机器之心报道
机器之心编辑部
通过互联网学习意味着可以在无垠的知识海洋中遨游,但也可能因为广阔而迷失。在这个项目中,作者为机器学习提供了一个完整的学习路径。从 ML 到 DL、Scikit-Learn 到 TensorFlow,你需要这份学海指南。
曾有多少次,当你试图接近某一个新主题或领域时,会感到困惑、迷失方向并且无「路」可循。要如何确保你能够深刻理解并且获得运用它的能力呢?当然是借鉴其他人的成熟路径,然后跟着他一步步学习,少走很多弯路。
在这篇文章中,作者总结了三四年内从互联网学习机器学习的经验,他收集了大量开源项目、工具、教程和视频链接等资源,并将它们组织成一条高效的学习路径。
-
项目地址:https://github.com/clone95/Machine-Learning-Study-Path-March-2019
本资源库旨在为以下领域提供三种有机完整的学习路径:
-
机器学习
-
商业智能(即将发布)
-
云计算(即将发布)
在此你将能够了解相关原理并且在项目实践中予以运用。如果仔细遵循这些学习路径,则可以从零开始构建完整的认识和获得始终可用的技能。事实上,这些学习路径不需要之前有相关知识,但基础编程和简单数学是理解和实践大多数概念的必要条件。
这里列出的每一个资源都是免费或开源的,作者设法以简洁方式进行表述以避免显得太过复杂。此外,作者试图按照层次和复杂程度来组织内容,从而为学习机器学习原理提供一个连贯的概念。
作者表示,第二本指南(商业智能)将在 2 至 3 周内发布:
-
机器学习生涯-已发布
-
商业智能生涯-即将发布
-
云计算生涯-即将发布
以下是不同学习路径的的路线图(机器学习的路线图已发布)。
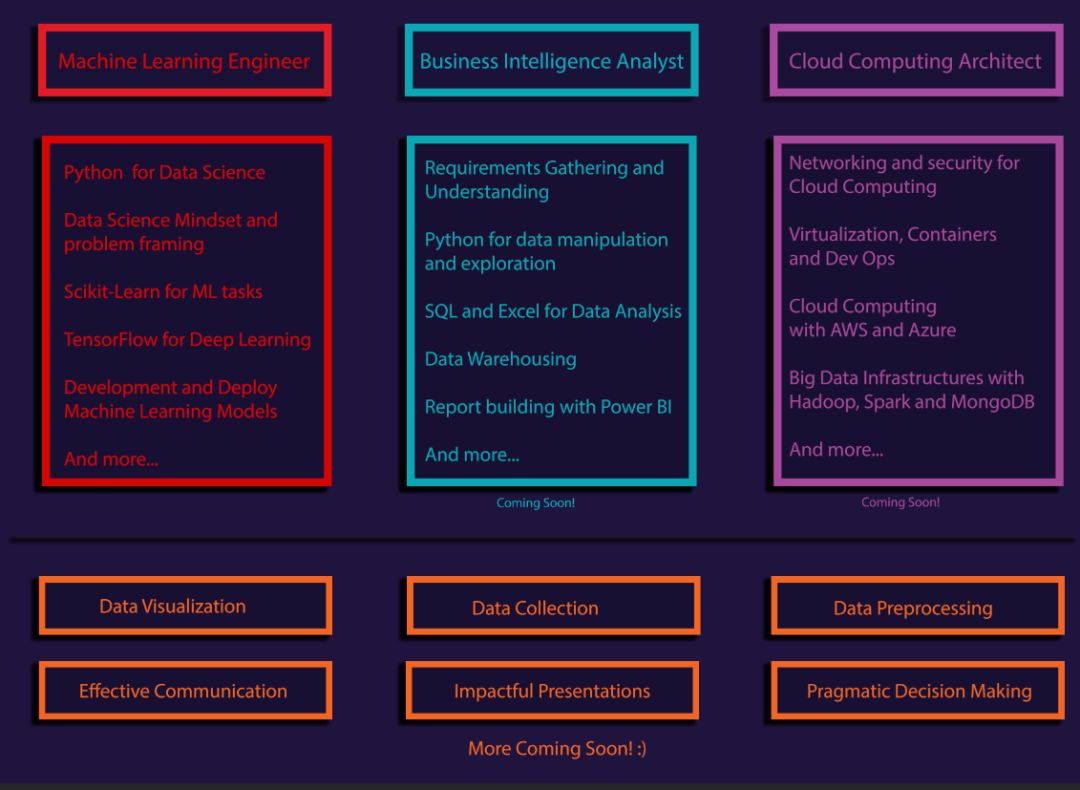
三大路径与专题
在三大路径中,机器学习工程师已经完成并发布,其它商业数据分析和云计算还没有完成。其中在机器学习工程师需要从基本的工具、传统机器学习到深度学习打造完整的知识体系,同时也要知道如何工程化地开发和部署模型。
在学习 ML 和 DL 的过程中,作者表示重点是按照层次理解各模型的概念,并通过优秀的开源框架实现这些概念。文章后面会具体介绍机器学习工程师应该学习哪些模型与工具才能一步步成长。
对于后面的两条路径,它们注重的内容不同,知识体系也不一样,有需要的同学还需要等几周。此外,作者还提供了一些额外的扩展知识,包括数据专题和软技能专题。
其中数据专题介绍了数据的各种操作,它们的确是每一位数据工作者的核心工具包。从某种角度看,与数据打交道是一门艺术,最佳实践会帮助你理解处理数据的正确方式,但同时你也需要培养一种如何处理数据的「直觉」,而这种「直觉」大都是由情境和经验驱动的。基于此,这些专题将着重讨论训练和实践。
机器学习工程师成才之路
这一部分介绍了已经发布的「机器学习工程师」学习路径,作者介绍了很多学习资源,我们只展示了简要的示例,更多细节请查看原项目。
这里列出的所有东西都是开源且免费的,而且大部分来自世界著名的大学和开源协会。
