前面的一些爬虫项目的练习其实只包含了简单的网页请求、网页获取。我们并没有实现从指定的网站获取指定的信息,也就是没有进行网页信息解析的步骤。通常来说,网页解析的方法包括三种:RE正则表达式匹配,Xpath提取,Beautifulsoup第三方库解析。今天,我们重点来介绍一下RE。
RE(Regular Expression)
正则表达式(Regular Expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。用正则表达式来解析网页的原理是,所有的网页代码可以看作长长的字符串,我们可以通过内容的匹配截取到相应的字符串,从而将所需要的信息提取出来。
RE 入门教程
关于RE的入门教程,大家可以到如下网站进行练习。
-
编程胶囊的正则表达式入门教程(https://codejiaonang.com/#/course/regex_chapter1/0/0 )网站有很详细的正则表达式的匹配介绍,比较基础,伴随有相应的网页练习。
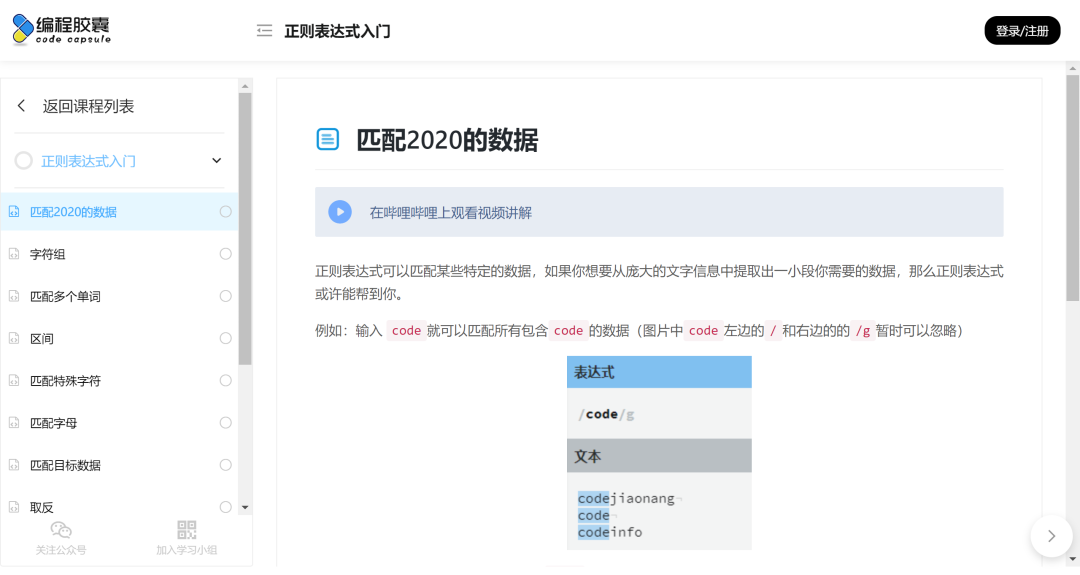
-
regexr网站(https://regexr-cn.com/ )是一个测试正则表达式的网站,上方写入表达式,下方放入被匹配的文本,匹配中的内容将显示蓝色底纹。
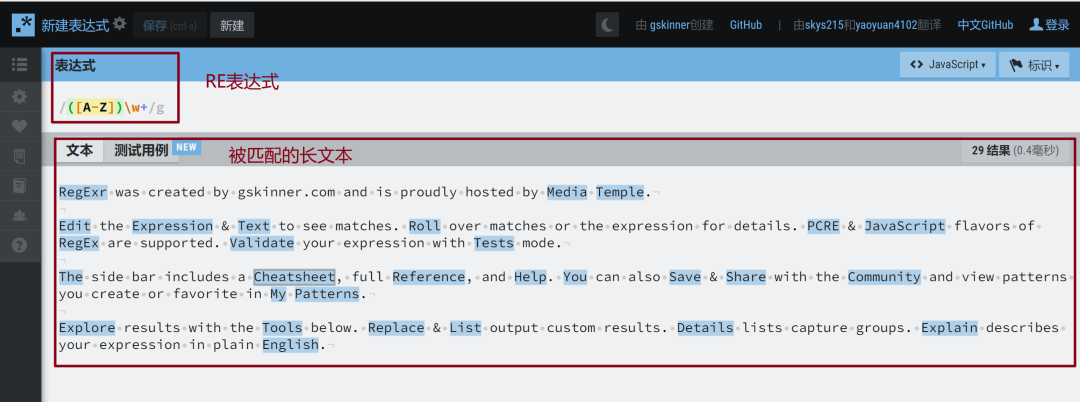
爬虫常用的正则表达
Python当中内置了RE的包,用于网页解析。事实上所有的正则表达式都会在某些特定情况下发挥功能。这里我们重点介绍以下几个正则表达:
-
. 任意一个字符 -
* 匹配前面的子表达式零次或多次。要匹配 * 字符,需要使用转义符 \*。 -
?匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,需要使用转义符 \?
