1. 简介
Web Scraper是Chrome/Firefox浏览器插件,跨平台使用。
优点:使用简单,无需编程,鼠标点点就可;轻量快速爬取。
缺点:小数据量;不能爬图片;不能中止;整体较慢(网速影响可能不稳定);爬取结果乱序。
2. 基础
chrome应用商店安装插件需要科学上网,但凡用过chrome插件的都知道安装,这里不讲。
官方教程:https://www.webscraper.io/documentation
中文教程基础用法可看下面这个:
Web Scraper 使用教程(二)- 基本用法之安装、配置、运行
Web Scraper 使用教程(三)- 基本用法(常用选择器类型)
Web Scraper 使用教程(四)- 进阶用法(同一个页面爬取多个类型内容)
Web Scraper 使用教程(五)- 进阶用法(爬取向下滚动加载页面)
Web Scraper 使用教程(六)- 进阶用法(网址有规律变化进行翻页)
Web Scraper 使用教程(七)- 进阶用法(点击「翻页器」进行翻页)
Web Scraper 使用教程(八)- 进阶用法(点击「更多」进行翻页)
Web Scraper 使用教程(九)- 进阶用法(动态加载进行翻页)
Web Scraper 使用教程(十)- 爬取二级页面的内容
3. 实战
需求
例如,我想要爬取第一种业网中所有种子企业信息(http://www.a-seed.cn/index.php?m=content&c=search&catid=32&dosubmit=1)。
首页内容:
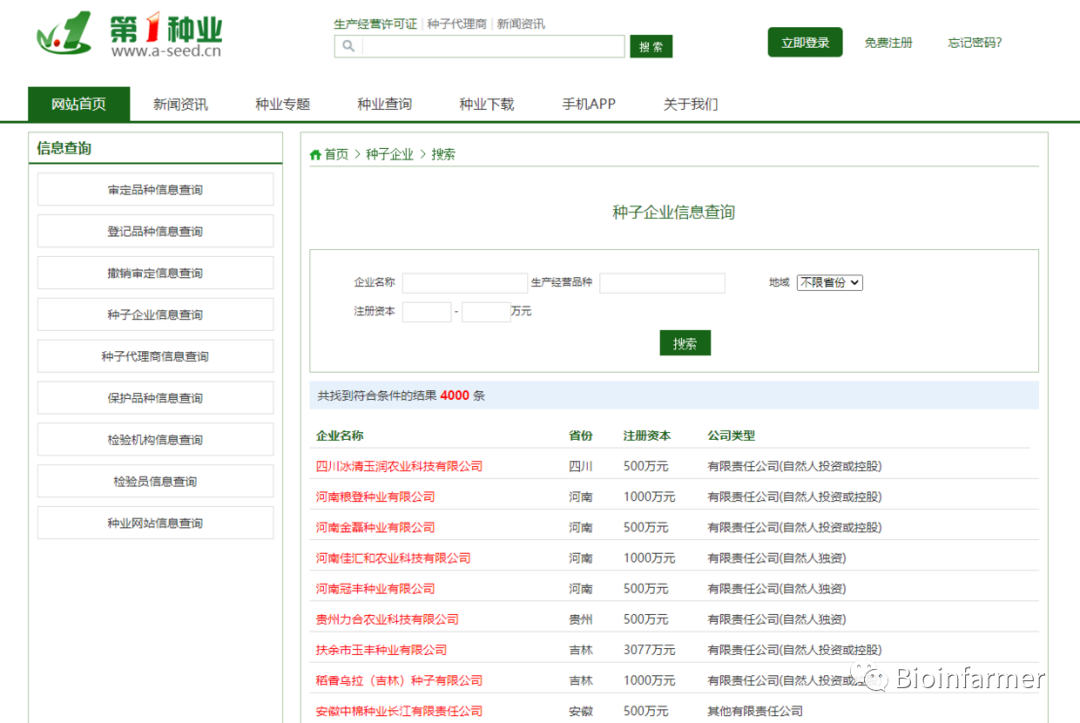
其中一个种子企业的信息:
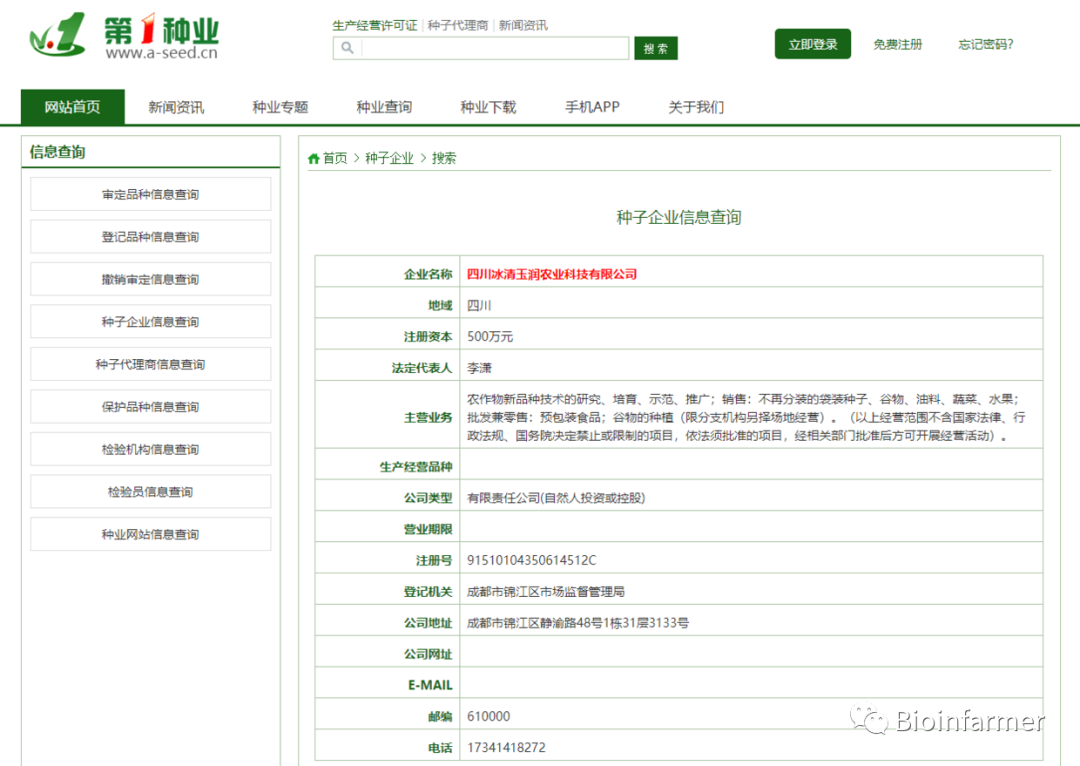
现在要把每个种子企业的全部信息(二级页面)爬取下来。
操作
-
查看翻页有连续规律。
-
ctrl+shift+i或者F12进入开发者模式。
-
对一级页面进行选择
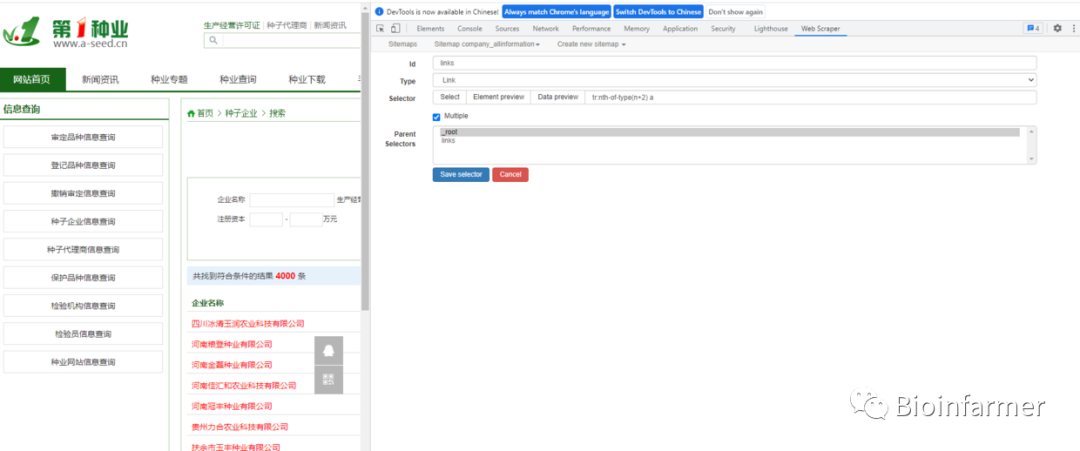