当我们学习一些新的东西,尤其是那些内容广泛又复杂的事物时,避免混淆是很有必要的。因此本文接下来将介绍一些相关内容,而且尽可能采用那些来自相同语境和作者的内容。如果没有合适的内容,作者收集了理论和例子以及一些指向资源的内容,如「______的最佳实践」。
作者将学习路径分为四部分:
1. 先决条件
-
Python
-
Jupyter Notebook
-
需要掌握的数学
-
机器学习路径
2. 用 Scikit-Learn 库进行机器学习
-
为什么选择 Scikit-Learn?
-
端到端机器学习项目
-
线性回归
-
分类
-
训练模型
-
支持向量机
-
决策树
-
集成学习和随机森林
-
无监督学习
-
当前总结和未来展望
3. 用 TensorFlow 学习神经网络
-
为什么选择 TensorFlow
-
启动和运行 TensorFlow
-
ANN——人工神经网络
-
CNN——卷积神经网络
-
RNN——循环神经网络
-
训练网络:最佳实践
-
自编码器
-
强化学习
-
下一步
4. 学习工具
-
机器学习项目
-
数据科学工具
-
博客/Youtube 频道/网站
背景知识
Python 是最有用和受欢迎的编程语言之一,因此它用于机器学习领域是无可厚非的事。和数据科学领域的大部分框架一样,TensorFlow 和 Python 结合了,而 Scikit-Learn 则是用 Python 写的。
简而言之,Jupyter Notebook 就是用来写并运行 Python 代码的编辑器。与数据打交道意味着需要大量实验,并将实验组织成某些具体的形式以获取潜在知识,所以 Jupyter Notebook 就必不可少了。
Python 和 Jupyer Notebook 是最基础的模块,相信大家已经非常熟了。如果需要走机器学习之路,除了 Python 外,首先就需要知道如何使用数值计算库 NumPy、可视化库 Matplotlib 和数据预处理库 Pandas,它们都是机器学习工程必不可少的工具。
有人告诉你机器学习背后的数学很难?这么说也没错。但是,要知道你每次要用它的时候,机器会为你处理这些。所以重点是抓住主要概念并认识到其局限性和应用方面。如果你不熟悉这些概念,那就学习,因为这是所有一切的原理。
有了这三种资源,你就能够明白你真正需要深入理解的大部分东西。
-
关于线性代数的精品课程:https://ocw.mit.edu/courses/mathematics/18-06-linear-algebra-spring-2010/
-
与基本概率和统计学概念结合:https://www.edx.org/course/introduction-to-probability-0
-
你需要了解的大多数数学:https://explained.ai/matrix-calculus/index.html#sec4.5
如下书籍所述,它描述了有关什么是机器学习以及什么时候需要机器学习,这些都是最简洁和最具启发性的概述。
地址:https://www.oreilly.com/library/view/hands-on-machine-learning/9781491962282/ch01.html