由这三个特别字符构建的正则表达如下: -
惰性匹配 .*? 尽可能少的匹配内容
它会匹配尽可能少的字符,它从第一个字符开始找起,一旦符合条件,立刻保存到匹配集合中,然后继续进行查找。所以说它是懒惰的。 -
贪婪匹配 .* 尽可能多的匹配内容
它会匹配尽可能多的字符。它首先看整个字符串,如果不匹配,对字符串进行收缩;遇到可能匹配的文本,停止收缩,对文本进行扩展,当发现匹配的文本时,它不着急将该匹配保存到匹配集合中,而是对文本继续扩展,直到无法继续匹配 或者 扩展完整个字符串,然后将前面最后一个符合匹配的文本(也是最长的)保存起来到匹配集合中。所以说它是贪婪的。找到匹配的之后还是继续查找,若找到不合适的则返回最后一个匹配合适的。
python 当中的RE
import re #导入RE的包
常用的一些语法有:
re.findall语法为re.findall(pattern, string, flags=0),返回string中所有与pattern匹配的全部字符串,返回形式为数组。flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
-
re.I 忽略大小写 -
re.L 表示特殊字符集 w, W, ., B, s, S 依赖于当前环境 -
re.M 多行模式 -
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符) -
re.U 表示特殊字符集 w, W, ., B, d, D, s, S 依赖于 Unicode 字符属性数据库 -
re.X 为了增加可读性,忽略空格和 # 后面的注释
lst = re.findall(r"\d+","电子商务专业有2个班70+个人")
print(lst)
# findall 匹配字符串当中所有的符合正则的内容
返回结果:
['2', '70']
re.finditer 返回string中所有与pattern匹配的全部字符串,返回形式为迭代器,需要用group()拿取内容。
for i in re.finditer(r"\d+","电子商务专业有2个班70+个人"):
print(i.group())
返回结果:
2
70
re.search语法为re.research(pattern, string, flags=0)会匹配整个字符串,并返回第一个成功的匹配,,需要用group()拿取内容。
lst = re.search(r"\d+","电子商务专业有2个班70+个人")
print(lst)
返回结果:
<re.Match object; span=(7, 8), match='2'>
re.match语法为re.match(pattern, string, flags=0)从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
lst = re.match(r"\d+","电子商务专业有2个班70+个人")
print(lst)
返回结果:
None
lst = re.match(r"\d+","1个电子商务专业有2个班70+个人")
print(lst)
返回结果:
<re.Match object; span=(0, 1), match='1'>
re.compile()生成的是正则对象,单独使用没有任何意义,需要和findall(), search(), match()搭配使用
obj = re.compile(r"\d+")
res = obj.finditer("电子商务专业有2个班70+个人")
for i in res:
print(i.group())
返回结果:
2
70
txt = """
假如生命是一株小草,我愿为春天献上一点嫩绿;
假如生命是一棵大树,我愿为大地夏日撒下一片绿阴阴凉;
假如生命是一朵鲜花,我愿为世界奉上一缕馨香;
假如生命是一枚果实,我愿为人间留下一丝甘甜。
"""
obj = re.compile(r"假如生命是(?P<喻体>.*?),我愿为.*?[;|。]",re.S)
res = obj.finditer(txt)
for i in res:
print(i.group("喻体"))
返回结果:
一株小草
一棵大树
一朵鲜花
一枚果实
re.S的作用:忽略掉换行符\n,将所有内容看作一整个长字符串看待。
import re
a = """sdfkhellolsdlfsdfiooefo:
877898989worldafdsf"""
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print ('b is ' , b)
print ('c is ' , c)
返回结果:
b is []
c is ['lsdlfsdfiooefo:\n877898989']

文章评论