监控发展的历程
早期企业
⽆监控,全部都是⼈⼯盯着 服务器 操作系统 软件 ⽹络 等等。
中前期企业
半⾃动脚本监控,利⽤shell脚本这种类似的形式,做最简单的监控脚本,循环登陆机器 查看⼀些状态 之后⼈⼯记录,⽆报警 ⽆⾃动化 ⽆监控图形。
中期企业
⾃动化程序/脚本/软件/监控,脚本更新换代 开始使⽤各种开源⾮开源软件 程序 进⾏监控的搭建和开发,监控形成图形化,加⼊报警系统 ,有⼀定的监控本⾝⾃动化实现,这个阶段监控开始逐步成型 但是仍然缺乏精确度和稳定程度 报警的精细度。
中后期企业
集群式监控 各种外援监控⽅案。
监控开始⾃成体系 加⼊各种⾃动化。除去⾃⾝开发和搭建监控系统外,还会⼤量使⽤各种外围监控 (各种商品监控 例如云计算监控 监控宝 友盟等等)
监控发展出 内监控+ 外监控(内监控是企业⾃⼰搭建的⾃⽤监控, 外监控是 使⽤外援的商业监控产品 往往对产品的最外层接⼜和⽤户⾏为进⾏更宏观的监控)
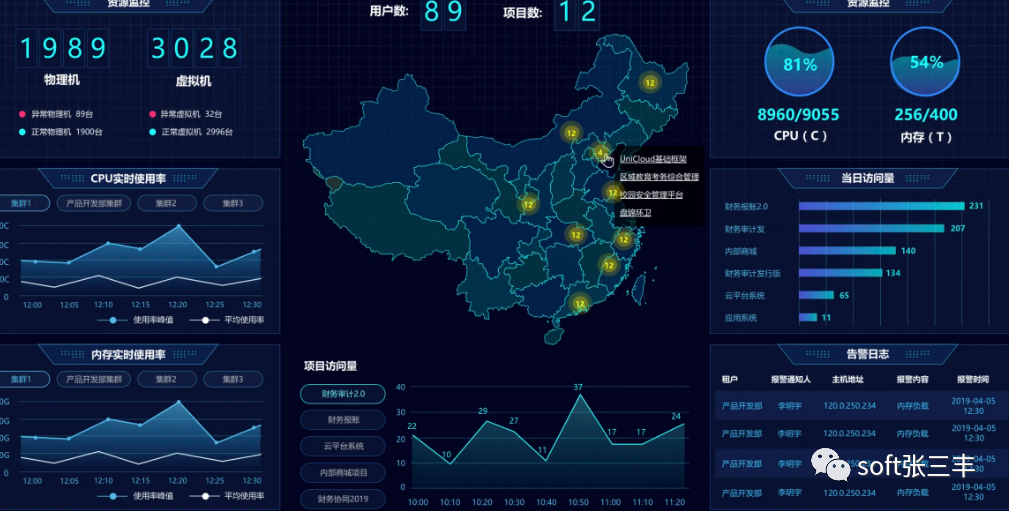
当前和未来监控
根据⽬前的发展状况
未来的监控 主要会在⼏个⽅⾯ 不断的提⾼
-
监控准确性 真实性
-
监控⾼度集成⾃动化 ⽆⼈值守
-
监控成本的⽇益降低
-
监控和CMDB的集成化以及⾃愈系统的发展
随着企业智能运维的不断建设,CMDB作为运维数据治理的重要手段日益重要。传统配置管理存在数据质量差、消费场景单一、无法支撑业务等问题。配置管理(CMDB)产品管理企业IT运维的元数据并确保数据的正确,以可配置、可维护的数据支撑力量促进运维监控、服务管理、运维自动化以及运营分析相关的数据消费场景落地实施。
企业当前实用的技术和工具
-
脚本监控(当前依然使⽤最原始的 脚本运⾏的形式 采集和监控的公司 依然不在少数 很多时候是
为了节约成本) -
开源/⾮开源⼯具监控 如:Nagios / Cacti / icinga / Zabbix / Ntop / prometheus / 等等。
-
报警系统 :Pagerduty / ⾃建语⾳报警系统 / ⾃建邮件系统/ ⾃建短信通知 / 各种商业报警产品
监控目前面临的一些问题
-
监控⾃动化依然不够
-
很少能和CMDB完善的结合起来
-
监控依然需要⼤量的⼈⼯
-
监控的准确性和真实性 提⾼的缓慢
-
监控⼯具和⽅案的制定 较为潦草
-
对监控本⾝的重视程度 依然有待提⾼
未来理想化的监控
-
完整⾃愈式监控体系
监控和报警 总归还是只能发现问题。出现问题之后的处理 依然需要⼈⼯的⼤量⼲预。
未来当⾃愈系统完善之后,各种层级的问题 都会被各种⾃动化 持续集成 ⼈⼯智能 灾备 系统缓冲 等等技术⾃⾏修复。
-
真实链路式监控
监控和报警的准确性 真实性 发展到最终级的⼀个理想化模型。
举个例⼦:当系统发出报警信息后,往往是各个层级的报警 ⼀⼤堆⼀起发出 把真实引起问题的地⽅掩盖住,⾮常不利于我们即时的发现和处理问题。
例如:真实发⽣的问题 是在于 数据库的⼀个新的联合查询 对系统资源消耗太⼤,造成各个⽅⾯的资源被⼤量消耗 间接的就引起各种链路的问题。
于是乎 各个层⾯的报警 接踵⽽⾄, ⽇志在报警,慢查询在报警,数据库CPU 内存报警, 程序层TCP链接堆积报警, HTTP返回码5xx 499报警。
所有系统CPU 缓存报警, 企业级监控⽤户流量下降报警。
种种⼀堆⼀堆被连带出来的报警 全都暴露出来了,结果真正的背后原因 这⼀个祸根的DB查询反⽽没有被监控发现 或者说发现了 但是被彻底淹没了。
最终理想的未来报警系统 可以把所有⽆关的报警全部忽略掉,以链路的⽅式 对问题⼀查到底 把最终引起问题的地⽅ 报警出来 让运维和开发 即时做出响应和处理。
Prometheus监控报警系统
三丰,公众号:soft张三丰Prometheus监控报警系统
prometheus最终获得的metrics数据以K/V形式展示,根据key值我们可以查询到对应的vlaue,但是我们需要通过对数据的计算得到我们想要的一个系统(应用)性能的监控项,再设置相应阈值形成报警
以cpu的使用率为例
node_cpu是node_exporter返回的一个key,可用来统计cpu使用率
这个key代表linux中底层的cpu时间片累积数值
