欢迎关注方志朋的博客,回复”666“获面试宝典

来源 | https://cloud.tencent.com/developer/article/1690227
Thanos[1] 和 VictoriaMetrics[2] 都是用来作为 Prometheus 长期存储的成熟方案,其中 VictoriaMetrics 也开源了其集群版本[3],功能更加强大。这两种解决方案都提供了以下功能:
-
长期存储,可以保留任意时间的监控数据。 -
对多个 Prometheus 实例采集的数据进行全局聚合查询。 -
可水平扩展。
本文就来对比一下这两种方案的差异性和优缺点,主要从写入和读取这两个方面来比较,每一个方面的比较都包含以下几个角度:
-
配置和操作的复杂度 -
可靠性和可用性 -
数据一致性 -
性能 -
可扩展性
先来看一下这两种方案的架构。
1. 架构
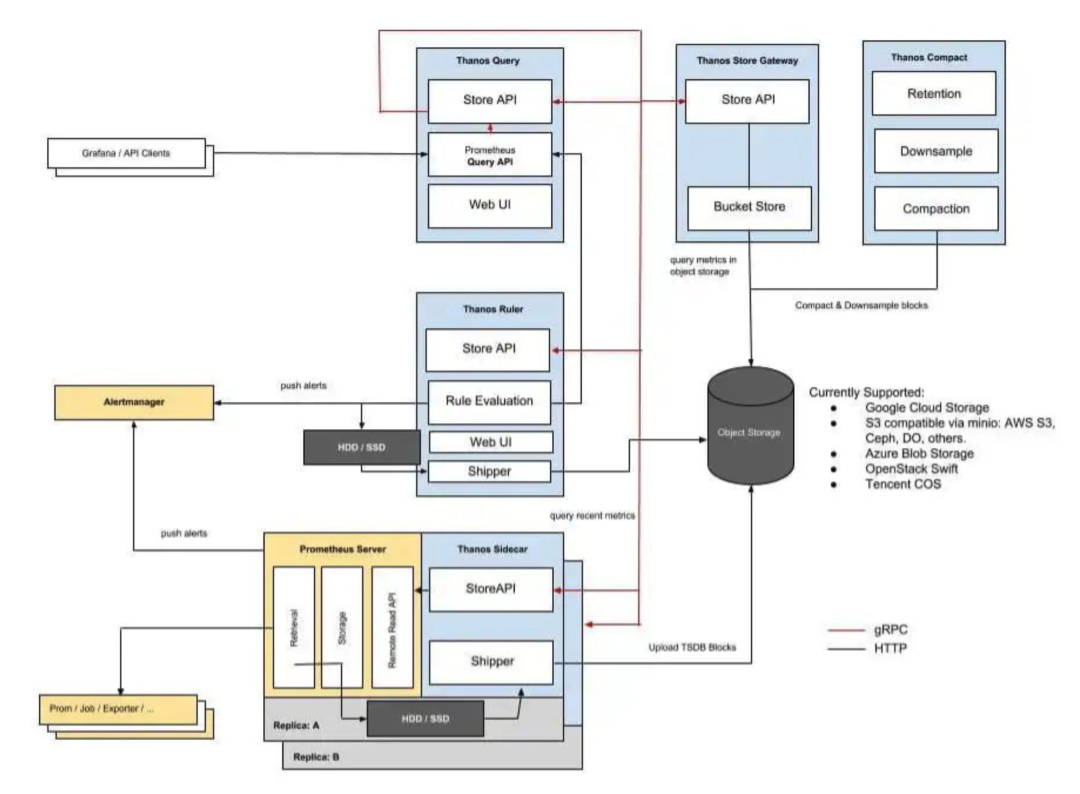
Thanos
Thanos[4] 包含以下几个核心组件:
-
Sidecar [5] : 每个 Prometheus 实例都包含一个 Sidecar,它与 Prometheus 实例运行在同一个 Pod 中。它有两个作用:1) 将本地超过 2 小时的监控数据上传到对象存储,如 Amazon S3 或 Google 云存储。2) 将本地监控数据(小于 2 小时)提供给 Thanos Query 查询。 -
Store[6] Gateway : 将对象存储的数据提供给 Thanos Query 查询。 -
Query[7] : 实现了 Prometheus 的查询 API[8],将 Sidecar 和对象存储提供的数据进行聚合最终返回给查询数据的客户端(如 Grafana)。 -
Compact[9] : 默认情况下,Sidecar 以 2 小时为单位将监控数据上传到对象存储中。 Compactor会逐渐将这些数据块合并成更大的数据块,以提高查询效率,减少所需的存储大小。 -
Ruler[10] : 通过查询 Query获取全局数据,然后对监控数据评估**记录规则[11]**和告警规则,决定是否发起告警。还可以根据规则配置计算新指标并存储,同时也通过 Store API 将数据暴露给Query,同样还可以将数据上传到对象存储以供长期保存。由于Query和底层组件的可靠性较低,Ruler 组件通常故障率较高[12]: Ruler 组件在架构上做了一些权衡取舍,强依赖查询的可靠性,这可能对大多数场景都不利。对于 Prometheus 来说,都是直接从本地读取告警规则和记录规则,所以不太可能出现失败的情况。而对于Ruler来说,规则的读取来源是分布式的,最有可能直接查询 Thanos Query,而 Thanos Query 是从远程 Store APIs 获取数据的,所以就有可能遇到查询失败的情况。 -
Receiver[13] : 这是一个实验性组件,适配了 Prometheus 的 remote write API,也就是所有 Prometheus 实例可以实时将数据 push 到 Receiver。在 Thanos v0.5.0 时,该组件还没有正式发布。
最后再来看一眼 Thanos 的整体架构图:
 img
img
VictoriaMetrics
VictoriaMetrics 集群版包含以下几个核心组件:
-
vmstorage : 存储数据。 -
vminsert : 通过 remote write API[14] 接收来自 Prometheus 的数据并将其分布在可用的 vmstorage节点上。 -
vmselect : 从 vmstorage节点获取并聚合所需数据,返回给查询数据的客户端(如 Grafana)。
每个组件可以使用最合适的硬件配置独立扩展到多个节点。
整体架构图如下:
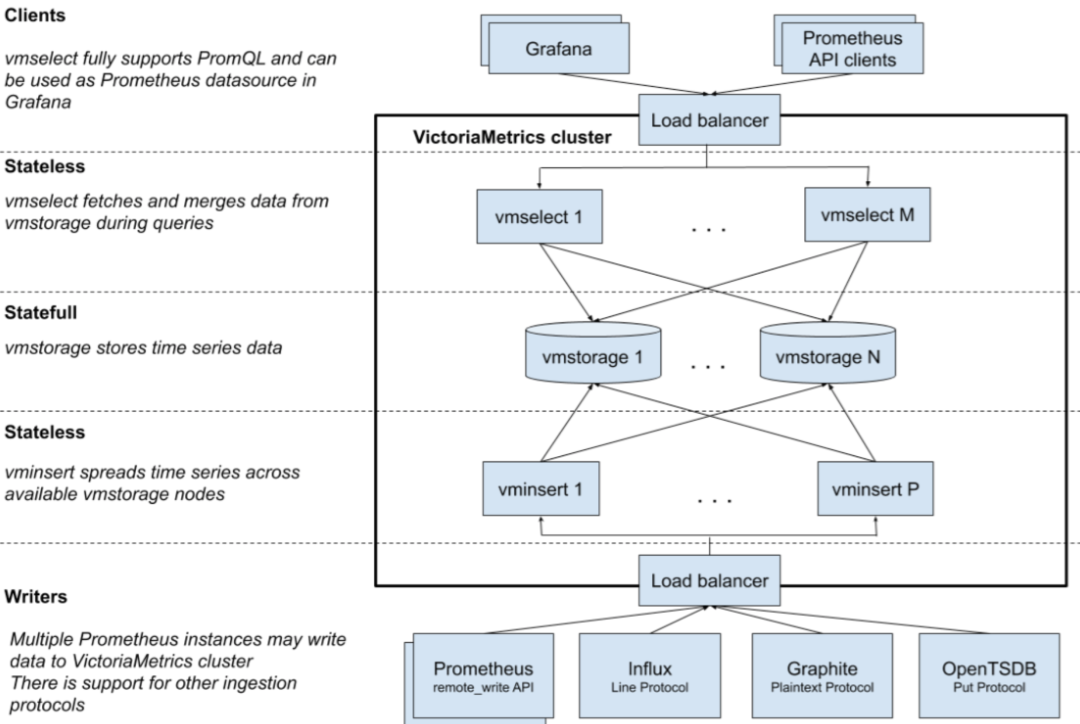
图中的 VictoriaMetrics 集群和 Load balancer 都可以通过 helm[15] 部署在 Kubernetes 中。对于大部分中小型集群来说,不需要水平扩展的功能,可以直接使用单机版的 VictoriaMetrics。更多信息请参考垂直扩展基准[16]。
了解这两种方案的架构后,开始进入对比环节。
注意:下文提到的
VictoriaMetrics如没有特殊说明,均指的是集群版。
2. 写入对比
配置和操作的复杂度
Thanos 需要通过以下步骤来建立写入过程:
-