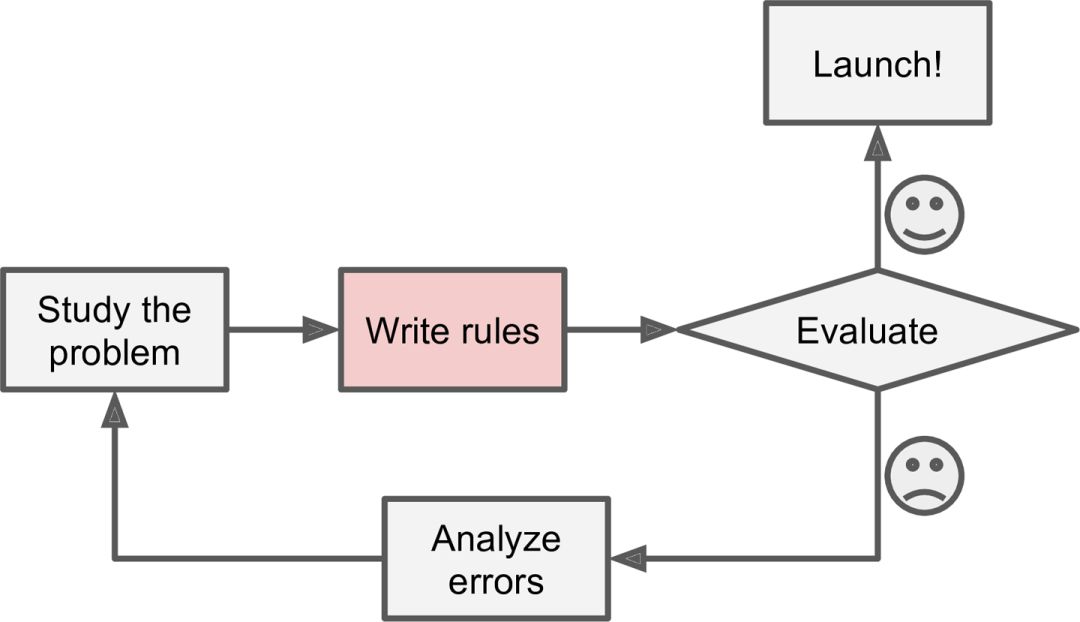
传统编程开发流程。
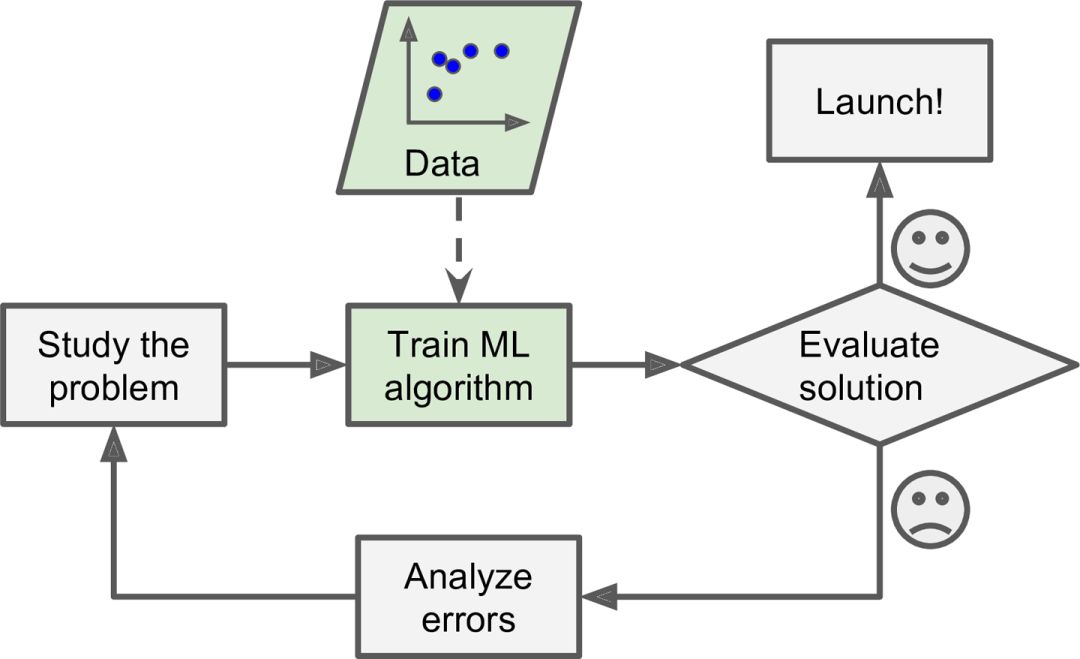
机器学习开发流程。
机器学习与 Scikit-Learn
Scikit-Learn 是最完整、最成熟以及完档最完整的机器学习任务库之一。Scikit-Learn 利用功能强大和先进的模型实现「开箱即用」,并且为数据科学流程提供设施功能。初次使用时,作者建议你过一遍下面的 Kaggle 案例,它目的是试图对泰坦尼克号上的乘客是否最有可能生还作出预测。
泰坦尼克号示例:https://www.kaggle.com/startupsci/titanic-data-science-solutions
其它更多的示例与资料可在 Kaggle 上获得,该平台提供大量免费数据集以及有趣的挑战和机器学习模型试验。
1. 线性回归
最简单的机器学习形式,也是每个对预测数据集结果感兴趣的人的起点。
-
例 1:https://scikit-learn.org/stable/auto_examples/linear_model/plot_ols.html#sphx-glr-auto-examples-linear-model-plot-ols-py
-
例 2:https://bigdata-madesimple.com/how-to-run-linear-regression-in-python-scikit-learn/
-
例 3:https://www.geeksforgeeks.org/linear-regression-python-implementation/
2. 分类
当想要从不同的可能性中预测结果时,分类是最重要的机器学习任务之一。
-
二分类:https://machinelearningmastery.com/make-predictions-scikit-learn/
-
logistic 回归:https://towardsdatascience.com/building-a-logistic-regression-in-python-301d27367c24
-
分类器度量标准:https://medium.com/thalus-ai/performance-metrics-for-classification-problems-in-machine-learning-part-i-b085d432082b
3. 支持向量机(SVM)
支持向量机是一种非常经典的 ML 模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是类别间隔最大化,最终转化为一个凸二次规划问题来求解。
-
理论解释:https://www.bilibili.com/video/av28186618
-
实战指南:https://www.bilibili.com/video/av38543231
