在h2标签下
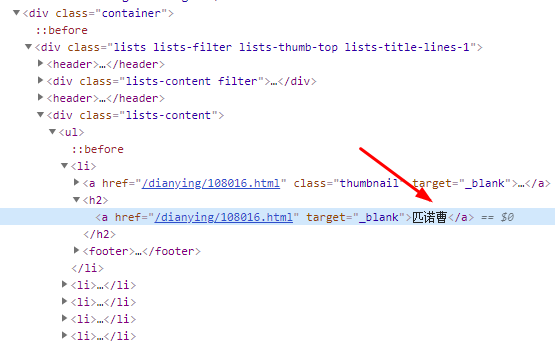
3、代码实现
from bs4 import BeautifulSoupimport requestsurl = "https://www.dandanzan10.top/dianying/index.html"heads = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',}r = requests.get(url, headers=heads)str = r.textsp=BeautifulSoup(str,'lxml')print(sp.h2.string)
0x04 获取该页面的所有电影名
from bs4 import BeautifulSoupimport requestsurl = "https://www.dandanzan10.top/dianying/index.html"heads = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',}r = requests.get(url, headers=heads)str = r.textsp=BeautifulSoup(str,'lxml')for h2 in sp.find_all(name='h2'):print(h2.string)运行结果: 匹诺曹心弦为君而鸣我的爸爸犬部!孩子不想理解独自生活的人们欧比旺:绝地归来欢快的鬼魂雷神4:爱与雷霆致命邮件:2001 美国炭疽攻击事件布朗克斯大战吸血鬼嚎笑捉鬼队旅馆闹鬼闲山:龙的出现非常宣言鬼影实录:血亲小犬与女孩小鹿乱撞爱上你单向逃离防线-秘密护送爱的透视图坏种2婚头转向海豹自卫队
1、sp.find_all(name='h2'):获取标签h2的所有内容,这是一个列表
2、通过循环输出出来
3、通过string获取里面的字符串
0x05 声明
仅供安全研究与学习之用,若将工具做其他用途,由使用者承担全部法律及连带责任,作者不承担任何法律及连带责任。
欢迎关注编程者吧



文章评论