? 连享会 · 推文导航 | www.lianxh.cn

-
? Stata:Stata基础 | Stata绘图 | Stata程序 | Stata新命令 -
? 论文:数据处理 | 结果输出 | 论文写作 | 数据分享 -
? 计量:回归分析 | 交乘项-调节 | IV-GMM | 时间序列 | 面板数据 | 空间计量 | Probit-Logit | 分位数回归 -
⛳ 专题:SFA-DEA | 生存分析 | 爬虫 | 机器学习 | 文本分析 -
? 因果:DID | RDD | 因果推断 | 合成控制法 | PSM-Matching -
? 工具:工具软件 | Markdown | Python-R-Stata -
? 课程:公开课-直播 | 计量专题 | 关于连享会
连享会 · 2022 空间计量专题

作者:梁淑珍 (华侨大学)
邮箱:[email protected]
编者按:本文主要整理自「Jaccard similarity and Jaccard distance in Python」,特此致谢!
温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:

目录
-
1. 前言
-
2. Jaccard 相似度的定义
-
3. Jaccard 相似度的计算
-
4. Jaccard 距离的定义
-
5. Jaccard 距离的计算
-
6. 非对称二元变量的相似度和距离
-
7. Python 计算 Jaccard 相似度
-
8. Python 计算 Jaccard 距离
-
9. Python 计算非对称二元变量
-
10. Python 计算中文 Jaccard 相似度
-
11. 相关推文
1. 前言
Jaccard 相似度,广泛应用于数据之间相似程度的计算,如集合相似度、文本相似度等。本文的 Python 实例需要使用到 scipy、sklearn 和 numpy 三个模块,具体安装命令如下:
pip install scipy
pip install sklearn
pip install numpy
2. Jaccard 相似度的定义
Jaccard 相似度 (又称 Jaccard 相似系数,或 Jaccard 指数),是用来计算两个集合之间相似度的统计量,并且可以拓展至文本相似度的计算。在 Python 中,主要用 Jaccard 相似度来计算两个集合或非对称二元变量的相似度。在数学上,Jaccard 相似度可以表示为交集与并集之比。以集合 A 和集合 B 为例:

Jaccard 相似度的计算公式为:
公式的分子部分为两个集合的交集,如下图黄色部分所示:
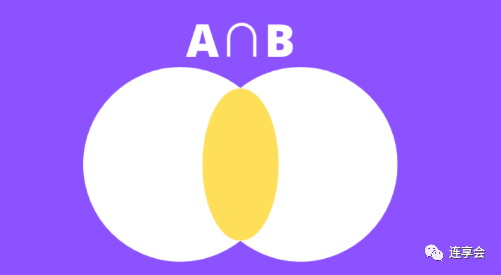
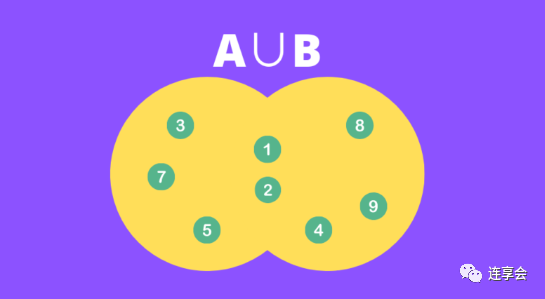
公式的分母部分为两个集合的并集,如下图黄色部分所示:

在数学上,Jaccard 相似度可以理解为上图交集元素个数与并集元素个数之比,具体地:
-
如果两个集合相等,例如 和 ,那么 Jaccard 相似度为 1; -
如果两个集合元素完全不同,例如 和 ,那么 Jaccard 相似度为 0; -
如果两个集合有部分相同元素,例如 和 ,那么 Jaccard 相似度介于 0 和 1。
3. Jaccard 相似度的计算
考虑以下两个集合: 和 ,在图中可以表示为:

第一步:找到两个集合的交集。在本例中,。
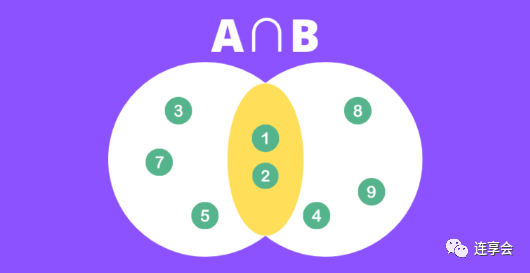
第二步:找到两个集合的并集。在本例中,。
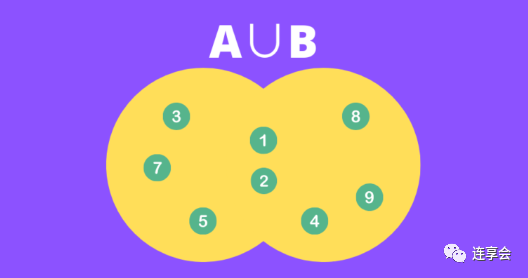
第三步:计算比率。
4. Jaccard 距离的定义
与 Jaccard 相似度不同,Jaccard 距离测量的是两个集合不相似程度。在数学上,可以表示为交集的补集与并集之比。同样以集合 A 和集合 B 为例:

Jaccard 距离的公式为:
Jaccard 距离的分子还能表示为:
可以更直观地理解为两个集合间的差异,如下图黄色部分所示:
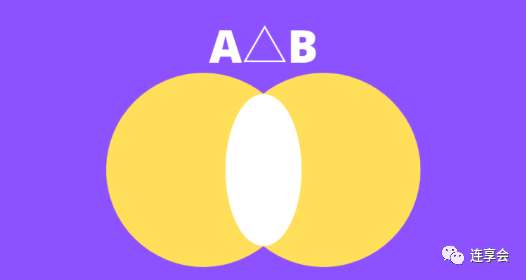
Jaccard 距离的分母与 Jaccard 相似度相同,均为两个集合的并集。

在数学上,Jaccard 距离可以理解为集合差异元素个数与并集元素个数之比。具体地:
-
如果两个集合相等,例如 和 ,那么 Jaccard 距离为 0; -
如果两个集合元素完全不同,例如 和 ,那么 Jaccard 距离为 1; -
如果两个集合有部分相同元素,例如 和 ,那么 Jaccard 距离介于 0 和 1。
5. Jaccard 距离的计算
考虑以下两个集合: 和 ,在图中可以表示为:

第一步:找到两个集合交集的补集。
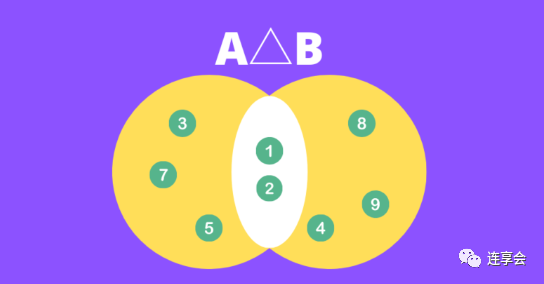
第二步:找到两个集合的并集。在本例中,。
第三步:计算比率。
6. 非对称二元变量的相似度和距离
本节将讨论 Jaccard 相似度和 Jaccard 距离在非对称二元变量上的具体应用。
二元变量,顾名思义只有两个类别或状态。当取值为 0 时,表示该状态不出现;当取值为 1 时,表示该状态出现。例如,smoker 表示患者对象,1 表示患者抽烟,0 表示患者不抽烟。如果是对称二元变量,则其两种属性具有相同的权重,即不同状态用 0 或 1 编码并无偏好 (例如,用 0 和 1 编码表示性别变量)。
非对称二元变量的两种结果重要程度不同。例如核酸检测的结果分为阳性和阴性,阳性结果用 1 进行编码 (几率更低,结果更重要),阴性结果用 0 进行编码。给定两个非对称二元变量对象,两个对象都取 1 的情况比两个对象都取 0 更重要、更有意义。
假设现有两个 n 维向量 A 和 B,Jaccard 相似度的计算公式为:
Jaccard 距离的计算公式为:
其中,
-
表示两个向量对应分量均为 1 的数量; -
表示两个向量对应分量分别为 0 和 1 的数量; -
表示两个向量对应分量分别为 1 和 0 的数量; -
表示两个向量对应分量均为 0 的数量。
并且 。
我们通过一个简易案例进行理解,例如一家商店销售 6 种商品 (苹果、西红柿、鸡蛋、牛奶、咖啡、糖),现有两个顾客的购买记录:
-
顾客 A 购买:苹果、牛奶和咖啡 -
顾客 B 购买:鸡蛋、牛奶和咖啡
通过上面的信息,可以构造下列矩阵:
| Apple | Tomato | Eggs | Milk | Coffee | Sugar | |
|---|---|---|---|---|---|---|
| A | 1 | 0 | 0 | 1 | 1 | 1 |
| B | 0 | 0 | 1 | 1 | 1 | 0 |
对于每一种商品而言,购买决策是一个二元变量,1 表示购买,0 表示不购买。接着,我们分两步计算 Jaccard 相似度和 Jaccard 距离:
第一步:寻找 M 值
| 数量 | 说明 | |
|---|---|---|
| (M_{11}) | 2 | A 和 B 都买了牛奶和咖啡 |
| (M_{01}) | 1 | A 没买鸡蛋,B 买了鸡蛋 |
| (M_{10}) | 2 | A 买了苹果和糖,但 B 都没买 |
| (M_{00}) | 1 | A 和 B 都没买西红柿 |
且 ,与商品数相同,得到验证。
第二步:代入公式,则
-
Jaccard相似度:
-
Jaccard 距离:
7. Python 计算 Jaccard 相似度
在 Python 中定义两个集合:
A = {1, 2, 3, 5, 7}
B = {1, 2, 4, 8, 9}
构建函数计算 Jaccard 相似度,将集合 A 和集合 B 当做参数传入函数:
def jaccard_similarity(A, B):
# 求集合 A 和集合 B 的交集
nominator = A.intersection(B)
# 求集合 A 和集合 B 的并集
denominator = A.union(B)
# 计算比率
similarity = len(nominator)/len(denominator)
return similarity
similarity = jaccard_similarity(A, B)
print(similarity)
结果为 0.25,与手动计算的结果相同。
8. Python 计算 Jaccard 距离
使用相同的数据计算 Jaccard 距离:
def jaccard_distance(A, B):
#Find symmetric difference of two sets
nominator = A.symmetric_difference(B)
#Find union of two sets
denominator = A.union(B)
#Take the ratio of sizes
distance = len(nominator)/len(denominator)
return distance
distance = jaccard_distance(A, B)
print(distance)
结果为 0.75,与手动计算的结果相同。
9. Python 计算非对称二元变量
# 导入模块
import numpy as np
from scipy.spatial.distance import jaccard
from sklearn.metrics import jaccard_score