cpu时间:从系统开启CPU就开始工作了,它会记录自己在工作中总共使用的时间的累积量,保存在系统中
而累积的cpu使用时间还会分成几个重要的状态类型
cpu time分成user time(用户态使用时间) /sys time(内核态使用时间) /nice time(nice值分配使用时间) /idle time(空闲时间)/irq(中断时间)等
cpu使用率:cpu除idle(空闲)状态外,其他所有cpu状态的总和/总cpu时间,即cpu使用率=100%-idle/total
node_cpu代表的是cpu每核,每个状态下的使用时间累积数值
prometheus的数字查询命令行我们提供了非常丰富的计算函数
increase():用来针对counter这种持续增长的数值,截取其中一段时间的增量,如increase(node_cpu[1m])代表总cpu时间在一分钟内的增量
实际工作中的cpu为多核,采集到的数据也是为每一个核的cpu时间
sum():起到加合的作用
sum( increase(node_cpu[1m]) )即表示所有核下的cpu时间一分钟内的增量
通过标签过滤得到空闲状态下cpu使用时间node_cpu{mode=“idel”}
sum( increase(node_cpu{mode=“idel”}[1m]) )即表示空闲状态下所有核的CPU时间一分钟内的增量
但是在表达式浏览器查询的是所有监控主机的数据,使用sum()函数意味着把所有客户端的cpu都加入总和了
by():把sum加合到一起的数值按照指定的方式进行一层的拆分
by(instance)代表着区分不同的机器
sum( increase(node_cpu{mode=“idel”}[1m]) )by(instance)表示单台机器的空闲状态下所有核的CPU时间一分钟内的增量
sum( increase(node_cpu[1m]) )by(instance)表示单台机器的所有状态下所有核的CPU时间一分钟内的增量
1-sum( increase(node_cpu{mode=“idel”}[1m]) )by(instance)/sum( increase(node_cpu[1m]) )by(instance)*100表示单台机器的所有核cpu的使用率
Counter类型的数据,在使用时,需要结合increase()或rate()函数,数据才有意义
Guage类型的数据相较于Counter类型的数据,简单很多,得到的监控数据直接输出(不需要increase(),rate()之类的函数修饰,取得单位时间内的增量输入,才能得到用户期望的有意义的图)
一、数据过滤
1.标签过滤
(Prometheus图表下方的文字注释)
通过颜色区分不同的采集数据,可通过单击来选择要展示的数据
格式为key{label1=“value1”, label2=“value2”, … },label来自采集数据时,exporters默认提供或者用户自定义(如,查询node_cpu_seconds_total,下方显示node_cpu_seconds_total{cpu="1",instance="localhost:9100",job="agent",mode="user"})
可在查询的时候,指定label:
精确匹配=:node_cpu_seconds_total{mode="idle"}
模糊匹配~=:node_cpu_seconds_total{mode=~".*"}
模糊不匹配!=:node_cpu_seconds_total{mode!="idle.*"}
2.数值过滤
例:node_cpu_seconds_total{mode=~".*"} > 6000
node_exporter
1 监控cpu使用率
(1).Prometheus对linux cpu的采集并不是直接返回一个现成的cpu百分比,而是返回linux系统中底层的cpu时间片的累积数值;而不是通过top或uptime命令这种简单的方式查看cpu使用率。
(2).cpu时间:linux系统开启后,CPU开始进入工作状态,cpu记录其在工作中总共使用的“时间”的累积量并保存在操作系统中,每一个不同状态的CPU使用时间,都从0开始累计,而node_exporter会抓取常用的8种cpu状态的累计时间数值:
