在推荐系统无所不在的网络环境中,用户越来越强烈地意识到自己的数据是需要保密的。因此,能够实现隐私保护的推荐系统的研究与发展越来越重要。联邦学习框架的引入为这一问题提供了解决方案。
随着互联网覆盖范围的扩大,越来越多的用户习惯于在网上消费各种形式的内容,推荐系统应运而生。推荐系统在我们的日常生活中无处不在,它们非常有用,既可以节省时间,又可以帮助我们发现与我们的兴趣相关的东西。目前,推荐系统是消费领域最常见的机器学习算法之一[1]。以网络新闻为例,由于每天都有大量的新闻文章发布在网上,在线新闻服务的用户面临着严重的信息过载。不同的用户通常喜欢不同的新闻信息。因此,个性化新闻推荐技术被广泛应用于用户的个性化新闻展示和服务中。关于新闻的推荐算法 / 模型研究已经引起了学术界和产业界的广泛关注。
经典的推荐算法大致分为三类:内容过滤(Content filtering)、协同过滤(Collaborative filtering,CF)和混合过滤(Hybrid filtering)。
内容过滤:这类算法侧重于通过将用户、item 划分为特定的信息特征来绘制用户肖像,从而直接建立对用户兴趣的理解。初期的推荐系统中多采用的是内容过滤的方法。例如,我在某宝上浏览了几件黑色女式羽绒服,系统根据内容过滤算法直接提取 “黑色”、“羽绒服”、“女式” 等 item 特征,在这个应用场景下,item 具体为 “物品”。通过对物品进行多次关联性分析,发现我多次在某宝中的点击之间的关联性,从而生成推荐结果,将“女式羽绒服” 推荐到我的某宝首页中。这种内容过滤的方法具有以下特点:一是,方法原理简单、易于实现,直接根据用户点击的数据进行分析,因此不存在稀疏性和冷启动的问题。二是,直接基于 item 进行特征构建和推荐,推荐准确度过高,且不受其它用户热门推荐的影响。三是,所依赖的 item、特征等直接影响了推荐效果,必须保证特征准确且在具体的应用场景中是真实有效的。四是,推荐结果存在重复性问题。以新闻推荐类应用为例,你浏览了一篇关于 2021 年考研的权威发布新闻,系统可能再次向你推送的是同一条新闻。
协同过滤:这些算法在没有用户或 item 的先验信息的情况下工作,并且只根据用户的交互数据建立对用户兴趣的理解。这种方法也是目前应用最广泛的推荐算法。协同过滤的基本考虑是“物以类聚,人以群分”。协同过滤主要有两类方法:基于用户 (User-based) 的推荐和基于 item(Item-based)的推荐。协同过滤一般与评分系统结合使用,通过分数去刻画用户对于 item 的喜好程度。协同过滤的方法具有以下特点:一是,无需建模,且领域无关,具有很好的普适性。二是,便于借鉴他人经验,能够使用其它评分结果辅助发现用户的潜在兴趣偏好。三是,基于历史数据进行评分和评估,因此对于系统中的新用户和新 item 存在冷启动问题,且受历史数据的数据规模、稀疏程度等影响较大。四是,对用户的新爱好转变或特殊爱好的需求支持度较差,这些新爱好或特殊爱好一般也是缺少历史数据支持的情况。
混合过滤:这些算法是上述两种算法的结合。它通过利用上面两种方法中的技术优势来构建更好的推荐系统。
然而,在推荐系统无所不在的网络环境中,用户越来越强烈的意识到自己的数据是需要保密的。此外,从政府层面看,随着 GDPR 在欧洲的启动和美国类似法律的出台,越来越多的国家将效仿这一做法,进一步导致传统的推荐系统所依赖的训练数据越来越匮乏。在这样的背景下,能够实现隐私保护的推荐系统的研究与发展越来越重要。从另外一个角度分析,在推荐 / 搜索中引入隐私也有一定的好处。我们可以利用用户不共享的更好的元数据进行推荐系统的训练,例如手机上的应用程序信息、位置等。我们还可以在较新的领域中(如医疗保健、金融服务)更好地采用机器学习模型,用户不再需要犹豫是否将数据共享给其他人。
联邦学习将模型的学习过程分发给各个客户端(即用户的设备),使得从特定于用户的本地模型中训练出全局模型成为可能,确保用户的私有数据永远不会离开客户端设备,从而实现了对用户隐私性的保护。将联邦学习框架引入到推荐系统问题中,能够实现隐私保护的推荐系统。
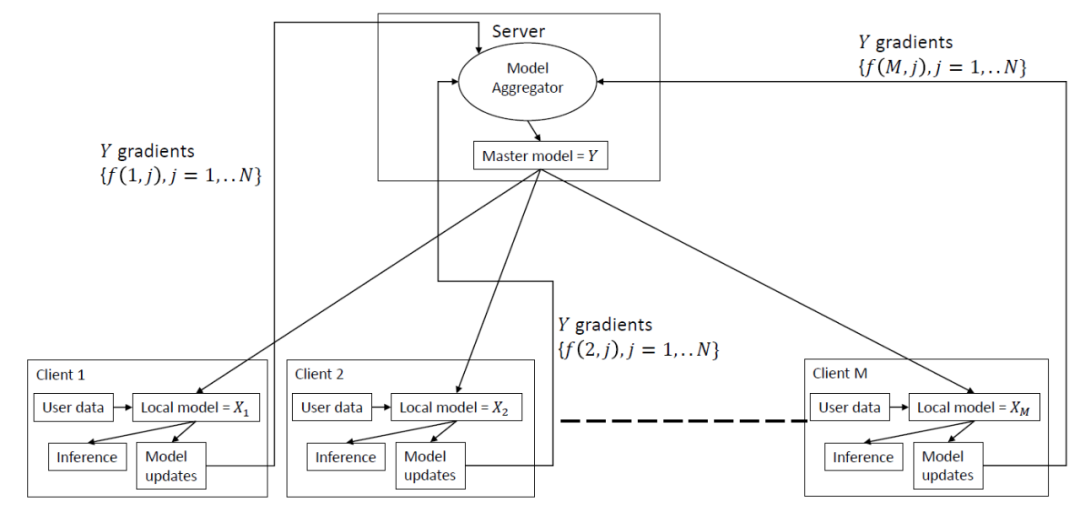