禁用每个 Prometheus 实例的本地数据压缩。具体做法是将 --storage.tsdb.min-block-duration和--storage.tsdb.max-block-duration这两个参数的值设置为相同的值。Thanos 要求关闭压缩是因为 Prometheus 默认会以2,25,25*5的周期进行压缩,如果不关闭,可能会导致 Thanos 刚要上传一个 block,这个 block 却被压缩中,导致上传失败。更多详情请参考这个 issue[17]。如果--storage.tsdb.retainer.time参数的值远远高于 2 小时,禁用数据压缩可能会影响 Prometheus 的查询性能。 -
在所有的 Prometheus 实例中插入 Sidecar,这样Sidecar就可以将监控数据上传到对象存储。 -
设置 Sidecar 监控。 -
为每个对象存储的 bucket 配置压缩器,即 Compact[18] 组件。
VictoriaMetrics 需要在 Prometheus 中添加远程存储的配置[19],以将采集到的样本数据通过 Remote Write 的方式写入远程存储 VictoriaMetrics 中,不需要在 Prometheus 中插入 Sidecar,也不需要禁用本地数据压缩。详情请参考官方文档[20]。
可靠性和可用性
Thanos Sidecar 以 2 小时为单位将本地监控数据上传到分布式对象存储,这就意味着如果本地磁盘损坏或者数据被意外删除,就有可能会丢失每个 Prometheus 实例上最近 2 小时添加的数据。
从查询组件到 Sidecar 的查询可能会对 Sidecar 数据的上传产生负面影响,因为响应查询和上传的任务都是在同一个 Sidecar 进程中执行的。但理论上可以将负责响应查询的任务和上传的任务分别运行在不同的 Sidecar 中。
对于 VictoriaMetrics 来说,每个 Prometheus 实例都会实时通过 remote_write API 将所有监控数据复制到远程存储 VictoriaMetrics。在抓取数据和将数据写入远程存储之间可能会有几秒钟的延迟,所以如果本地磁盘损坏或者数据被意外删除,只会丢失每个 Prometheus 实例上最近几秒钟添加的数据。
从 Prometheus v2.8.0+ 开始,Prometheus 会直接从预写日志(WAL,write-ahead log)中复制数据到远程存储,所以不会因为与远程存储的临时连接错误或远程存储临时不可用而丢失数据。具体的原理是,如果与远程存储的连接出现问题,Prometheus 会自动停止在预写日志(WAL)的位置,并尝试重新发送失败的那一批样本数据,从而避免了数据丢失的风险。同时,由于出现问题时 Prometheus 不会继续往下读取预写日志(WAL),所以不会消耗更多的内存。
数据一致性
Thanos 的 Compactor 和 Store Gateway 存在竞争关系,可能会导致数据不一致或查询失败。例如:
-
如果 Thanos sidecar 或 compactor 在上传数据的过程中崩溃了,如何确保读取数据的客户端(如 Compactor 和 Store Gateway)都能够优雅地处理这个问题? -
分布式对象存储对于一个新上传的对象提供写后读写一致性(read-after-write consistency);对于已存在对象的复写提供最终读写一致性(eventual consistency)。举个例子,假设我们有一个崭新的文件,PUT 之后马上 GET ,OK,没有问题,这就是写后读写一致性;假设我们上传了一个文件,之后再 PUT 一个和这个文件的 key 一样,但是内容不同的新文件,之后再 GET。这个时候 GET 请求的结果很可能还是旧的文件。对于 Thanos compactor 来说,它会上传压缩的数据块,删除源数据块,那么在下一次同步迭代后,它可能会获取不到更新的数据块(最终读写一致性),从而又重新压缩了一次数据块并上传,出现数据重叠的现象。 -
对于 Store Gateway 来说,它每 3 分钟同步一次数据,查询组件可能会试图获取删除的源数据块,从而失败。
更多详情请参考 Read-Write coordination free operational contract for object storage[21]。
VictoriaMetrics 可以保持数据的强一致性,详情可参考它的存储架构[22]。
性能
Thanos 的写入性能不错,因为 Sidecar 只是将 Prometheus 创建的本地数据块上传到对象存储中。其中 Query 组件的重度查询可能会影响 Sidecar 数据上传的速度。对于 Compactor 组件来说,如果新上传的数据块超出了 Compactor 的性能,可能会对对象存储 bucket 带来不利。