cpu user time:cpu用户态使用时间
sys time:系统/内核态使用时间
nice time:nice值分配使用时间
idle time:空闲时间
irq:中断时间
… 等等
(3).而cpu使用率是指,cpu的各种状态,除了idle以外的其他所有状态的总和除以cpu的总时间:node_cpu_seconds_total即为CPU从开机到当前,所使用的CPU的总时间;故cpu使用率算法:(1 - sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
公式解释:
假设,系统开机运行30分钟(暂时忽略核数,假设为1核),在这段时间中,CPU的使用如下:用户态 8分钟 + 内核态 15分钟 + IO等待态 0.5分钟 + 空闲状态 20分钟 + 其他状态 0分钟;则CPU使用率 = (所有非空闲状态的CPU使用时间总和) / (所有状态CPU时间总和),即(user(8m) + sys(1.5m) + iowa(0.5m) + 0)/(30m))= ((30m) - idle(20m) / (30m))=33.3%,这30分钟的CPU平均使用率为30%。
(4).Prometheus底层的数据采集,通过精密的算法形成的监控,更加准确、可信
(5).CPU使用率计算公式拆分
从整体来看,是通过(1-idle/total)*100%的方法获取CPU使用率:
(1 - sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
1)选择使用的key
node_cpu_seconds_total:此时在prometheus的Console中输入执行结果会有很多的持续增长的各种状态的CPU使用时间
2)过滤空闲CPU时间及总CPU时间
node_cpu_seconds_total{mode="idle"}:此时在prometheus的Console中输入执行结果各个CPU核在过滤后的持续增长的空闲CPU使用时间
node_cpu_seconds_total{}:此时在prometheus的Console中输入执行结果各个CPU核在过滤后的持续增长的总CPU使用时间
3)获取空闲CPU时间在一分钟内的增量及总CPU时间在一分钟内的增量
increase(node_cpu_seconds_total{mode="idle"}[1m]),此时在prometheus的Console中输入执行结果各个CPU核在过滤后的空闲使用时间在一分钟内的增量
increase(node_cpu_seconds_total{}[1m]),此时在prometheus的Console中输入执行结果各个CPU核在过滤后总的CPU使用时间在一分钟内的增量
4)将所有CPU核的CPU空闲时间在一分钟内的增量求和及所有CPU核总时间在一分钟内的增量求和
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])),此时在prometheus的Console中输入执行结果是所有被监控的服务器各个CPU核在过滤后的空闲CPU使用时间在一分钟内的增量的总和
sum(increase(node_cpu_seconds_total{}[1m])),此时在prometheus的Console中输入执行结果是所有被监控的服务器各个CPU核在过滤后总CPU使用时间在一分钟内的增量的总和
5)将求和后的空闲CPU使用时间和总CPU使用时间按服务器区分
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance),此时在prometheus的Console中输入执行结果是每个服务器的各个CPU核在过滤后的空闲CPU使用时间在一分钟内的增量的总和
sum(increase(node_cpu_seconds_total{}[1m])) by(instance),此时在prometheus的Console中输入执行结果是每个服务器的各个CPU核在过滤后总CPU使用时间在一分钟内的增量的总和
6)根据(1-idle/total)*100%公式,进行计算:
(1 - sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
(6).同理,求其他状态CPU使用率
us:(sum(increase(node_cpu_seconds_total{mode="user"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
sy:(sum(increase(node_cpu_seconds_total{mode="system"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
ni:(sum(increase(node_cpu_seconds_total{mode="nice"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
id:(sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
wa:(sum(increase(node_cpu_seconds_total{mode="iowait"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
hi:(sum(increase(node_cpu_seconds_total{mode="irq"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
si:(sum(increase(node_cpu_seconds_total{mode="softirq"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
st:(sum(increase(node_cpu_seconds_total{mode="steal"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
即,通过top命令查询到的cpu使用率:
(7).在生产环境中,一般70-80%以上的CPU使用率高是由于用户态userCPU高导致的。用户态CPU使用率更应用程序的运行密切相关,当服务器上运行大量进程并行处理任务,进程之间频繁上下页切换是,对用户态CPU消耗最大。
监控时,一般不单独列出user%的使用率,因为除去iowait造成的CPU高以及少数的system%内核态使用率高之外,大部分情况都是user%造成的。
很多情况下,当服务器硬盘IO占用过大时,CPU会等待IO的返回进入interuptable类型的CPU等待时间,所以CPU的iowait监控也是必要的。
user:(sum(increase(node_cpu_seconds_total{mode="user"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
iowait:(sum(increase(node_cpu_seconds_total{mode="iowait"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m])) by(instance)) * 100
CPU监控的阈值,设置在99%或100%:一般情况下,CPU使用率在80%-90%状态下的服务器仍然可以处理请求,但是速度会变慢;一旦CPU使用率在98%-100%,那么整个服务器几乎失去了可用性。(针对linux系统的优化非常重要,通过各种内核参数、软件参数来控制服务器,尽量不要让CPU堆到99%-100%)
Prometheus监控(1)
三丰,公众号:soft张三丰Prometheus监控(1)
Prometheus监控(2)
三丰,公众号:soft张三丰Prometheus监控(2)
Prometheus监控(3)
三丰,公众号:soft张三丰Prometheus监控(3)
Prometheus监控(4)
三丰,公众号:soft张三丰Prometheus监控(4)
分布式理论
三丰,公众号:soft张三丰分布式理论
微服务微信交流群添加微信,备注微服务进群交流

关注公众号 soft张三丰 

文章评论