来自华为 Finland R&D Center 的研究人员首次提出了联邦协同过滤方法(Federated Collaborative Filter ,FCF)[2] ,该方法聚合用户特定的梯度更新模型权重来更新全局模型。具体地说,作者提出了一种联邦学习框架下的用于隐式反馈数据集的 CF 方法。同时,这种方法是可推广的,可以扩展到各种推荐系统应用场景中。FCF 的完整框架如图 1。在中央服务器上更新主模型 Y(item 因子矩阵),然后将其分发到各个客户端中。每个特定于用户的模型 X(用户因子矩阵)保留在本地客户端中,并使用本地用户数据和来自中央服务器的 Y 在客户端上更新。在每个客户端上计算通过计算 Y 的梯度得到更新并将更新传输到中央服务器中,在那里将这些更新聚合以进一步更新全局模型 Y。

首先,经典 CF 模型是由低维潜在因子矩阵 X 和 Y 的线性组合表示的:
(1)
其中,其中 r_ui 表示用户 u 和 item i 之间的交互。r_ui 通常表示显式反馈,例如用户直接给出的评级结果 r_ui。r_ui 也可以表示隐式反馈,例如用户观看了视频,或者从网上商店购买了一件商品,或者任何类似的行为。本文主要考虑隐式反馈的情况,对于 r_ui 的预测可以表示为:
(2)
在隐式反馈场景中引入一组二进制变量 p_ui,以表征用户 u 对 item i 的偏好,其中:
(3)
在隐式反馈情况下,值 r_ui=0 可以有多种解释,例如用户 u 对 item i 不感兴趣,或者用户 u 可能不知道 item i 的存在等等。为了解决这种不确定性,本文引入一个置信参数如下:
(4)
其中,α>0。基于的本人引入置信参数 c_ui,对所有的用户 u 和 item i 进行优化的代价函数如下所示:
(5)
其中,λ为正则化参数。代价函数的第一项为预测结果与置信参数的偏差,第二项为正则化处理项。J 相对于 x_u 和 y_i 的微分由下式得出:
(6)
(7)
在用户因子的每次更新迭代中,中央服务器将最新的 item 因子向量 y_i 发送到每个客户端。用户基于自己的本地数据 r_ui 分别用公式(3)和公式(4)计算 p(u)和 C^u。然后,在每个客户端使用公式(7)更新 x_ u 得到(x_ u)*。可以针对每个用户 u 独立地更新,而不需要参考任何其他用户的数据。
优化公式(5)中的代价函数,可以得到 y_i 的最优估计:
(8)
(9)
由公式(9),为了得到 (y_i)*,需要知道用户因子向量 x_i 和用户与 item 交互的相关信息 C^u、p(u) 值。因此,item 因子 y_i 的更新不能在客户端上完成,必须在中央服务器中进行。然而,从用户隐私保护的角度出发,用户 - item 交互信息应当仅保留在客户端设备中,因此,不能直接使用公式(9)计算 y_i。为了解决这一问题,本文提出了一种随机梯度下降方法,允许在中央服务器中更新 y_i,同时保护用户的隐私。具体的,使用下式在中央服务器更新 y_i:
(10)
其中,使用公式(8)确定增益参数γ和∂J/∂(y_i)。然而,公式(8)包含一个分量,它是所有用户 u 的总和。因此,将 f(u,i)定义为:
(11)
其中 f(u,i)是在每个客户端 u 上独立于所有其他客户端计算的。然后,所有客户端向中央服务器发送梯度值 f(u,i)。将公式(8)重写为客户端梯度的聚合,并在中央服务器进行如下计算:
(12)
最后,利用公式(12)中的特定于 item 的梯度进行更新,然后使用公式(10)在中央服务器上更新 y_i。当使用梯度下降法更新 Y 时,需要多次迭代梯度下降更新以达到 Y 的最优值。因此,FCF 的一次 epoch 包括更新到 CF 中的 X,然后用几次梯度下降步骤来更新 Y。
本文的隐私保护联邦学习方案不需要在中央服务器上知道用户的身份。这主要是因为每个用户只需向中央服务器发送 f(u,i)的更新,利用公式(12)聚合这些更新,在此过程中无需参考用户的身份。
作者评估了 CF 和 FCF 的推荐性能,分别计算前 10 个推荐结果的标准评估指标(the standard evaluation metrics)、精度(Precision),召回率(Recall),F1,平均平均精度(MAP)和均方根误差(RMSE)。此外,还计算了 FCF 和 CF 的性能指标之间的 “diff%” 如下:
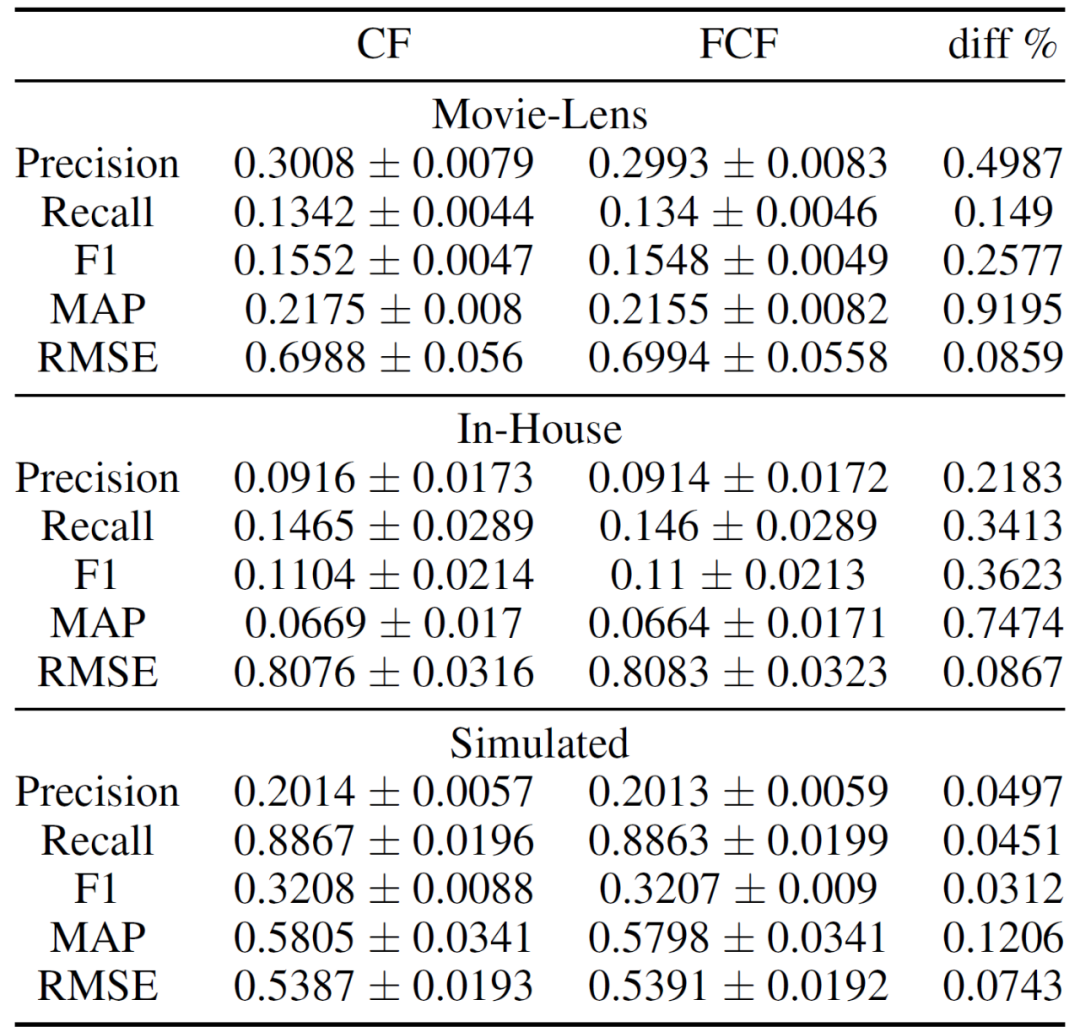
