简 介
熟悉深度学习的开发者对Papers with Code肯定不陌生,作为全球领先的开源机器学习资源平台,集成论文、代码、数据集等全方位资料。
每年Papers with Code都会和Medium(基于主题的高质量媒体平台)共同评选出十大年度趋势论文和仓库。在2021年,PaddleOCR通过PP-OCRv2、PP-Structure、多语言模型、《动手学OCR·十讲》等一系列重磅更新,上榜Top Trending Libraries of 2021!
详细链接查看:
https://medium.com/paperswithcode/papers-with-code-2021-a-year-in-review-de75d5a77b8b
近期,PaddleOCR团队梳理了近年来AAAI、CVPR、ACM等顶会的OCR方向重要论文,将数月的实验尝试一并放出,一次性新增8种OCR前沿算法(检测1种,识别3种,关键信息提取1种,视觉问答3种)。在Papers with Code 中Browse State-of-the-Art的Optical Character Recognition(文字识别)任务下,PaddleOCR也成为覆盖论文算法最多,Star排名第一(已经接近20000)的Github仓库!

详细链接查看:
https://paperswithcode.com/task/optical-character-recognition
本次更新覆盖了检测、识别、关键信息抽取、视觉问答4个方向,满足OCR在各个场景中的应用,是一次对模型库的全面升级!具体算法包括:
-
检测:PSENet[1]
-
识别:NRTR[2]、SEED[3]、SAR[4]
-
关键信息提取模型:SDMG-R[5]
-
文档视觉问答模型(DocVQA):LayoutLM[6]、LayoutLMv2[7]、LayoutXLM[8]
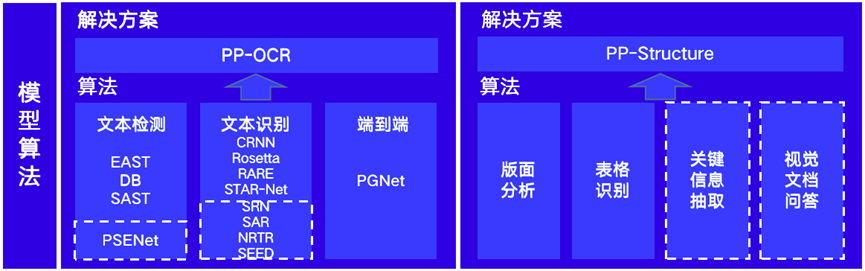
PaddleOCR模型全景图,白线虚线框为本次新增
下面我们就一起来看看这些模型的特色与使用场景吧!
算法介绍
丰富的检测识别模型库
文本识别模型:SAR
-
论文题目:
Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition
-
作者:Hui Li, Peng Wang等·发表会议:AAAI 2019
-
特色:针对不规则文本场景提出了 2D attention 模块对文本中的字符进行定位,不需要字符级别的标注,没有采用基于修正的策略,简化训练流程。有效提升了不规则文本的识别精度。
-
适用场景:在垂类场景中有部分弯曲文本的数据

SAR效果图
-
论文题目:
SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition
-
作者:Zhi Qiao, Yu Zhou等·发表会议:CVPR 2020
-
特色:核心的亮点是可插拔的语义模块。在模型训练过程中结合了语义信息去引导解码过程。并且该模块可在预测阶段去除掉,完全不影响预测速度和效率。在低质量的图片场景下有不错的提升效果。
-
适用场景:遮挡、模糊图片较多的垂类场景,利用语义信息进行词汇矫正

SEED效果图
文本识别模型:NRTR
-
论文题目:
NRTR: A No-Recurrence Sequence-to-Sequence Model For Scene Text Recognition
-
作者:Fenfen Sheng, Zhineng Chen等·发表会议:ICDAR 2019
-
特色:通过完整的Transformer结构对输入图片进行编码和解码,只使用了简单的几个卷积层做高层特征提取,在文本识别上验证了Transformer结构的有效性。
-
适用场景:需要利用Transformer结构的OCR场景
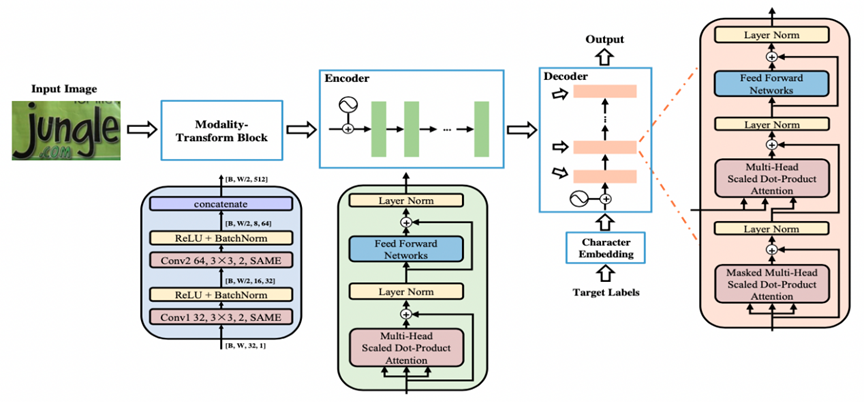
NRTR结构图
文本检测模型:PSENet
-
论文题目:
Shape Robust Text Detection with Progressive Scale Expansion Network
-
作者:Wenhai Wang, Enze Xie等·发表会议:CVPR 2019
-
特色:其提出的渐进式扩展算法通过从最小kernel逐步扩张到最大kernel,解决了分割算法对弯曲粘连文本的检测问题。
-
适用场景:各类规则和弯曲文本的检测场景

