
来源:固收小黄书
作者:固收小黄
在几位大佬的鼓励下,小黄要开始在公众号上做些小笔记了。希望能帮到有需要的人,绕过一些我遇过的坑。
目前打算就债市的Python爬虫入门写三篇,完全新手向(因为我就是新手啊)。第一篇即本篇,介绍基础的Python爬虫及其在债市的简单尝试;第二篇将拓展至某些复杂网页的爬取(如中债登上的一些js动态页面、央妈网页的cookie反爬虫应对等);第三篇打算汇报一下基于爬虫实现的一些债市小发现。此为一二篇合集。

那么开始吧。
所谓爬虫,我理解是对网络数据的定制化抓取。运用Python强大的网页处理能力进行爬虫,能为我们的债市交易及研究提供很多便捷,比如开发交易员培训报名的抢位外挂;到从业公示网爬取同业小姐姐们的证件照;实现对中债登、上清所、货币中心、交易所、统计局、央行等常用网页内信息的批量抓取、监控、分析等。
以17年四季度至今的10年国开行情和10年国开借券存量为例。从下图可以看出,在17年国庆后,10年国开的借券存量先于收益率上行,且于17年11月中旬早于收益率筑顶;空方在17年底部分平仓后,18年开年借券量再度上行,随后现券则对应呈现最近的“破5”行情,存在一定的领先性:
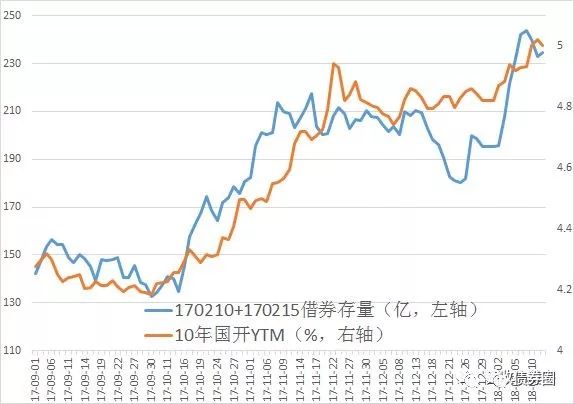
先不论上述研究的意义和缺陷,今天要讨论的是,如果想复制上面的研究,该怎么做?首先我们很容易拿到10年国开的收益率序列,难点是对170215和170210借券存量序列的获取,这个数在中债登官网的中债数据→结算行情→风险监测→债券借贷风险监测里可以找到:

然而,很坑爹的是,这个数在中债登上只能按日查询,我们每次的点击,能且只能查询到指定某一日的数值。如果想要连续区间的时间序列?不存在的。

也即是说,通过人工的方法,如果要获取从17年9月至今每个交易日的10年国开借券存量数据,必须重复打开中债登网、选券(210和215各一次)、改日期、点击查询、记录下结果这个操作将近200次。这个时候,我们可以选择请个实习生,又或者写个Python爬虫以代劳上面的操作。
在开始爬虫前,需要做些准备工作:
首先,安装Python并瞄几眼语法入门···
然后,观察刚刚查询所用的中债登地址:http://www.chinabond.com.cn/jsp/include/EJB/jdtj_dzzq.jsp?sel4=1&tbSelYear6=2018&tbSelMonth6=1&calSelectedDate6=4&ZQFXRJD1=00&FUXFSJD1=00&JXFSJD2=00&JDQX2=00&ZQFXRJD3=00&ZQFXRJD4=00&I_ZQDM_JD=170215
地址结尾里熟悉的170215告诉了我们,这个查询网页返回的结果,是由网页地址所控制的。刨除那些冗杂信息,就能看出这个网址的规律所在(这也是选这个作第一篇例子的原因,下一篇将提到如果网址不变的情况如何处理)。网址中 “...Year6=2018 ...Month6=1 ...Date6=4 ...JD=170215”的这串字符,顾名思义,是对2018年1月4日的170215借券存量的提取,大家可以试试保持其他内容不变,只改变网址中这几个关键数字,就能实现对网址中指定日期/券代码借券存量的查询。
在掌握了网址规律后,接下来就是对网页中想要的内容——借券存量进行提取。虽然在我们眼里,中债登的查询结果网页是长这样的:
而在浏览器和Python君的眼里,网页其实是下图这样的一堆“串串”(这些“串串”可以通过在Chrome里打开网页后右击“检查”获取到,其中,每一行都叫做一个tag,下图里tr、td等是tag的名称;class、bgcolor、align等是tag的属性;最关键的“170215”、“758,000.00”则分别是两个相邻的名为td的tag里的内容):
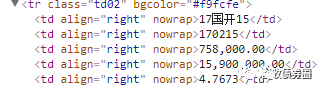
虽然和平常看到的网页不太一样,但这些tag内含的信息和我们所见的是一致的。可以看到,此次的目标数值——170215的借券余额75.8亿,是藏在了<td align="right" nowrap=""> 758,000.00</td>这个tag里,就在那里,不悲不喜。就像Word里可以Ctrl+F查找一样,我们也可以通过Python,从这堆tag里把含有170215这个数的tag用Ctrl+F找出来,也即<td align="right" nowrap="" >170215 </td>,再在往下一行的tag里,就藏着我们想要查询的18年1月4日170215的借券余额数值,75.8亿。