表 1 给出了两个真实数据集和模拟数据集在 10 轮模型重建实验中用户平均的测试集性能指标。其中,真实数据集分别为 The MovieLens rating datasets 和 In-house Production Dataset。模拟数据集是通过随机模拟用户、电影和浏览活动生成的。具体来说,创建一个由 0 和 1 组成的用户 - item 交互矩阵。其中 80% 的数据是稀疏的,附加的约束条件是每个用户至少有 8 个浏览活动,并且每个 item 至少被观察一次。在表 1 实验的模型构建过程中,每个用户的数据被随机分为 60% 的训练、20% 的验证和 20% 的测试集。使用验证集和训练集来寻找最优的超参数和学习模型参数,测试集则是用来预测推荐和评估在未知用户数据上的性能分数。结果表明,FCF 和 CF 模型的结果在测试集推荐性能指标方面非常相似。平均而言,五个指标中任何一个指标的 diff% CF 和 FCF 小于 0.5%。标准差 std 也很小,表明多次运行后能够收敛到稳定和可接受的解决方案中。
表 1. 使用所有用户的平均值比较协同过滤器(CF)和联邦协同过滤器(FCF)之间的测试集性能指标。这些值表示 10 个不同模型构建的平均标准差。diff% 指 CF 和 FCF 平均值之间的百分比差。
本文是使用联邦学习框架实现隐私保护推荐系统的第一次尝试,是基于 CF 的推荐系统实现的。在这篇文章中,作者表示将会继续探索基于模拟器的对真实世界场景的分析,以持续异步的方式(在线学习)从客户端收集更新。此外,对通信有效载荷和通信效率的分析有助于评估此类系统在实际场景中的应用效果。最后作者计划进一步通过结合安全联邦学习方法来研究攻击和威胁对推荐系统的影响。
由第二节中的介绍可知,FCF 实现了联邦学习框架下的推荐系统,解决了推荐系统中的用户隐私保护问题,同时 FCF 与经典 CF 的推荐性能相差不大。但是,FCF 也存在一些问题,FCF 要求所有用户都参与到联邦学习的过程中来训练他们的向量,这在现实世界的推荐场景中是不实际的,一些用户受限于设备、网络性能等,无法进行模型训练。此外,FCF 使用 item 的 ID 来表示 item,这就要求预先对需要处理的 item 进行编号,而没有进行编号的新 item 就无法处理了。但是我们知道,在真正的推荐系统应用场景中,大量的新 item、新知识都是实时刷新推送的,这种强制预知的方式在实际问题中是不适用的。
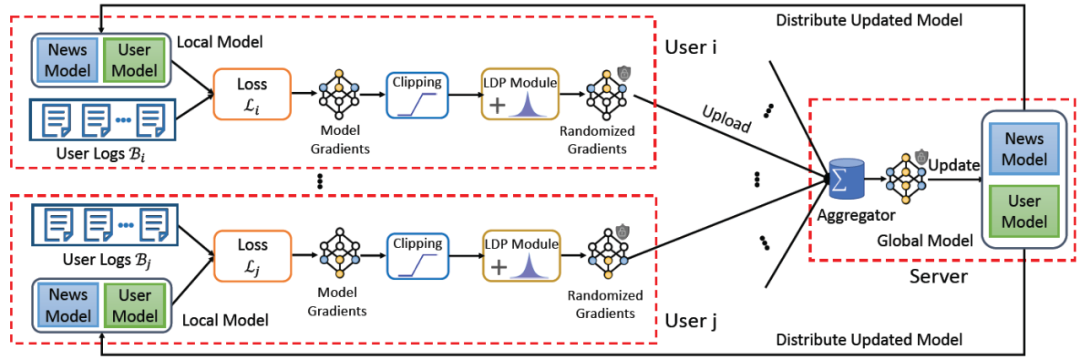
在论文《Privacy-Preserving News Recommendation Model Learning》[3]中,来自清华和微软研究院的研究人员针对新闻推荐问题对 FCF 进行了改进,具体提出了一种隐私保护方法(Fed-NewsRec),利用海量用户的行为数据,训练出准确的新闻推荐模型。此外,提出应用局部差分隐私来保护用户客户端设备和中央服务器之间通信的局部梯度中的私有信息。Fed-NewsRec 的完整结果见图 2。在 Fed-NewsRec 框架中,新闻平台(网站或应用程序)上的用户行为存储在用户的本地设备中,而不需要上传到服务器中。另外,提供新闻服务的服务器不记录也不收集用户的行为,这可以减轻用户的隐私顾虑和减少数据泄露的风险。
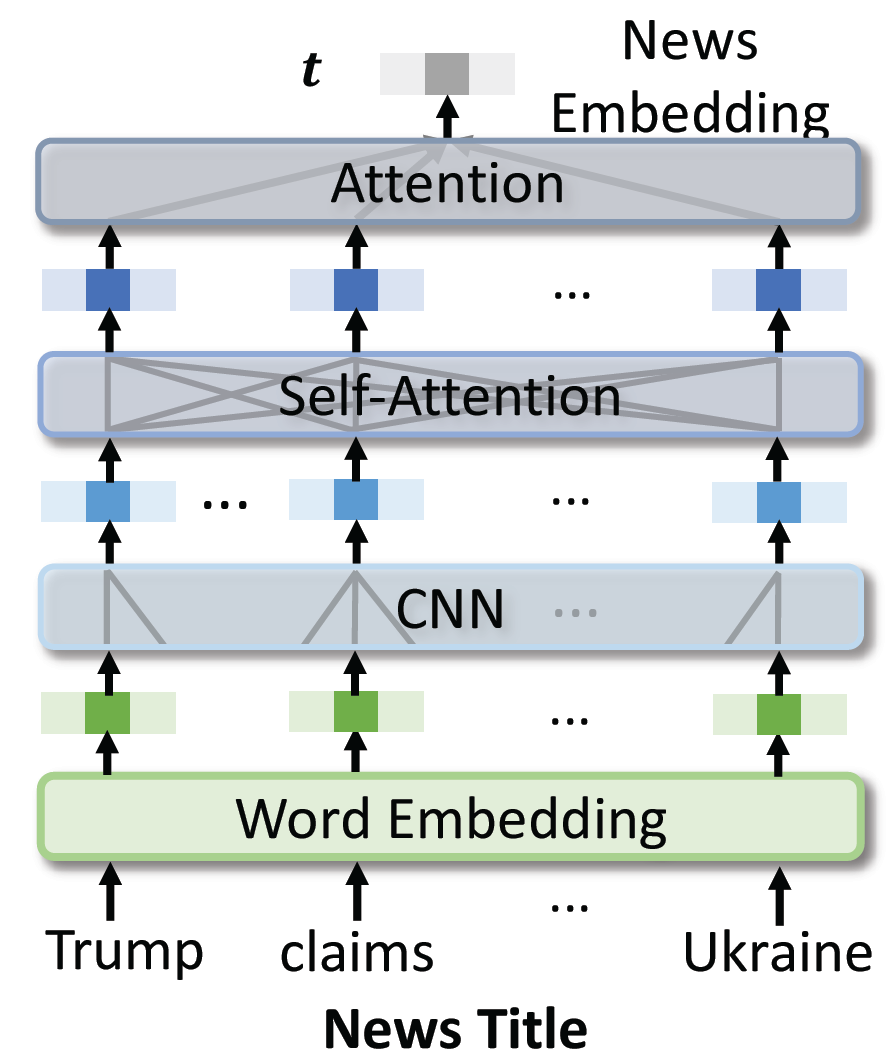
在 Fed-NewsRec 中,沿用经典新闻推荐模型中的新闻模型。新闻模型的目的是学习新闻表征,从而对新闻内容进行建模,其结构如图 3。新闻模型从下到上一共四层。第一层是词嵌入,它将新闻标题中的词序转换成语义嵌入向量序列。第二层是一个 CNN 网络,它通过捕捉本地上下文来学习单词表示。第三层是一个多头自注意力网络,它可以通过模拟不同单词之间的长期关系来学习上下文单词的表示。第四层是注意力网络,它通过选择信息词,从多头自注意力网络的输出中构建新闻表征向量 t。
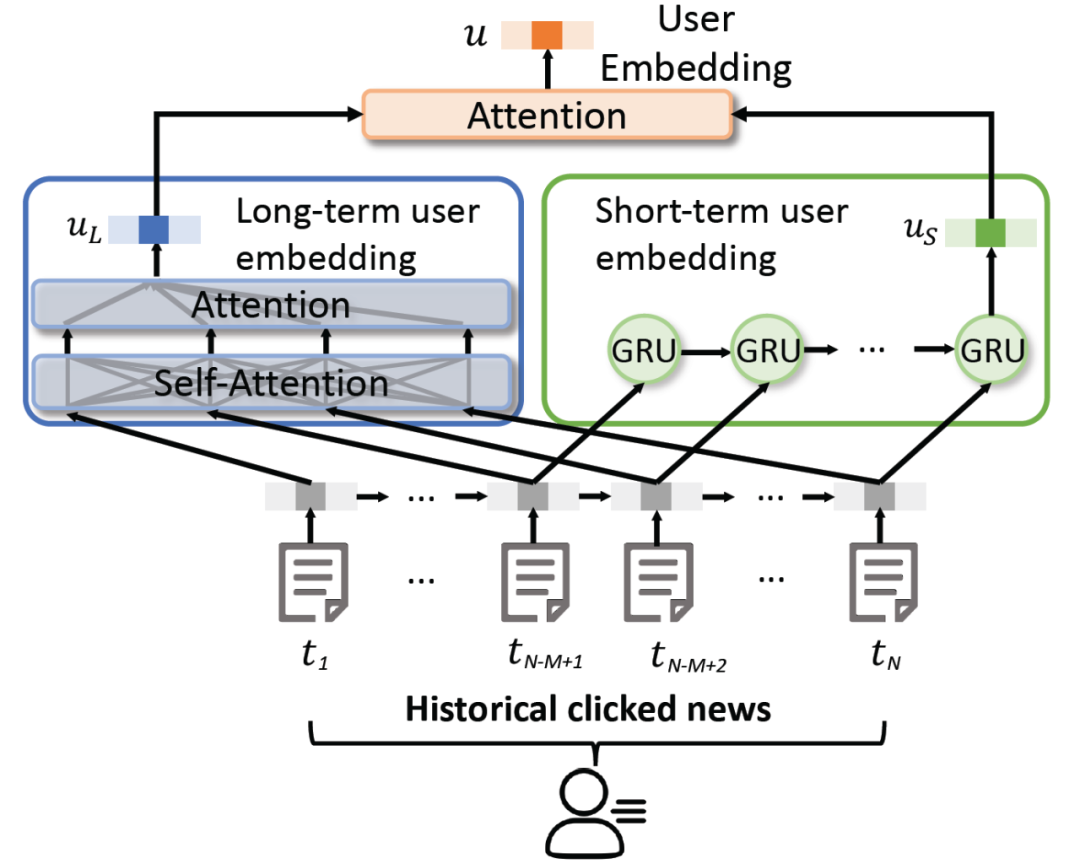
用户模型用于学习用户表示以模拟他们的个人兴趣。其结构如图 4 所示。
具体的,用户模型从用户点击的新闻文章中学习用户表现,同时考虑用户的长期和短期兴趣。通过一个多头自注意力网络和一个注意力池网络相结合来学习用户所有的历史行为,以得到长期兴趣建模。用户模型将 GRU 网络应用于用户最近的行为,以得到短期用户兴趣建模。最后,将长期兴趣和短期兴趣结合成一个统一的用户注意力网络嵌入向量 u。