PSENet效果图
PP-Structure增加视觉文档问答能力
通用OCR能力提取了图片中的文字位置和文本内容,但有时除文本信息以外,我们还想了解文本框的类别、文本框之间的关系,这就转化为关键信息提取以及视觉文档问答任务。
关键信息提取即判断识别到的文本属于哪个类,例如对于一张身份证图片,模型不仅可以输出“张朋朋”的文本,也能将其分类为 ”姓名”。
视觉文档问答(DocVQA)主要针对文档图像的文字内容提出问题,例如一张身份证图片,问“公民身份号码是什么?”答案即为图片上的身份证号码。
DocVQA的具体实现方法通过SER(Semantic Entity Recognition,语义实体识别)与RE (Relation Extraction,关系抽取)两个子任务实现。通过SER将每个检测到的文本框分类为姓名、身份证号等,通过RE对每一个检测到的文本框分类为问题或答案。

SER与RE任务示例图
本次更新覆盖一个关键信息提取模型SDMG-R,以及三个视觉文档问答模型LayoutLM、LayoutLMv2、LayoutXLM,分别来看:
关键信息提取模型:SDMG-R
-
论文题目:
Spatial Dual-Modality GraphReasoning for Key Information Extraction
-
作者:Hongbin Sun, Zhanghui Kuang等
-
特色:提出了一种多模态图推理网络,同时使用文本特征、文本框特征以及文本框间的空间位置关系解决关键信息提取问题。SDMG-R相比较以往算法具有强大的鲁棒性和泛化性,适合实际生产使用。
-
适用场景:关键信息提取和分类

SDMG-R效果图
DocVQA:LayoutLM系列
-
论文题目:
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
-
作者: Yiheng Xu, Minghao Li等·发表会议:ACM 2020
-
特色:LayoutLM利用文本分布的板式信息和识别到的文字信息,基于bert进行大规模预训练,然后在SER和RE任务进行微调;LayoutLMv2在LayoutLM的基础上,将图像视觉信息引入预训练阶段,对多模态信息进行更好的融合;LayoutXLM将LayoutLMv2扩展到多语言。
-
适用场景:针对卡证、票据等场景的信息提取、关系抽取、文档视觉问答任务
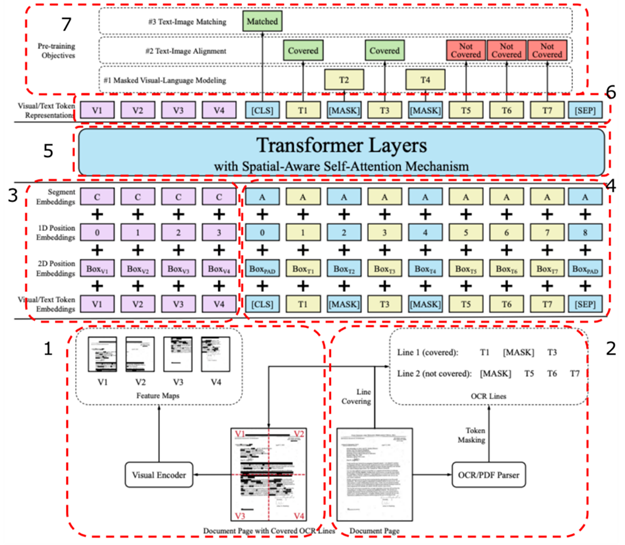
LayoutLMv2结构图
如何使用
对于上述模型的使用方法可以在Github首页文档中PP-Structure信息提取(DocVQA、关键信息抽取)与OCR学术圈(检测算法、识别算法)找到,模型训练微调同步支持。

而且对于这些模型的垂类数据训练、推理任务已经出现在社区常规赛。大家如果想对这些模型进一步加深理解与实践,参与社区常规赛的“学术前沿模型训练与推理”,不仅可以获得比赛的积分与奖励,优秀项目还可以获得开发者说直播、宣传推广的机会。

不忘初心
感谢广大开发者的支持
我们深知学术研究不易,PaddleOCR本次开源出的前沿学术模型,希望能够为OCR研究者提供方便的Baseline,同时还能结合飞桨面向产业落地的特质,快速将优秀的学术模型应用在生产生活中。我们也非常高兴的看到PP-OCR系列模型能够在各行各业的众多垂类场景中发光发热,帮助更多的企业开发者实现业务落地。也特别感谢广大开发者积极参与到PaddleOCR的项目建设中来,感谢大家!
PaddleOCR Contributor
?飞桨官网:
https://www.paddlepaddle.org.cn
?项目地址:
https://github.com/PaddlePaddle/PaddleOCR
?社区常规赛地址:
https://github.com/PaddlePaddle/PaddleOCR/issues/4982
往期精彩内容
微软再陷抄袭风波
首个支持苹果M1的Linux发行版来啦!
 觉得不错,请点个在看呀
觉得不错,请点个在看呀

文章评论