而 VictoriaMetrics 使用的是远程存储的方式,Prometheus 会使用额外的 CPU 时间来将本地数据复制到远程存储,这与 Prometheus 执行的其他任务(如抓取数据、规则评估等)所消耗的 CPU 时间相比,可以忽略不计。同时,在远程存储数据接收端,VictoriaMetrics 可以按需分配合理的 CPU 时间,足以保障性能。参考 Measuring vertical scalability for time series databases in Google Cloud[23]。
可扩展性
Thanos Sidecar 在数据块上传过程中依赖于对象存储的可扩展性。S3 和 GCS 的扩展性都很强。
VictoriaMetrics 的扩展只需要增加 vminsert 和 vmstorage 的容量即可,容量的增加可以通过增加新的节点或者更换性能更强的硬件来实现。
3. 读取对比
配置和操作的复杂度
Thanos 需要通过以下步骤来建立读取过程:
-
Sidecar [24] 为每个 Prometheus 实例启用 Store API,以 将本地监控数据(小于 2 小时)提供给 Thanos Query查询。 -
Store[25] Gateway 将对象存储的数据暴露出来提供给 Thanos Query 查询。 -
Query[26] 组件的查询动作会覆盖到所有的 Sidecar和Store Gateway,以便利用 Prometheues 的查询 API[27] 实现全局查询。如果 Query 组件和 Sidecar 组件位于不同数据中心,在它们之间建立安全可靠连接可能会很困难。
VictoriaMetrics 提供了开箱即用的 Prometheues 查询 API[28],所以不需要在 VictoriaMetrics 集群外设置任何额外的组件。只需要将 Grafana 中的数据源指向 VictoriaMetrics[29] 即可。
可靠性和可用性
Thanos 的 Query 组件需要和所有的 Sidecar 和 Store Gateway 建立连接,从而为客户端(如 Grafana)的查询请求计算完整的数据。如果 Prometheus 实例跨多个数据中心,可能会严重影响查询的可靠性。
如果对象存储中存在容量很大的 bucket,Store Gateway 的启动时间会很长,因为它需要在启动前从 bucket 中加载所有元数据,详情可以参考这个 issue[30]。如果 Thanos 需要升级版本,这个问题带来的负面影响会非常明显。
VictoriaMetrics 的查询过程只涉及到集群内部的 vmselect 和 vmstorage 之间的本地连接,与 Thanos 相比,这种本地连接具有更高的可靠性和可用性。
VictoriaMetrics 所有组件的启动时间都很短,因此可以快速升级。
数据一致性
Thanos 默认情况下[31]允许在部分 Sidecar 或 Store Gateway 不可用时只返回部分查询结果[32]。
VictoriaMetrics 也可以在部分 vmstorage 节点不可用时只返回部分查询结果,从而优先考虑可用性而不是一致性。具体的做法是启用 -search.denyPartialResponse 选项。
总的来说,VictoriaMetrics 返回部分查询结果的可能性更低,因为它的可用性更高。
性能
Thanos Query 组件的查询性能取决于查询性能最差的 Sidecar 或 Store Gateway 组件,因为 Query 组件返回查询结果之前会等待所有 Sidecar 和 Store Gateway 组件的响应。
通常 Sidecar 或 Store Gateway 组件的查询性能不是均衡的,这取决于很多因素:
-
每个 Promnetheus 实例抓取的数据容量。 -
Store Gateway 背后每个对象存储 bucket的容量。 -
每个 Prometheus + Sidecar 和 Store Gateway 的硬件配置。 -
Query组件和 Sidecar 或 Store Gateway 之间的网络延迟。如果Query和 Sidecar 位于不同的数据中心,延迟可能会相当高。 -
对象存储的操作延迟。通常对象存储延迟( S3、GCS)比块存储延迟(GCE磁盘、EBS)高得多。