用户在新闻网站和 App 上的行为可以为新闻推荐模型的训练提供有用的监督信息。例如,如果一个用户 u 点击了一篇由模型预测的低得分排名的新闻文章 t,那么我们可以立即调整模型,从而为这个 “用户 - 新闻” 信息对提供更高的排名分数。本文提出了一种基于点击和非点击行为的新闻推荐模型。
对于用户 u 点击的每一条新闻,随机抽取一个 “曾经也显示过但用户并未点击的” 样本新闻 H。假设该用户共有 B_u 次点击行为,则参数为Θ的新闻推荐模型的损失函数定义为:
(13)
(14)
其中,s(u,t)表示用户 u 对新闻 t 的排名得分,可以使用嵌入向量的点积来表示,例如 s(u,t)=u^T t。(t_i)^c 和(t_i)^nc 分别表示用户点击和未点击的新闻文章。由于准确的新闻推荐模型能够有效地改善用户的新闻阅读体验,而单个用户的行为数据远远不足以训练出一个准确无偏的模型,因此在 FedNews-Rec 框架中,作者提出引入大量的用户设备来共同训练新闻推荐模型。参与模型训练的每个用户设备称为客户端。每个客户端都有一个由服务器维护的当前新闻推荐模型Θ的副本。假设用户 u 的客户端在新闻平台上积累了一组行为,用 B_u 表示,然后根据行为 B_u 和公式(13)中定义的损失函数计算模型的局部梯度 g_u。虽然局部模型梯度 g_u 是由一组行为而不是单个行为来计算的,但是它仍然可能包含一些用户行为的隐私信息。因此,为了更好地保护隐私,作者将局部差分隐私(Local Differential Privacy,LDP)技术应用于局部模型梯度。将应用于 g_u 的随机算法表示为 M,定义为:
(15)
(16)
在 Fed-NewsRec 框架中,使用一个中央服务器来维护新闻推荐模型,并通过来自大量用户的模型梯度对其进行更新。在每一轮更新中,中央服务器随机选择用户客户端的一小部分 r(如 10%),并将当前的新闻推荐模型发送给他们。然后,它从选定的用户客户端收集并聚合本地模型梯度,如下所示:
(17)
其中,U 是本轮学习过程中选择的用户集,B_u 是用于局部模型梯度计算的用户 U 的行为集。然后使用聚合梯度更新中央服务器中维护的全局新闻推荐模型:
(18)
然后将更新的全局模型分发到用户设备以更新其本地模型。重复这个过程,直到模型训练收敛。
本文实验是在一个来自挪威新闻网站的公共新闻推荐数据集(Adressa)和另一个从微软新闻中收集得到的真实数据集(MSN-News)上进行的。假设不同用户的行为日志以分散的方式存储,以模拟隐私保护新闻推荐模型训练的实际应用。使用用户上周产生的行为数据进行测试,剩下的行为数据用于训练。另外,由于在实际应用中并不是所有的用户都能参与模型的训练,所以随机选取一半的用户进行训练,并对所有用户进行测试。
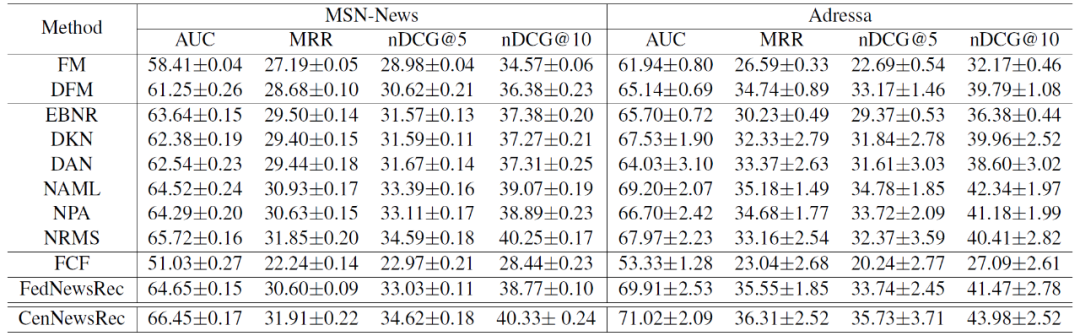
作者将 Fed-NewsRec 与多个已有方法进行对比,具体包括:(1)因子分解机(Factorization machine,FM),经典的推荐方法;(2)深度融合模型(Deep fusion model,DFM),专门的新闻推荐模型;(3)EBNR,使用 GRU 进行用户建模;(4)DKN,利用具有知识意识的 CNN 网络进行新闻推荐;(5)DAN,使用 CNN 从新闻标题和实体中学习新闻表示,使用 LSTM 学习用户表示;(6)NAML,多视角关注学习新闻表征;(7)NPA,利用个性化注意力网络学习新闻和用户表征;(8)NRMS,通过多头自注意力网络学习新闻和用户的表征;(9)FCF,联邦协同过滤推荐方法,即我们第二章中介绍的方法;(10)Cen-NewsRec,它与 Fed-NewsRec 具有相同的新闻推荐模型,但是它是根据集中的用户行为数据进行训练的。
首先,通过比较 Fed-NewsRec 和目前主流的新闻推荐方法,如 NRMS、NPA 和 EBNR,验证了 Fed-NewsRec 在个性化新闻推荐模型学习中的有效性。而且,与现有方法基于集中存储的用户行为数据训练的方式不同,Fed-NewsRec 中的用户行为数据分散存储在本地用户设备上,从不上传。因此,Fed-NewsRec 可以在训练出准确的新闻推荐模型的同时,更好地保护用户隐私。