-
实战指南:http://dataaspirant.com/2017/02/01/decision-tree-algorithm-python-with-scikit-learn/
4. 决策树
决策树预测结果背后最简单但最有效的方法之一,它们被用于很多方面(如随机森林)。
-
理论解释:https://www.bilibili.com/video/av26086646
-
实战指南:https://www.bilibili.com/video/av35523476
-
实战指南:http://dataaspirant.com/2017/02/01/decision-tree-algorithm-python-with-scikit-learn/
5. 集成学习和随机森林
集成学习是利用所有不同特征、一些机器学习模型的优缺点来获得一组「投票者」,这些投票者在每次预测时都会给你最有可能的结果,这些投票由不同的分类器给出(SVM、ID3 算法、logistic 回归)。
6. 无监督学习
-
台大李宏毅视频:https://www.bilibili.com/video/av10590361/?p=24
-
explains Unsupervised Learning really well:https://towardsdatascience.com/unsupervised-learning-with-python-173c51dc7f03
-
无监督学习、有监督学习和强化学习的区别:https://blogs.nvidia.com/blog/2018/08/02/supervised-unsupervised-learning/
深度学习和 TensorFlow
自 2015 年开源以来,深度学习框架的天下就属于 TensorFlow。不论是 GitHub 的收藏量或 Fork 量,还是业界使用量都无可比拟地位列顶尖。这一部分作者介绍了很多 TensorFlow 相关的教程与实现,推荐读者可以直接看 TensorFlow 的官方教程。对于深度学习,读者可以跟着斯坦福的 CS231n 课程或《深度学习》进行学习。
在了解 TensorFlow 后,作者表示我们可以迭代地学习用深度学习做工程:
-
通过斯坦福 CS231n、吴恩达的 DL 专项课程或李宏毅的 ML 课程理解最基本的概念,不需要完全弄懂数学推导,只需要知道是什么为什么就行。
-
每一次深度挖掘一个专题,包括理论、教程、实现案例(例如 RNN 理论、RNN 教程和 RNN 实现案例)。
-
第二步循环多个主题后,再看一遍第一步的资源,抓住主要的推导与细节。
后面作者从全连接网络、循环网络、卷积网络和自编码器等模块介绍了很多学习资源,详细内容请查看原 GitHub 项目。
学习工具
这一部分,作者整理大量学习资源,包括机器学习项目、工具、Youtube 频道、博客、网站等,感兴趣的读者可自行查看。
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]

文章评论