
【CSDN编者按】不管我们如何希望PHP永远天下第一,亦或是Java永久无敌,更或者希望C语言永远是最好的语言。
然而,笔者今天搜索百度指数得知,Python的指数,已经高于Java和PHP的指数之和。
而Python的版本迭代也是嗖嗖的,那么新版本4.0和3.0究竟有什么区别呢?今天分享一篇Python软件基金会的董事会成员、CPython的核心开发人员Nick Coghlan的文章,希望你会感兴趣。
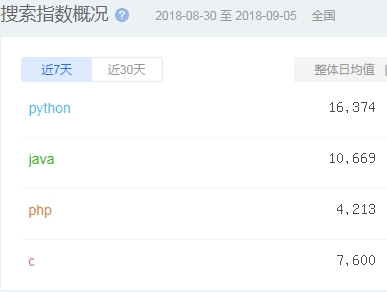
笔者今天在百度指数的搜索结果

一些刚刚接触Python思想的人,会提出无法向后兼容的修改建议,这些建议并没有针对,当前合法的Python 3代码,给出明确的移植方案,而他们偶尔会提及Python 4000的思想。毕竟,Python 3.0时,我们允许了这类改动,为什么Python 4.0就不允许呢?
这样的问题我已经听过很多次了(包括有人非常担心地说:“你已经让向后兼容性遭到了一次破坏,我怎么知道你还会不会再来一次?”),我觉得我应该把我的答案写下来,将来有人问及,我就可以让他们来看这篇文章。

Python 4.0目前的期望是什么?
我目前的期望是:Python 4.0仅仅只是“Python 3.9之后的一个版本”。仅此而已。语言没有深刻的变化,也没有重大的向后兼容性问题,从Python 3.9到4.0,应该像从Python 3.3到3.4(或从2.6到2.7)一样平安无事。我甚至希望在版本升迁之际,应用程序的二进制接口(PEP 384引入的功能),能够保持稳定。
按照目前的语言功能的发布速度(大约每18个月发布一次),这意味着我们可能会在2023年看到Python 4.0,而不会有Python 3.10了。

那么Python将如何继续发展呢?
首先,也是最重要的,PEP流程没有任何变化,仍将持续提出向后兼容的更改,并将添加新模块(如asyncio)和语言功能(如yield from)等,以增强Python应用程序能够使用的功能。
随着时间的推移,Python 3在功能方面,将领先Python 2越来越多,即使Python 2用户,可以通过第三方模块或Python 3的后向移植,获得同等功能,也无法赶上Python 3的功能。
不同解释器实现和扩展的互相竞争,将继续探索增强Python的不同方法,包括PyPy关于JIT编译器生成和软件事务内存的尝试,以及科学和数据分析社区,对面向数组编程的探索(这种方式充分利用了,现代CPU和GPU所提供的向量化功能)。
与其他虚拟机运行时(如JVM和CLR)的集成,也有望随着时间的推移,而改进,尤其是在教育领域取得的进展,可能会让Python作为更受欢迎的嵌入式脚本语言,在更大的应用程序中运行。
对于一些无法向后兼容的更改,PEP 387提供了一个合理的方法,该方法在Python 2系列中使用多年,并且今天仍然适用:即如果认为某个功能,会引起很大的问题,那么可以将其标记为弃用,最终将其删除。
但是,开发和发布过程中,发生的许多其他更改,并不太可能在Python 3系列中被标记为弃用:
• 这里主要强调一下Python包仓库,这是CPython核心开发团队和Python Packaging Authority通力协作的成果,而且Python 3.4+捆绑了pip的安装程序,减少了向标准库添加模块的难度,即使你还不确定它们,足够稳定以适应相对较慢的语言更新周期。
• “临时API”概念(由PEP 411引入),可以在提供标准的向后兼容性保证之前,允许你设置“过渡期”来获得更广泛的回馈,从而有助于库和API的构建。
• 很多累积下来的遗留行为,在Python 3转换过程中,得到了确实的解决,现在对Python和标准库新增功能的要求,也比Python 1.x和Python 2.x时期要严格得多。
• “单一来源”的Python 2/3库和框架,被广泛接受,极大地鼓励了在Python 3中使用“弃用功能文档”,即使这些功能被新的、更好的功能替代。在这些情况下,文档中设置的弃用通知,会建议新代码应当使用的方法,但不会产生程序上的弃用警告。这样一来现有代码(包括支持Python 2和Python 3的代码),可以保持不变(相应的代价是:新用户在面对维护现有代码库的任务时,可能需要学习的内容会稍微多一些)。