其次,Fed-NewsRec 比现有的基于联邦学习的推荐方法(FCF)的性能更好。FCF 在新闻推荐中的表现并不理想,这是因为 FCF 要求每个用户和每个 item 都参与到训练过程中来学习它们的嵌入,且用户和 item 为预先已知的。然而,在实际应用中,由于各种原因,并不是所有的用户都能参加训练。此外,网络新闻平台上的新闻文章很快就会过期,新的新闻文章不断涌现。因此,许多推荐新闻 item 在训练阶段都是未知的,而 FCF 无法处理这些 item。Fed-NewsRec 从新闻内容中学习新闻表示,并使用神经网络模型从用户行为中学习用户表示。因此,Fed-NewsRec 能够处理新用户和新 item 的问题,更适合新闻推荐场景。
最后,Fed-NewsRec 的性能比 Cen-NewsRec 差,后者与 Fed-NewsRec 有相同的新闻推荐模型,但训练的是集中的用户行为数据。集中存储的数据比分散的数据更有利于模型训练,因此 Cen-NewsRec 优于 Fed-NewsRec 是很好理解的。此外,在 Fed-NewsRec 中,采用局部差分隐私技术和 Laplace 噪声来保护模型梯度中的隐私信息,这进一步导致了聚合梯度模型更新的准确性不高。
在第三节中,Fed-NewsRec 解决了 FCF 中的 “要求所有用户都参与到联邦学习的过程中来训练他们的向量” 的问题,但是它只适合于新闻推荐应用场景,无法应用到其它场景中,不具备普适性。本节中我们介绍一个通用的基于内容的联邦多视图推荐框架 FL-MV-DSSM(Federated Learning-Multi View-Deep Structured Semantic Models)[4]。该框架通过利用来自不同 APP 的信息训练一个共享的用户子模型,从而具有更好的 item 推荐性能。
首先,通过将一个通用的深度学习模型(Deep-Structured Semantic Models,DSSM)转换为一个联邦学习环境,FL-MV-DSSM 可以将用户和 item 映射到共享的语义空间,以便进一步实现基于内容的推荐,FL-MV-DSSM 能够处理现有 FedRec 的冷启动问题(Cold Start)。然后,本文设计了一种新的 FL-MV-DSSM 方法,从多个数据源学习联邦模型以获取更丰富的用户级特征,从而大大提高了 FL-MV-DSSM 的推荐性能。此外,FL-MV-DSSM 提供了一种新的联邦多视图设置,例如可以使用来自不同手机 APP 的数据共同学习一个联邦模型。
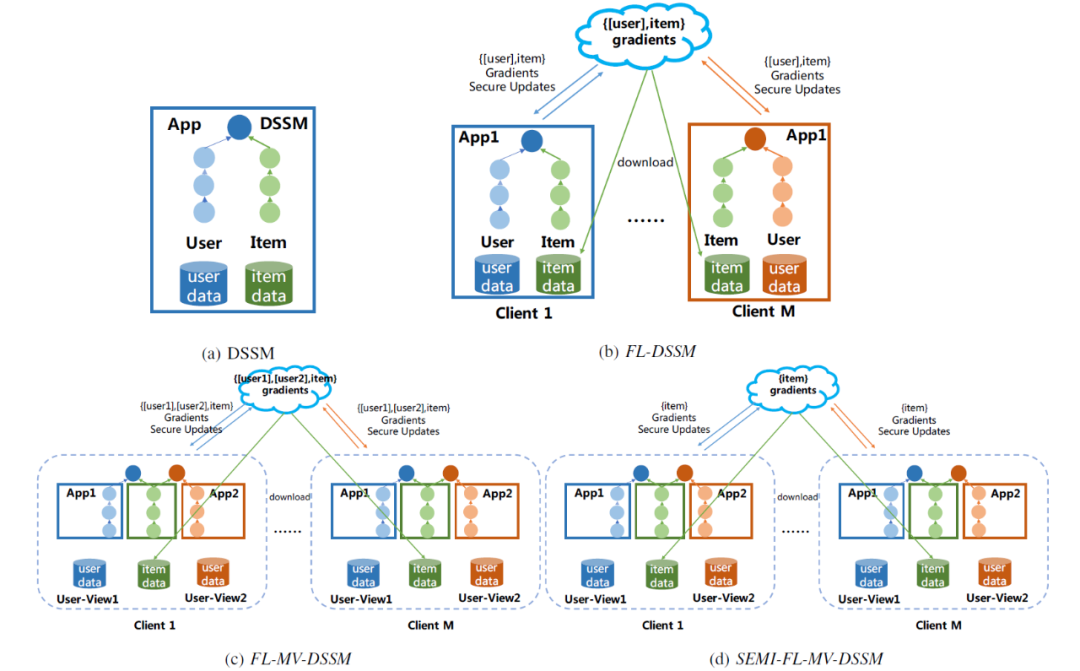
DSSM 最初是为 web 搜索而设计的,它通过多层神经网络从用户的查询词和候选文档中提取语义向量,然后利用余弦相似度来度量查询与文档在语义空间中的相关性。在本文通用联邦多视图推荐设置中,采用 DSSM 作为推荐方法的基本模型,如图 5(a)所示。
假设每个 FL 客户端有 N 个用户级特性的视图(每个 App 考虑对应一种视图),记为第 i 个视图的特征 U_i,第 i 个视图(App)只能访问 U_i 对应的数据集。从推荐提供程序中下载 item 数据集 I(item dataset)。所有视图都可以访问共享数据集 I。对于联邦学习推荐系统任务,假设老用户有一些可以生成行为数据 y,而新用户没有任何行为数据。FL-MV-DSSM 建立在传统的 FedAvg 算法基础上,需要 FL 中央服务器提供初始模型,如图 5(c)所示。
如下 Algorithm 1 给出了 FL-MV-DSSM 的训练算法,假设在 FL-MV-DSSM 的训练阶段,所有的 FL 客户端都是具有基于 item 数据集 I 生成行为数据 y 的老用户。在每个视图 i 中,根据第 i 个视图的私有用户数据 U_i 和本地共享 item 数据 I 计算用户子模型(user sub-model)和 item 子模型(item sub-model)的梯度。虽然 FL-MV-DSSM 是一种基于内容的联邦学习推荐系统任务,但与仅使用用户子模型的聚合梯度相比,item 子模型的聚合梯度具有更好的推荐性能。