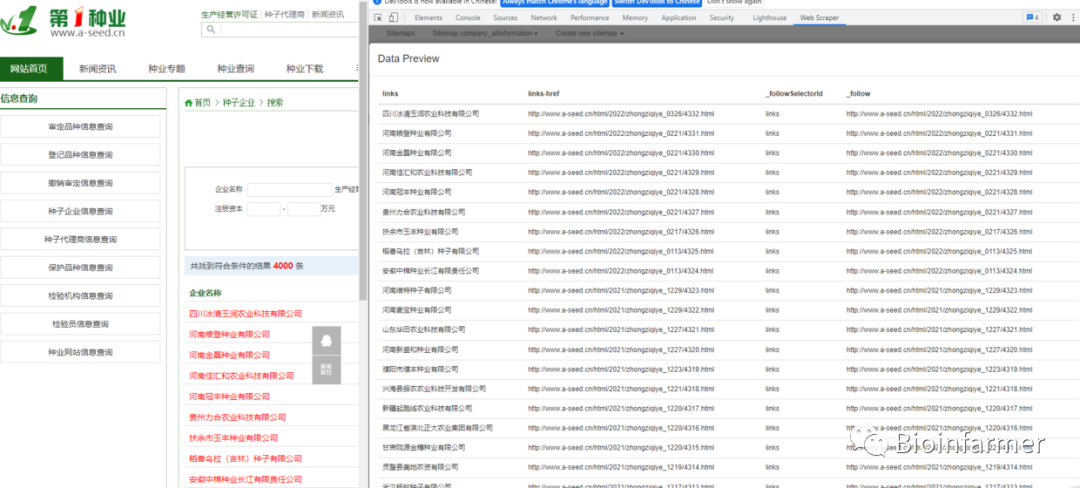
-
在二级页面下分别设置选择器
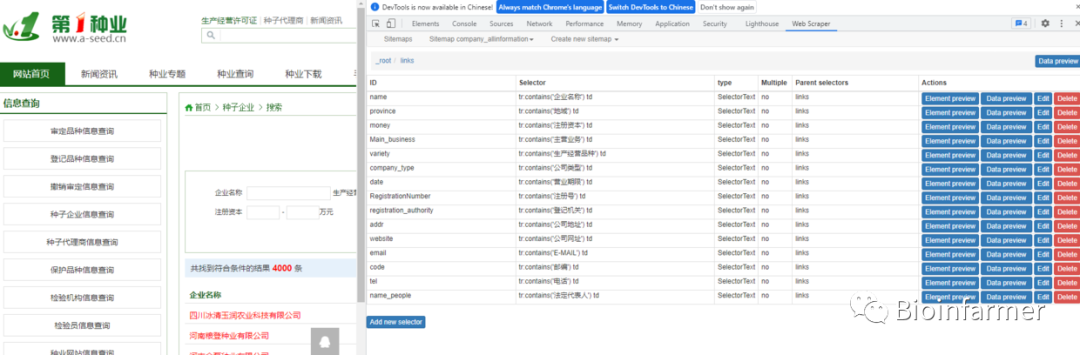
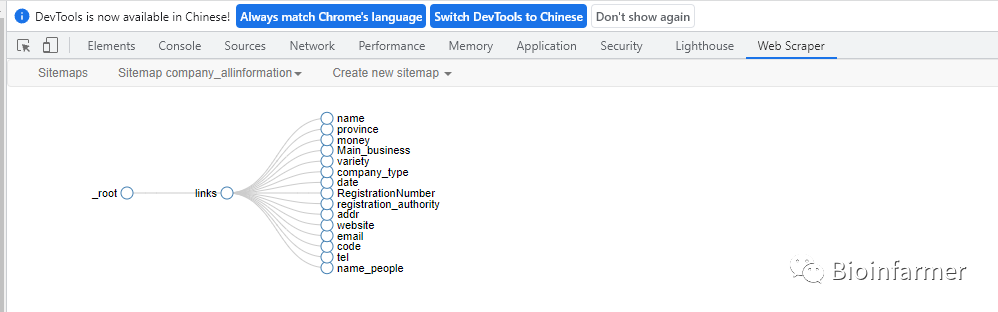
-
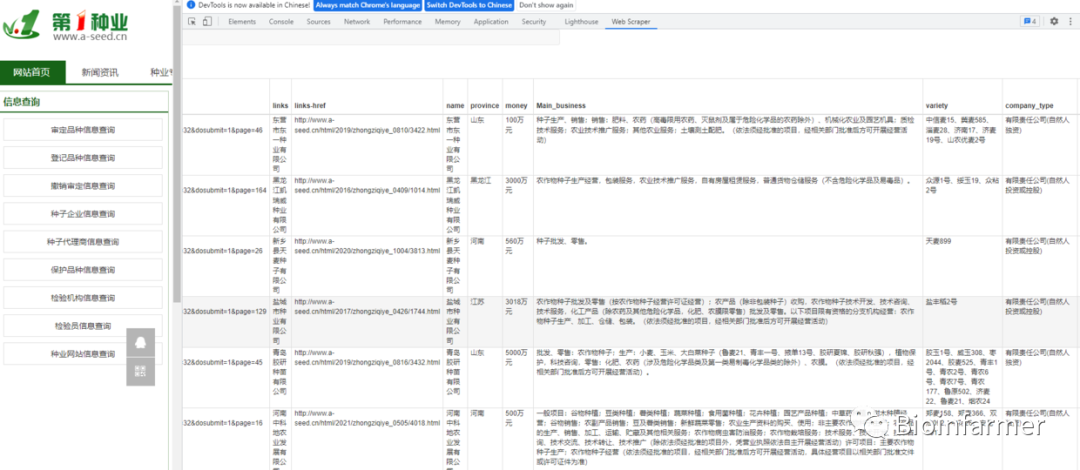
爬取结果(4000家种企信息,按2s一家,也要将近2个半小时才能爬取完,所以不适合大数据)
最后分享下此次爬取设置的sitemap,你可直接导入试试。
{"_id":"company_allinformation","startUrl":["http://www.a-seed.cn/index.php?info%5Btitle%5D=&info%5Bscjypz%5D=&info%5Bdiyu%5D=&info%5Bcatid%5D=32&zhucezb_start=&zhucezb_end=&m=content&c=search&a=init&catid=32&dosubmit=1&page=[1-200]"],"selectors":[{"id":"links","parentSelectors":["_root"],"type":"SelectorLink","selector":"tr:nth-of-type(n+2) a","multiple":true,"delay":0},{"id":"name","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('企业名称') td","multiple":false,"delay":0,"regex":""},{"id":"province","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('地域') td","multiple":false,"delay":0,"regex":""},{"id":"money","