VictoriaMetrics 的查询性能受到 vmselect 和 vmstorage 的实例数量及其资源配额的限制。只需增加实例数,或者分配更多的资源配额,即可扩展查询性能。vminsert 会将 Prometheus 写入的数据均匀地分布到可用的 vmstorage 实例中,所以 vmstorage 的性能是均衡的。VictoriaMetrics 针对查询速度做了优化[33],所以与 Thanos 相比,它应该会提供更好的查询性能。
可扩展性
Thanos 的 Query 组件是无状态服务,可用通过水平扩展来分担查询负载。Store Gateway 也支持多副本水平扩展,对每一个对象存储 bucket 而言,多个 Store Gateway 副本也可以分担查询负载。但是要扩展 Sidecar 后面的单个 Prometheus 实例的性能是相当困难的,所以 Thanos 的查询性能受到性能最差的 Prometheus + Sidecar 的限制。
VictoriaMetrics 在查询方面提供了更好的扩展性,因为 vmselect 和 vmstorage 组件的实例可以独立扩展到任何数量。集群内的网络带宽可能会成为限制扩展性的因素,VictoriaMetrics 针对低网络带宽的使用进行了优化,以减少这一限制因素。
4. 高可用对比
Thanos 需要在不同的数据中心(或可用区)运行多个 Query 组件,如果某个区域不可用,那么另一个区域的 Query 组件将会继续负责响应查询。当然,这种情况下基本上只能返回部分查询结果,因为部分 Sidecar 或 Store Gateway 组件很有可能就位于不可用区。
VictoriaMetrics 可以在不同的数据中心(或可用区)运行多个集群,同时可以配置 Prometheus 将数据复制到所有集群,具体可以参考官方文档的示例[34]。如果某个区域不可用,那么另一个区域的 VictoriaMetrics 仍然继续接收新数据,并能返回所有的查询结果。
5. 托管成本对比
Thanos 选择将数据存放到对象存储中,最常用的 GCS 和 S3 的每月计费情况如下:
-
GCS : 价格区间位于 4/TB的coldlinestorage和36/TB 的标准存储之间。此外,对于出口网络:内部流量 10/TB,外部流量80- -
S3 : 价格区间位于 4/TB的glacierstorage和23/TB 的标准存储之间。此外,对于出口网络:内部流量 2−10/TB,外部流量 50−90/TB。对于存储 API 的调用(读写):每百万次调用 100。具体参考价格详情[36]。
总体看下来,Thanos 的托管成本不仅取决于数据大小,还取决于出口流量和 API 调用的数量。
VictoriaMetrics 只需要将数据存放到块存储,最常用的 GCE 和 EBS 的每月计费情况如下:
-
GCE 磁盘 : 价格区间位于 40/TB的HDD和240/TB 的 SSD。具体参考价格详情[37]。 -
EBS : 价格区间位于 45/TB的HDD和125/TB 的 SSD。具体参考价格详情[38]。
VictoriaMetrics 针对 HDD 做了优化,所以基本上没必要使用昂贵的 SSD。VictoriaMetrics 采用高性能的数据压缩方式,使存入存储的数据量比 Thanos 多达 10x,详情参考这篇文章[39]。这就意味着与 Thanos 相比,VictoriaMetrics 需要更少的磁盘空间,存储相同容量数据的成本更低。
总结
Thanos 和 VictoriaMetrics 分别使用了不同的方法来提供长期存储、聚合查询和水平扩展性。
-
VictoriaMetrics 通过标准的 remote_write API[40] 接收来自 Prometheus 实例写入的数据,然后将其持久化(如 GCE HDD 磁盘[41]、Amazon EBS[42] 或其他磁盘)。而 Thanos 则需要禁用每个 Prometheus 实例的本地数据压缩,并使用非标准的 Sidecar将数据上传至S3或GCS。同时还需要设置Compactor,用于将对象存储 bucket 上的小数据块合并成大数据块。 -
VictoriaMetrics 开箱即实现了全局查询视图的 Prometheus query API[43]。由于 Prometheus 会实时将抓取到的数据复制到远程存储,所以它不需要在集群外建立任何外部连接来实现全局查询。Thanos 需要设置 Store Gateway、SIdecar和Query组件才能实现全局查询。对于大型的 Thanos 集群来说,在Query组件和位于不同数据中心(可用区域)的Sidecar之间提供可靠安全的连接是相当困难的。Query组件的性能会受到性能最差的Sidecar或Store Gateway的影响。 -