因此,在 FL-MV-DSSM 中,item 子模型的梯度将以 FL 方式聚合,而用户梯度的聚合可通过 Algorithm 1 中第 9 行的 “aggregate_user_submodel” 标志配置,这可以生成 FL-MV-DSSM 的一个变体,即 SEMI-FL-MV-DSSM。每轮 FL 训练结束后,根据 FL 中央服务器发布的新的全局梯度,以 FedAvg 方式更新用户和 item 子模型。用户和 item 子模型的梯度都包含了需要保护的视图中特定的信息,因此 FL-MV-DSSM 提供了两个安全聚合原语:local_secure_aggregate()和 remote_secure_aggregate(),以保护本地和远程梯度聚合。
Algorithm 2 给出了 FL-MV-DSSM 的预测算法。对于每个 item x_Ij,无论是旧 item 还是新 item,item 子模型都输出其结果 y_Ij。同时,用 y_Ij 的多个用户视图进行局部相似度比较,以确定用户的安全性。根据相似度比较结果,FL-MV-DSSM 将为用户输出 top-K item,无论是旧 item 还是新 item。
除了传统 FL 的安全要求外,FL-MV-DSSM 还需要额外的安全保证。在联邦多视图设置中,虽然所有视图都协同训练一个模型,但是视图之间不应该有原始数据交互,因为每个数据集 U_i 中都包含了需要被保护的私有视图特定信息。此外,每个视图对 item 子模型的贡献(从共享的本地数据集 I 中学习)也应受到保护,因为恶意视图可以通过监视其对共享局部 item 子模型的更改,从梯度中推断出正常视图的原始数据。
-
【传统 FL】:违背 FL 协议的 FL 客户端和 / 或 FL 中央服务器本身就是潜在的恶意攻击者(Adversaries),例如向诚实用户发送错误和 / 或任意选择的消息、中止、省略消息、彼此共享其对协议的全部视图,以及如果中央服务器是主动对手也与中央服务器共享其对协议的完整视图。
-
【联邦多视图】:某个视图可能是完全恶意的,这意味着作为一个 APP 它会做出各种不安全动作,例如,监视网络接口以观察正常视图的网络流量,对共享的本地 item 子模型进行空更新以推断得到正常视图的更新,监视 item 子模型的变化等等,从而推断出正常视图中的数据信息。
视图级别隔离(View-Level Isolation):每个视图的数据集 U_i 和模型 W_Ui 仅可访问第 i 个视图。隔离可以通过加密或可信执行环境(Trusted execution environment ,TEE)来实现。TEE 是一种在多环境共存的条件下,建立策略以保护每个环境的代码和数据的方法。TEE 在连接设备中提供一个安全区域,确保敏感数据在隔离、可信的环境中存储、处理和保护。
为了抵抗这些安全问题,FL-MV-DSSM 采用了两种安全原语:local_secure_aggregate() 和 remote_secure_aggregate(),用于 Algorithm 1 和 2 中。local_secure_aggregate()和 remote_secure_aggregate()的目的都是在本地或远程安全聚合 N 个向量,并返回聚合结果,而不会将每个参与者的原始数据暴露给其他参与者(本地 FL-MV-DSSM 框架或远程 FL 中央服务器)。
最后,作者还介绍了一些 FL-MV-DSSM 的方法变体。
-
FL-DSSM。基于前面介绍的 FL-MV-DSSM 算法,通过将视图数 N 设置为 1,可以简单回归为 FL-DSSM 训练和预测算法。关于 FL-DSSM 的详细结构可见图 5(b)。与图 5(c)中的 FL-MV-DSSM 不同,图 5(b)中 FL-DSSM 向中央服务器发送的仅为一个视图的{[user],item}gradients,而不再是多个视图对应的{[user1],[user2],[item]}gradients。
-
SEMI-FL-MV-DSSM。通过将 Algorithm 1 中的 “aggregate_user_sub-model” 标志设置为 false,可以得到 SEMI-FL-MV-DSSM。SEMI-FL-MV-DSSM 只对 item 子模型的梯度进行安全聚合,而不聚合用户子模型的梯度。关于 SEMI-FL-MV-DSSM 的详细结构可见图 5(d)。与图 5(c)中的 FL-MV-DSSM 不同,图 5(d)中 SEMI-FL-MV-DSSM 向中央服务器发送的仅为{item}gradients,而不再是{[user1],[user2],item}gradients。
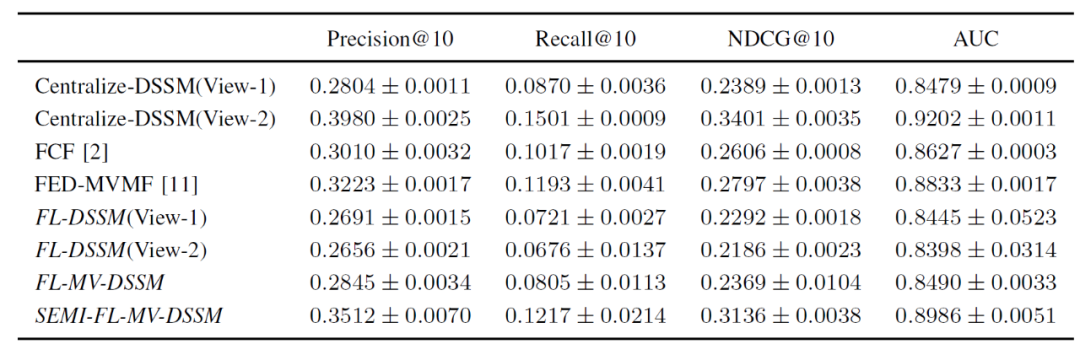