所以问题就已经非常简化了。现在已知了两个事情:1、中债登查询借券余额的地址是有规律的;2、这些规律网址里的内容可通过Python被简化为多个tag的形式并被查找。接下来的思路就是,让Python自动地根据网址规律读取每天的网页,接着让Python把每天查询的网页剥皮成上面那堆tag,再从中Ctrl+F找到在170215和170210所在tag的下一个tag里的借券量数值,提取出来并储存。
要如何指挥Python完成了上面的工作呢?这里用到两个Python的包:urllib(这个包将在下一篇中变成selenium + phantomjs以抓取更复杂网页)和BeautifulSoup。
urllib负责把网页中的内容读进Python里,可以看做是个浏览器;BeautifulSoup则负责Ctrl+F处理那些tag的信息。所以,这个案例里实际要做的工作,就是按查询日期批量把网页内容通过urllib拉扯进Python,然后用BeautifulSoup把想要的东西Ctrl+F出来。
urllib包里,我们主要用到urllib.request.urlopen('网址')的函数,从名字可以看出来,就是把目标网页请求并打开读取的函数,读取完丢进Python后就可以把工作交给BeautifulSoup了。
BeautifulSoup则是网页爬虫的核心,建议大家多熟悉其官方文档,这可能是刚接触Python爬虫时最常查阅的参考书。
在这个案例里,主要用到BeautifulSoup的三个功能:
.find('td', text=‘170215’):顾名思义就是找到名称为td,且内容写作170215的tag
.next_sibling:和字面意一样,就是定位到下一个tag身上的意思
.string:把tag里的内容拎出来
仅用这三个语句,就实现了“寻找170215所在地方,并下移到下一个tag里抓数”的需求。
是不是很简单?所以我已经帮大家写好了,并且标注上了可能遇到的坑。把下面代码复制进装好相关包和万得接口的Python3.6可以直接运行。(看不全的代码可左右滑动屏幕查看,我的代码效率较低,供参考):
# By 债市小黄
# 首先导入刚刚提到的两个包urllib和BeautifulSoup
from urllib import request
from bs4 import BeautifulSoup
# 以及万得接口用以提取交易日,xlwt用以输出结果到Excel,os用以打开输出的Excel
from WindPy import w
from xlwt import Workbook
from os import system
# 定义借券余额爬虫函数,将年、月、日、观察券列表作为输入量
def jqye(year, month, day, bond_list):
# 将年月日填入,补齐中债登网址日期,用urllib读取补齐的查询网址,获取当天的借券统计,并存为page
page = request.urlopen("http://www.chinabond.com.cn/jsp/include/EJB/jdtj_dzzq.jsp?sel4=1&tbSelYear6=" \
+ str(year) + "&tbSelMonth6=" + str(month) + "&calSelectedDate6=" + str(day) \
+ "&ZQFXRJD1=00&FUXFSJD1=00&JXFSJD2=00&JDQX2=00&ZQFXRJD3=00&ZQFXRJD4=00&I_ZQDM_JD=")
# 接下来把刚刚读到的网址内容page用Beautifulsoup解析
# 坑1:用html.parser解析器会少丢信息,用gb18030编码解析以避免中文乱码
# 将解析出的内容储存在soup里
global soup
soup = BeautifulSoup(page, "html.parser", from_encoding="gb18030")