从英语到所有语言
还有一点值得一提的是,Python 3本来没打算,像现在这样具有破坏性。在Python 3中所有无法向后兼容的改变中,许多严重阻碍代码移植的困难,都可以归结为PEP 3100中的一点上:
• 让所有字符串都变成Unicode,并且拥有单独的bytes()类型。新的字符串类型将被称为'str'。
PEP 3100汇总了Python 3中所有争议性不大、从而没有必要单独建立PEP的改动。这个特殊的变化,被认为无争议的原因是:因为我们使用Python 2的经验表明,Web和GUI框架的作者是正确的,即作为应用程序开发人员明智地使用Unicode意味着,确保所有的文本数据,都可以从二进制尽可能地转换为系统的文本操作,然后在输出时转换回二进制。
遗憾的是,Python 2并不鼓励开发人员,以这种方式编写程序,这大大模糊了二进制数据和文本之间的界限,并使开发人员很难将两者区分开,更不用说代码了。
因此,Web和GUI框架作者,必须告诉他们的Python 2的用户“使用Unicode文本。否则你就会在处理Unicode输入时,遇到捉摸不定、难以跟踪的bug”。
Python 3则不同:它在“二进制”和“文本”之间,做了更大的分离,使得编写正常的应用程序代码更加容易,但也使得在那些二进制和文本数据的区别,不那么清晰。
Python对Unicode的支持的这场革命,针对的是更大的关于计算文本操作移植的背景:从只有英文的ASCII(1963年正式定义),到“二进制数据+编码声明”模型(包括20世纪80年代后期,引入的C/POSIX语言环境和Windows代码页系统),以及最初的16位Unicode标准版本(1991年发布)到相对全面的现代Unicode代码点系统(1996年首次定义,每隔几年都有一次最新的主要更新)。
为什么要提这一点?因为改变到“默认使用Unicode”,是Python 3中最具有破坏性的、无法向后兼容的改动,而且与其他(更依赖于具体语言特性的)改动不同,它只是如何表示和操作文本数据这项大范围的改动中的一小部分。
随着Python 3转换清除了一些语言特定的问题,与Python早期相比,新的语言功能的门槛提高了很多,而且没有任何波及业界的移植的规模,比得上目前正在进行的,从“带编码的二进制数据”到用于文本建模的Unicode的切换。
所以我并不觉得,以后会有任何改动,能像Python 3这样,造成破坏向后兼容、并且需要并行支持期间。相反,我希望我们,能够在正常的变更管理流程中,适应任何未来的语言演变,任何无法以这种方式处理的提案,都会被拒绝,因为它会给社区和核心开发团队,带来高得令人无法接受的成本。
原文:https://opensource.com/life/14/9/why-python-4-wont-be-python-3
作者:Nick Coghlan,CPython的核心开发人员,Python软件基金会的董事会成员。他是几项Python增强建议的作者及合伙人(包括PEP 343:在Python 2.5中,添加了with语句和上下文管理器,PEP 453:与Python 3.4捆绑在一起的pip安装程序),并作为BDFL的代理人,代替吉多·范罗苏姆(Guido van Rossum)处理许多PEP申请。
译者:弯月,责编:胡巍巍
征稿啦”
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱([email protected])。
————— 推荐阅读 —————





文章评论