VictoriaMetrics 集群可以快速部署到 Kubernetes 中,因为它的架构非常简单[44]。而 Thanos 在 Kubernetes 中的部署和配置非常复杂。
本文由 VictoriaMetrics 核心开发者所著,所以可能会更倾向于 VictoriaMetrics,但作者尽量做到了公平对比。如果你有任何疑问,欢迎找原作者交流(si bi)。
原文链接:https://medium.com/faun/comparing-thanos-to-victoriametrics-cluster-b193bea1683
参考资料
[1]Thanos: https://github.com/improbable-eng/thanos
[2]VictoriaMetrics: https://github.com/VictoriaMetrics/VictoriaMetrics
[3]集群版本: https://github.com/VictoriaMetrics/VictoriaMetrics/tree/cluster
[4]Thanos: https://github.com/improbable-eng/thanos
[5]Sidecar : https://thanos.io/tip/components/sidecar/
[6]Store: https://thanos.io/tip/components/store/
[7]Query: https://thanos.io/tip/components/query/
[8]Prometheus 的查询 API: https://prometheus.io/docs/prometheus/latest/querying/api/
[9]Compact: https://thanos.io/tip/components/compact/
[10]Ruler: https://thanos.io/tip/components/rule/
[11]记录规则: https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/
[12]Ruler 组件通常故障率较高: https://thanos.io/tip/components/rule/#risk
[13]Receiver: https://thanos.io/proposals/201812_thanos-remote-receive/
[14]remote write API: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
[15]helm: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/cluster/README.md#helm
[16]垂直扩展基准: https://medium.com/@valyala/measuring-vertical-scalability-for-time-series-databases-in-google-cloud-92550d78d8ae
[17]这个 issue: https://github.com/improbable-eng/thanos/issues/206
[18]Compact: https://thanos.io/tip/components/compact/
[19]远程存储的配置: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
[20]官方文档: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/README.md#prometheus-setup
[21]Read-Write coordination free operational contract for object storage: https://thanos.io/tip/proposals/201901-read-write-operations-bucket/
[22]存储架构: https://medium.com/@valyala/how-victoriametrics-makes-instant-snapshots-for-multi-terabyte-time-series-data-e1f3fb0e0282