# 定义用以输出的list
jqye_list = []
# 用for...in...循环遍历目标券列表里的所有券代码
# 用find找到券代码所对应的tag,如果找不到意味着没有这个的数(往往因为查询日这个券还没发行),则计为0
# 如果找到了则往下数1个tag,里面就是该债券对应的借券存量,把这个量提取出来
# 坑2:这里连用了2个.next_sibling,因解析后tag间会多出个空格,因此索引下个tag要用到2个.next_sibling
# 坑3:网页上的数字带空格、逗号和小数点,需把都去掉,才能顺利地被Python转为整数识别,即.strip().replace(',', '').replace('.00', '')的作用
for bond_name in bond_list:
bond_position = soup.find('td', text=bond_name)
if bond_position is None:
bond_jqye = 0
else:
bond_jqye = int(bond_position.next_sibling.next_sibling.string.strip().replace(',', '').replace('.00', ''))
# 把爬到的借券存量输出到屏幕上,并存储在jqye_list里
print(str(year) + str(month).zfill(2) + str(day).zfill(2) + ':' + bond_name + ':' + str(bond_jqye))
jqye_list.append(bond_jqye)
# 到这就爬完某一天里bond_list里各个目标券的数值了,把结果返回
return jqye_list
# 用万得接口提取交易日,这里是提取17年9月1日至今的交易日
# 坑4:万得的Python接口好像只有各交易所的交易日,没法提取银行间的交易日,要严谨的银行间交易日序列的话需要用其Excel插件
w.start()
trade_day_list = w.tdays("2017-9-1").Times
w.stop()
# 向程序给出要爬借券量的目标券列表,这里可以是一只,也可以是多只并排
bond_list = ['170215', '170210']
total_jqye_list = []
for trade_day in trade_day_list:
# 将日期和目标券列表输入定义的jqye函数里跑起来
jqye_list = jqye(trade_day.year, trade_day.month, trade_day.day, bond_list)
total_jqye_list.append(jqye_list)
# 坑5:将结果一边爬一边往Excel里存储,之所以不全部爬完再一次性存储是避免中途网络原因报错中断导致前功尽弃
output_workbook = Workbook()
sheet1 = output_workbook.add_sheet(u'jqye_data', cell_overwrite_ok=True)
sheet1.write(0, 0, 'Date')
for i in range(len(bond_list)):
sheet1.write(0, i + 1, bond_list[i])
for i in range(len(total_jqye_list)):
sheet1.write(i + 1, 0, trade_day_list[i])
for j in range(len(total_jqye_list[i])):
sheet1.write(i + 1, j + 1, total_jqye_list[i][j])
output_workbook.save('jqye_output.xls')
system('jqye_output.xls')
# 爬完收工,在Excel里查看结果,Date列如果显示不正确改下单元格日期格式就好
可以发现,哪怕基于我十分糟糕的语法,除去注释,Python也只需30行,就能把这次的需求完整表达。上述程序开动后,一般10分钟以内能爬完一个季度的数。运行时,Python会是这样的:
是不是很excited?