FL-MV-DSSM 及其它方法在 MovieLens 数据集上的性能见表 3。从结果可以看出,FL-MV-DSSM 比 FL-DSSM 具有更好的性能,因为 FL-MV-DSSM 可以从多个视图(如多个用户 APP)合并更多的用户特征,共同训练出更好的模型。一个有趣的结果是,作者发现 SEMI-FL-MV-DSSM 只聚合共享 item 子模型而不聚合用户子模型,但其性能优于 FCF 和 FED-MVMF,经过 60 轮 FL 训练后,其结果甚至优于经典的集中式 DSSM 的结果。作者认为,这是可以理解的,对于所有的联邦推荐系统算法,其性能数据都是通过 “联合评估” 来收集的,如果不将其它 FL 参与者的贡献聚合起来,那么用户子模型的性能将很快适应用户本地数据。
表 3. FL-MV-DSSM 在 MovieLens 数据集上的推荐性能及其变体方法、已有联邦推荐算法的性能对比
此外,本文作者为了评估 FL-MV-DSSM 的冷启动性能,构建了三个冷启动实验场景:冷启动用户(CS-Users)、冷启动 item(CS-Items)和冷启动用户 item(CS-Users-Items)。对于冷启动用户,在模型训练过程中完全排除了 10% 的用户及其交互数据,并用剩余 90% 的用户及其交互数据学习模型参数。对于冷启动 item,在模型训练期间,忽略 10%item 的随机子集,剩下 90% 的 item 学习模型参数。对于冷启动用户 item,从模型训练中排除 10% 的用户和 item 的随机子集,并与其他用户、交互数据和 item 一起学习模型参数。
表 4 给出了三次冷启动的实验结果。结果表明,FL-MV-DSSM 在保持通用性的前提下,可以可靠地用于冷起动推荐系统。此外,FL-MV-DSSM 对新用户具有良好的冷启动预测性能,这对于隐私保护的推荐服务具有重要的意义。然而,冷启动 item 和用户 item 的性能低于冷启动用户。作者认为,其原因可能是,在本文使用的实验数据集中,用户之间(考虑年龄、性别、职业等)的差异小于 item(电影标题、流派等)的差异,FL-MV-DSSM 可以正确地了解这种差异并以更高的精度推荐。
表 4. FL-MV-DSSM 在 MovieLens 数据集上的冷启动推荐性能
本文提出了第一个通用的基于内容的联邦多视图框架 FL-MV-DSSM,它可以同时解决冷启动问题和推荐质量问题。此外,本文还将传统的联邦设置扩展到了一个新的联邦多视图环境中,这可能会在推荐场景中启用新的 FL 模型,并带来新的安全挑战。针对这些安全挑战,本文还提出了一种新的解决方案来满足安全需求。
我们在这个联邦学习推荐系统的专题中具体讨论了联邦学习框架系列中的 “推荐系统” 问题。我们从第一个基于协作过滤 CF 的联邦推荐系统谈起,具体分析了其在推荐问题中的有效性。从作者原文给出的实验结果可以看出,FCF 具有与 CF 相当的推荐性能,也就是说联邦学习的架构并未对推荐模型本身造成太多的影响。
但是,FCF 也存在一些问题,例如要求用户和 item 信息都是已知的,要求每个用户和每个 item 都参与到训练过程中来学习它们的嵌入等等。这些问题阻碍了 FCF 在实用场景中的推广。接下来,我们具体分析了在新闻学习中的联邦推荐系统 Fed-NewsRec,它能够很好地解决 FCF 的上述问题,利用海量用户的行为数据训练出准确的新闻推荐模型。
Fed-NewsRec 是专门为新闻推荐构建的方法,其中使用的新闻模型、用户模型都仅限于该领域。在第四节中,我们进一步分析了一个普适的基于内容的联邦多视图推荐框架 FL-MV-DSSM。该方法可以将用户和 item 映射到共享的语义空间,以便进一步实现基于内容的推荐。此外,该方法也是基于多视图进行模型训练的,能够进一步提升推荐系统的性能。
当然,除了我们上述介绍的文章,还有很多基于矩阵分解(Matrix Factorization)、元学习(Meta-Learning)的联邦推荐系统也都在不同的实验、应用场景中获得了较好的效果。联邦推荐系统具有很好的、巨大的应用前景,我们将会在联邦学习系列专题中继续关注和报道相关的研究进展。
《当传统联邦学习面临异构性挑战,不妨尝试这些个性化联邦学习算法》
[1] https://blog.openmined.org/federated-learning-recommendations-part1/