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('注册资本') td","multiple":false,"delay":0,"regex":""},{"id":"Main_business","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('主营业务') td","multiple":false,"delay":0,"regex":""},{"id":"variety","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('生产经营品种') td","multiple":false,"delay":0,"regex":""},{"id":"company_type","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('公司类型') td","multiple":false,"delay":0,"regex":""},{"id":"date","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('营业期限') td","multiple":false,"delay":0,"regex":""},{"id":"RegistrationNumber","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('注册号') td","multiple":false,"delay":0,"regex":""},{"id":"registration_authority","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('登记机关') td","multiple":false,"delay":0,"regex":""},{"id":"addr","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('公司地址') td","multiple":false,"delay":0,"regex":""},{"id":"website","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('公司网址') td","multiple":false,"delay":0,"regex":""},{"id":"email","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('E-MAIL') td","multiple":false,"delay":0,"regex":""},{"id":"code","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('邮编') td","multiple":false,"delay":0,"regex":""},{"id":"tel","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('电话') td","multiple":false,"delay":0,"regex":""},{"id":"name_people","parentSelectors":["links"],"type":"SelectorText","selector":"tr:contains('法定代表人') td","multiple":false,"delay":0,"regex":""}]}
4. 总结
很实用的小工具,小量的数据平时也不用写代码了。
忘了的话,看看基础的教程,点一点,十几分钟也能捡回来。要想进阶,慢慢尝试其他选项。
吐槽:微信真的是我用的体验感最差最差的产品了,我已经想放弃公众号了。不支持外来链接,图片上传是一个大问题。尤其是最近国内gitee的图床挂掉后,我转向github。但微信根本支持不了,各种限制,有什么意义呢?写个东西还要各种折腾,有这时间我不去弄点别的吗?

文章评论