如果还想想练手,可以试试把中债登上每日买断回购的210和215余额也一并爬了,操作与上面类似。这样就能更全面统计做空力量了。
在日常使用浏览器打开网页时,想看的内容往往是不会直接展示在我们面前的,需要我们输入账户密码登录、操作下拉菜单、点击按钮、等待加载等一些列过程后才会出现。而对这类网页进行Python爬虫,使用上一篇中的urllib+BeautifulSoup的方法是难以完成的。

对于这类复杂网页的爬取,比较容易上手(也比较浪费内存)的做法是用selenium + phantomjs + BeautifulSoup(phantomjs是个浏览器,大家也可换成熟悉的Chrome、Firefox等)。其思路简单粗暴却有效,就是用Python代码通过selenium去控制一个浏览器,直接在浏览器上模拟和复制人工访问网页的操作,从而实现Python与网页间的一些复杂交互,甚至能用来绕过大部分的反爬虫和验证码机制。
还是继续举个例子吧。17年底的时候,市场上很多人在关注18年的国债新发行计划的发布,这个更新的公告可在中债登主页→业务操作→发行与付息兑付→国债→发行计划中找到。在等待新公告的日子里,我们除了可以手工F5盯着网页刷新外,还可以使用Python爬虫,自动且实时对这个页面进行持续监控(同理可实时监控最新的各类公告、统计数据、以及央行微播的微博证监会发布的微博等),并在有新内容更新的时候,第一时间自动弹出一个提示:

啊,不好意思放错了,是这个提示:
从而,就能实现对最新信息的第一时间获取和响应。
沿用上次的思路,来观察一下这次网页的特点。首先,打开网页并依次点击“国债”、“发行计划”的按钮后,可以看到这是我们想要监控到的内容:
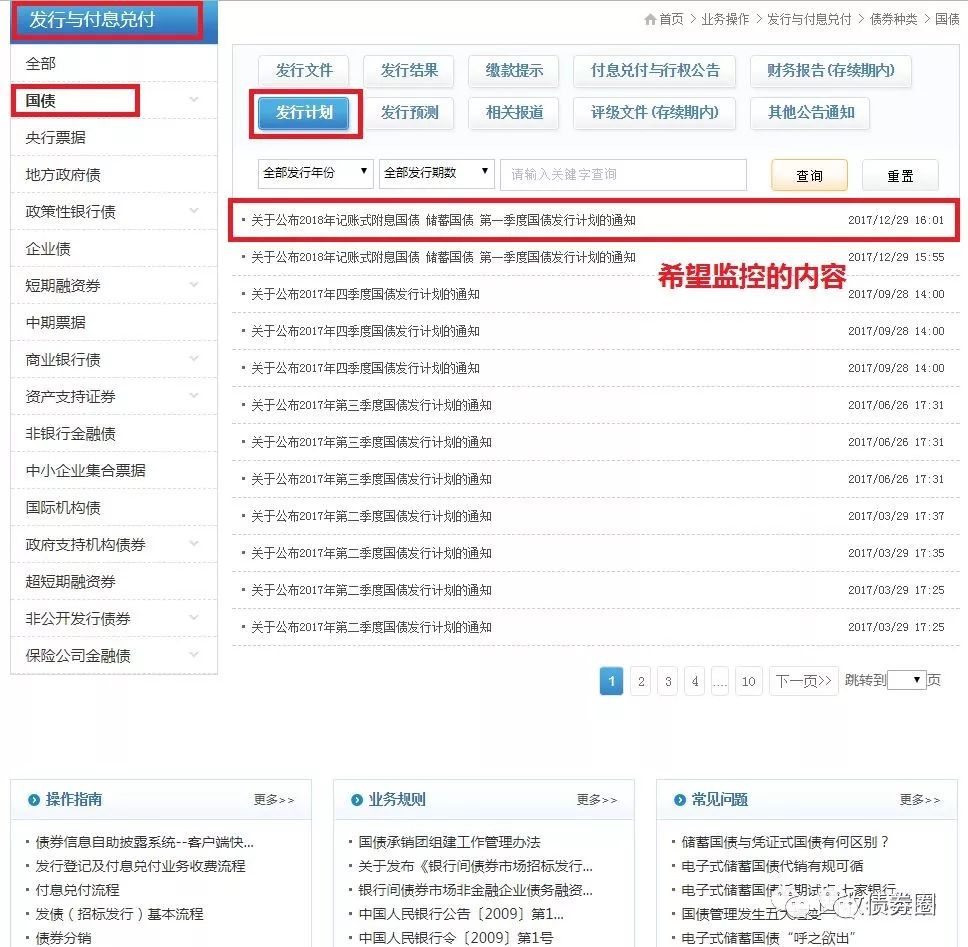
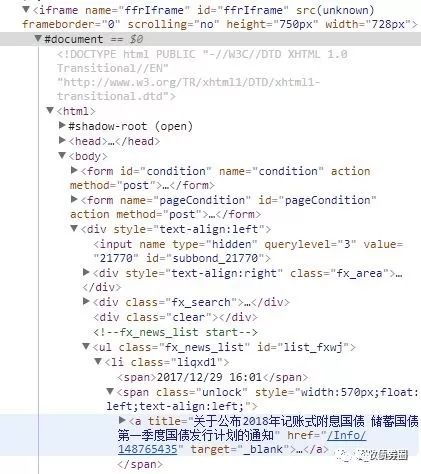