[23]Measuring vertical scalability for time series databases in Google Cloud: https://medium.com/@valyala/measuring-vertical-scalability-for-time-series-databases-in-google-cloud-92550d78d8ae
[24]Sidecar : https://thanos.io/tip/components/sidecar/
[25]Store: https://thanos.io/tip/components/store/
[26]Query: https://thanos.io/tip/components/query/
[27]Prometheues 的查询 API: https://prometheus.io/docs/prometheus/latest/querying/api/
[28]Prometheues 查询 API: https://prometheus.io/docs/prometheus/latest/querying/api/
[29]将 Grafana 中的数据源指向 VictoriaMetrics: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/README.md#grafana-setup
[30]这个 issue: https://github.com/improbable-eng/thanos/issues/814
[31]默认情况下: https://github.com/improbable-eng/thanos/blob/37f89adfd678c0e263a136da34aafe213e88bc24/cmd/thanos/query.go#L93
[32]只返回部分查询结果: https://thanos.io/tip/components/query/#partial-response
[33]VictoriaMetrics 针对查询速度做了优化: https://medium.com/@valyala/measuring-vertical-scalability-for-time-series-databases-in-google-cloud-92550d78d8ae
[34]官方文档的示例: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/README.md#high-availability
[35]价格详情: https://cloud.google.com/storage/pricing
[36]价格详情: https://aws.amazon.com/s3/pricing/
[37]价格详情: https://cloud.google.com/compute/pricing#persistentdisk
[38]价格详情: https://aws.amazon.com/ebs/pricing/
[39]这篇文章: https://medium.com/faun/victoriametrics-achieving-better-compression-for-time-series-data-than-gorilla-317bc1f95932
[40]remote_write API: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
[41]GCE HDD 磁盘: https://cloud.google.com/compute/docs/disks/#pdspecs
[42]Amazon EBS: https://aws.amazon.com/ebs/
[43]Prometheus query API: https://prometheus.io/docs/prometheus/latest/querying/api/
[44]架构非常简单: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/cluster/README.md#architecture-overview
热门内容:
Docker 大势已去,Podman 即将崛起 我同事说我写代码像写诗 Maven官宣:干掉Maven和Gradle!推出更强更快更牛逼的新一代构建工具,炸裂! 面试官问:生成订单30分钟未支付,则自动取消,该怎么实现? 使用雪花id或uuid作为Mysql主键,被老板怼了一顿!
最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。 明天见(。・ω・。)ノ♡

文章评论