根据矩阵创建两个向量:
| Apple | Tomato | Eggs | Milk | Coffee | Sugar | |
|---|---|---|---|---|---|---|
| A | 1 | 0 | 0 | 1 | 1 | 1 |
| B | 0 | 0 | 1 | 1 | 1 | 0 |
A = np.array([1,0,0,1,1,1])
B = np.array([0,0,1,1,1,0])
similarity = jaccard_score(A, B)
distance = jaccard(A, B)
print(f'Jaccard similarity is equal to: {similarity}')
print(f'Jaccard distance is equal to: {distance}')
得到的结果为:
Jaccard similarity is equal to: 0.4
Jaccard distance is equal to: 0.6
10. Python 计算中文 Jaccard 相似度
import pandas as pd
import jieba
import re
# 调用数据
data = pd.read_excel("https://file.lianxh.cn/data/m/mda.xlsx")
stopwords = pd.read_csv("https://file.lianxh.cn/data/c/cn_stopwords.txt", names=["stopwords"])
# 定义分词函数def cut_words(text):
def cut_words(text):
words_list = []
text = re.sub("[\W\d]", "", text) # 替换符号和数字
words = jieba.lcut(text)
for word in words:
if word not in list(stopwords["stopwords"]):
words_list.append(word)
return" ".join(words_list)
# 对文本分词
data["BusDA"] = data["BusDA"].apply(cut_words)
data
# 定义 jaccard 相似度函数
def jaccard_similarity(list1, list2):
s1 = set(list1)
s2 = set(list2)
return float(len(s1.intersection(s2)) / len(s1.union(s2)))
jaccard_similarity(data["BusDA"][1], data["BusDA"][1])
11. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh python, m
安装最新版lianxh命令:
ssc install lianxh, replace
-
专题:专题课程 -
Stata+Python:同花顺里爬取创历史新高的股票 -
专题:数据分享 -
Python+Stata:如何获取中国气象历史数据 -
专题:文本分析-爬虫 -
Python:计算管理层讨论与分析的余弦相似度 -
Stata+Python:爬取创历史新高股票列表 -
Python:爬取东方财富股吧评论进行情感分析 -
VaR 风险价值: Stata 及 Python 实现 -
支持向量机:Stata 和 Python 实现 -
Python爬虫: 《经济研究》研究热点和主题分析 -
专题:Python-R-Matlab -
Stata+Python:导入超大Excel文档的新思路-以国泰安为例 -
Stata-Python交互-10:Stata17 新特性之PyStata的配置与应用 -
Python:多进程、多线程及其爬虫应用 -
Python:爬取动态网站 -
Python爬取静态网站:以历史天气为例 -
Python:绘制动态地图-pyecharts -
Python爬虫1:小白系列之requests和json -
Python爬虫2:小白系列之requests和lxml -
Python爬虫:爬取华尔街日报的全部历史文章并翻译 -
Python爬虫:从SEC-EDGAR爬取股东治理数据-Shareholder-Activism -
Python:爬取巨潮网公告 -
Python:爬取上市公司公告-Wind-CSMAR -
Python: 6 小时爬完上交所和深交所的年报问询函 -
Python: 使用正则表达式从文本中定位并提取想要的内容
课程推荐:因果推断实用计量方法
主讲老师:邱嘉平教授
? 课程主页:https://gitee.com/lianxh/YGqjp

New! Stata 搜索神器:
lianxh和songblGIF 动图介绍
搜: 推文、数据分享、期刊论文、重现代码 ……
? 安装:
. ssc install lianxh
. ssc install songbl
? 使用:
. lianxh DID 倍分法
. songbl all
? 关于我们
-
连享会 ( www.lianxh.cn,推文列表) 由中山大学连玉君老师团队创办,定期分享实证分析经验。 -
直通车: ?【百度一下: 连享会】即可直达连享会主页。亦可进一步添加 「知乎」,「b 站」,「面板数据」,「公开课」 等关键词细化搜索。


文章评论