通过浏览器检查网页后,可知这个内容的具体位置,是在iframe这个tag下面的一个名为a的tag里title属性的一串文字(关于tag的说明,请翻阅上一篇):
如果直接套用上一篇的方法,在Python里用urllib+BeautifulSoup的组合来操作这个网页的话:
from bs4 import BeautifulSoup
from urllib import request
page = request.urlopen("http://www.chinabond.com.cn/Channel/21000")
soup = BeautifulSoup(page, "html.parser", from_encoding="gb18030")
print(soup.prettify())
Python解析到iframe下面的内容却是这样的:

上下对比可知,通过urllib+BeautifulSoup的方法,我们设想是能读取到iframe这个tag下面的大量内容,并找到其中一个名为a的tag中的最新公告信息。然而事实上是,Python在iframe里什么都读取不到,更遑论点击操作网页上的按钮读取不同的公告信息了。
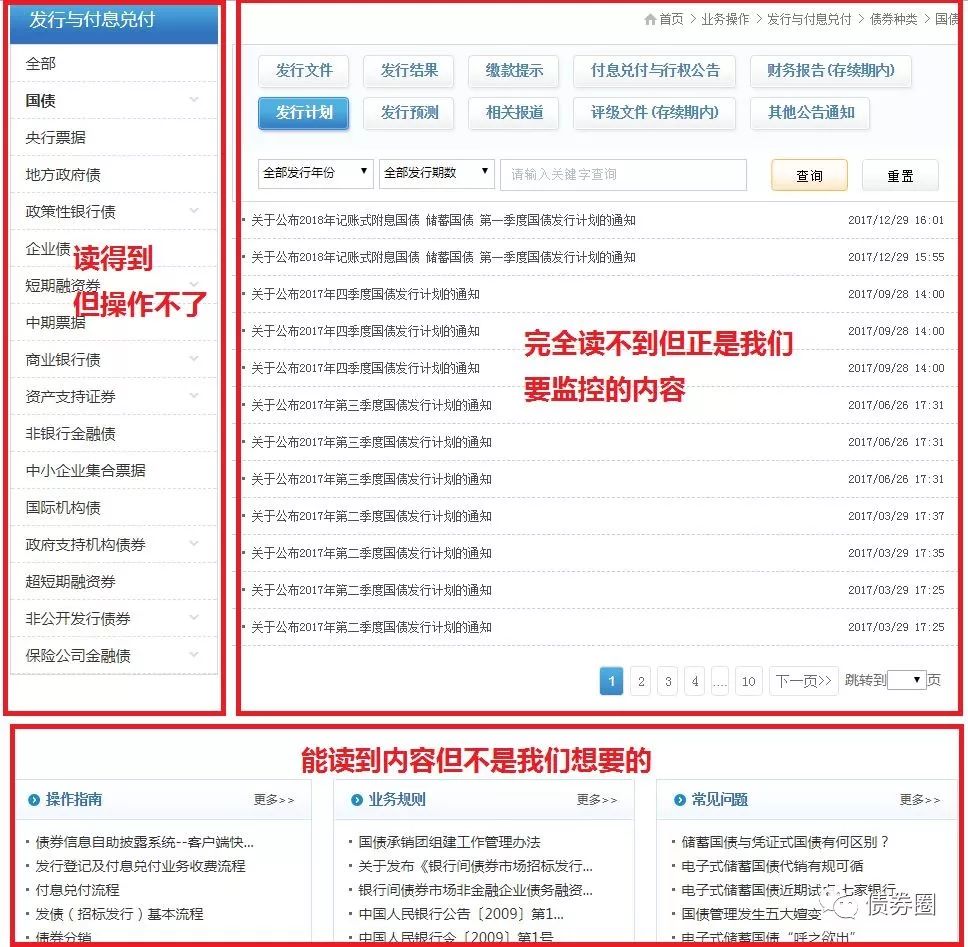
回到网页直观感受一下,上述的操作是得到这样的结果:
那种感觉就像,当我开始学会做蛋饼,才发现你,不吃早餐。
大家观察可以发现,这次的网址和上一篇的不一样:我们对这次的这个中债登发行公告页面内的各类点击操作(如点选“企业债”→“付息兑付与行权公告”),将使网页内容发生相对应的变化,但其地址栏里的实际网址http://www.chinabond.com.cn/Channel/21000,却不会随着我们在这个页面内的点击操作而变更。事实上,这是一个通过js父页面向iframe中子页面通信以实现内容加载的网页,其呈现的内容并不受网页地址所控制。