[2] Muhammad Ammad-ud-din, Elena Ivannikova, Suleiman A. Khan, Were Oyomno, Qiang Fu, Kuan Eeik Tan, and Adrian Flanagan. Federated collaborative filtering for privacy-preserving personalized recommendation system. CoRR, abs/1901.09888, 2019, https://arxiv.org/pdf/1901.09888.pdf
[3] Tao Qi, Fangzhao Wu, Chuhan Wu, Yongfeng Huang, and Xing Xie. Fedrec: Privacy-preserving news recommendation with federated learning. arXiv preprint arXiv:2003.09592, 2020,https://arxiv.org/pdf/2003.09592.pdf
[4] A Federated Multi-View Deep Learning Framework for Privacy-Preserving Recommendations
https://arxiv.org/pdf/2008.10808.pdf
仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
Amazon SageMaker 1000元大礼包
ML训练成本降90%,被全球上万家公司使用,Amazon SageMaker是全托管机器学习平台,支持绝大多数机器学习框架与算法,并且用 IDE 写代码、可视化、Debug一气呵成。
现在,我们准备了1000元的免费额度,开发者可以亲自上手体验,让开发高质量模型变得更加轻松。
点击阅读原文,填写表单后我们将与你联系,为你完成礼包充值。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]
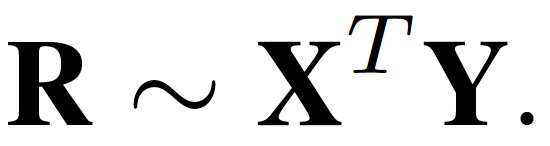 (1)
(1)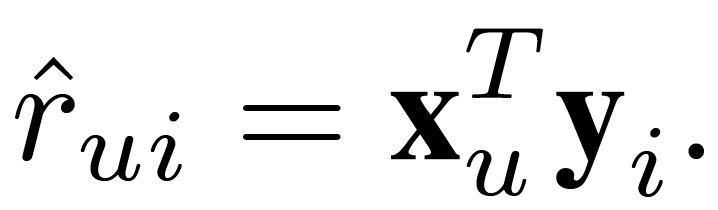 (2)
(2) 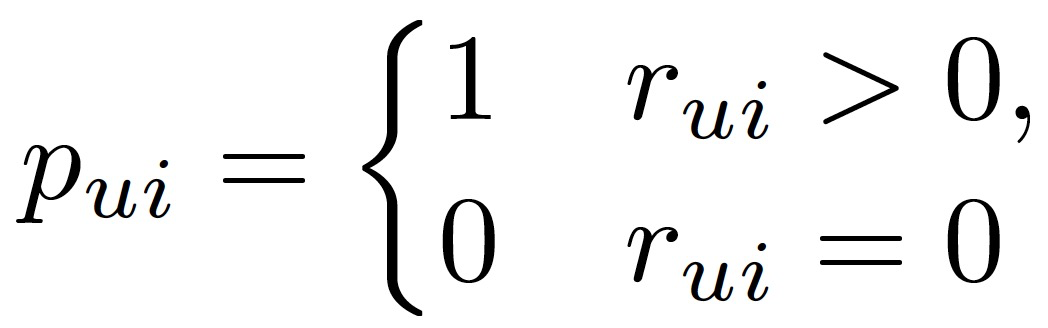 (3)
(3)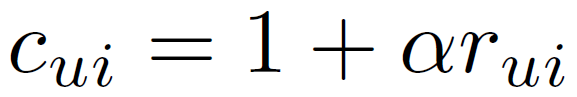 (4)
(4)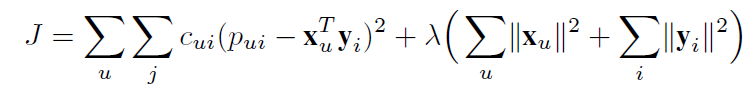 (5)
(5)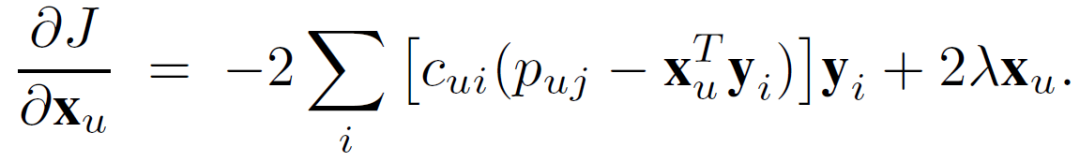 (6)
(6)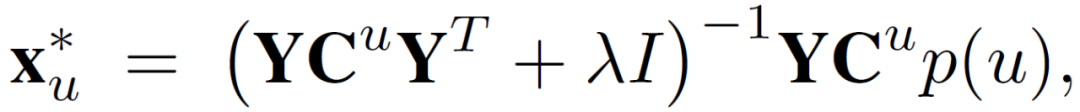 (7)
(7)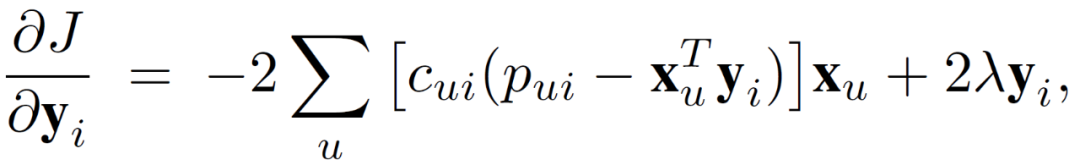 (8)
(8)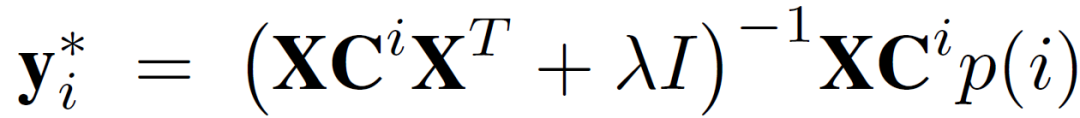 (9)
(9)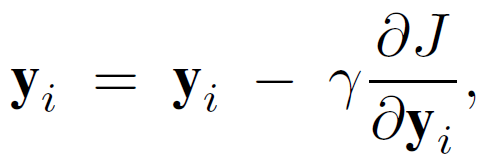 (10)
(10)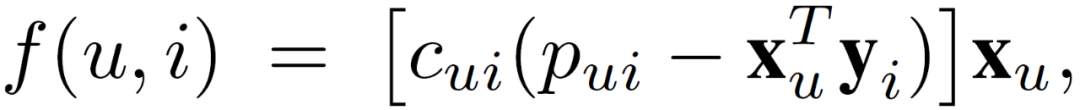 (11)
(11)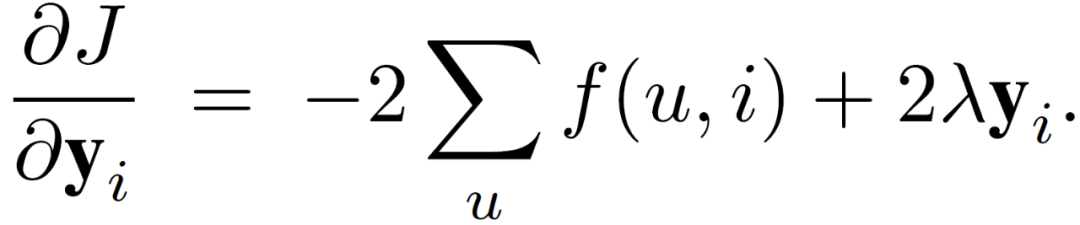 (12)
(12)
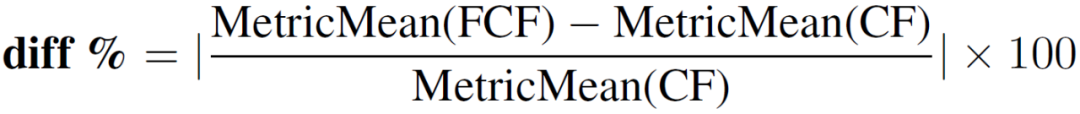
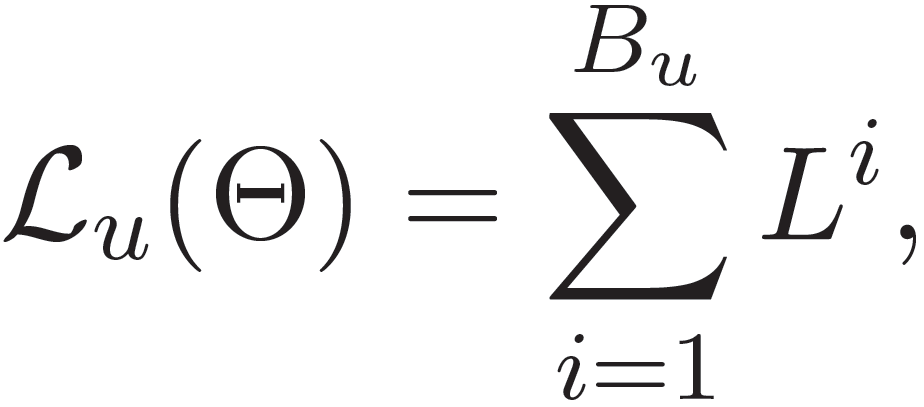 (13)
(13)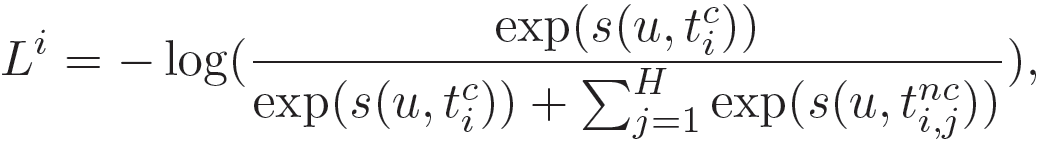 (14)
(14)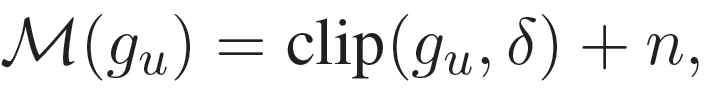 (15)
(15)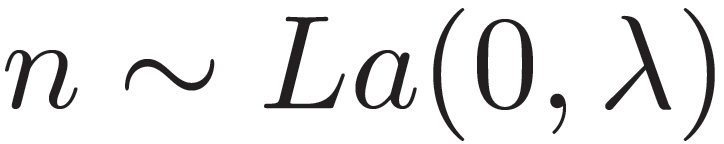 (16)
(16)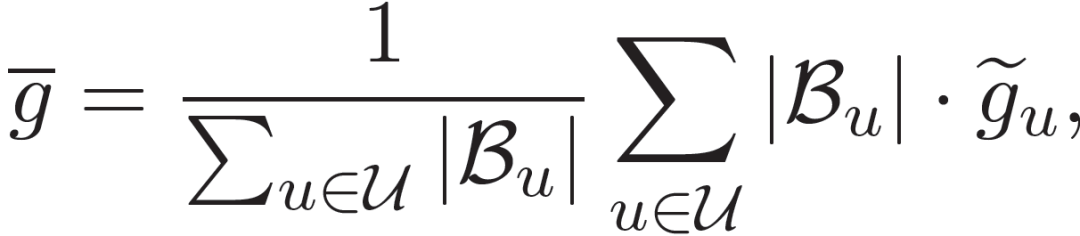 (17)
(17)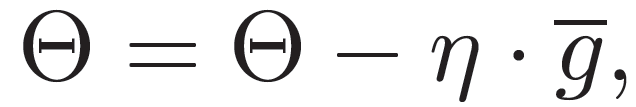 (18)
(18)





文章评论