因此,这里要用到selenium + phantomjs + BeautifulSoup的方法,通过selenium 操作phantomjs浏览器,直接模拟浏览这个网页,并进行相关操作,以实现“平时所见所点即当下所爬”。在这个例子中,主要用到selenium的三个功能,一个是get('网址'),就是读取网页;一个是click(),就是点击按钮,用来对上图中“读得到但操作不了”的那些按钮进行点击;一个是switch_to.frame('frame名'),就是把爬取的目标移到上图中“完全读不到但正是我们要监控的内容”这块东西上面。剩下的就是用BeautifulSoup把这个最新的公告索引出来,具体方法与上一篇完全一致。
可以看出,其实这也就是我们平时自己查看网页的顺序操作,问题是不是又再度简单化了?所以我又已经帮大家写好了(看不全的代码可左右滑动屏幕查看,我的代码效率较低,供参考):
# 首先导入刚刚提到的两个包urllib和BeautifulSoup
# PhantomJS无需导入,是个exe文件,需提前安装,也可以直接用Chrome等其他浏览器,但中间解析tag的过程可能不同
from bs4 import BeautifulSoup
from selenium import webdriver
# time以使用时间相关函数,tkinter以实现弹窗提醒
import time
from tkinter import messagebox
# 定义监控爬取函数
def gz_fxjh_jk(old_news):
# 用selenium里的webdriver启用PhantomJS浏览器,注意要把路径修改成自己安装浏览器时所在位置
driver = webdriver.PhantomJS(executable_path='D:/Anaconda3/phantomjs/bin/phantomjs.exe')
# 读取中债登目标地址
driver.get('http://www.chinabond.com.cn/Channel/21000')
# 找到网页上“国债”按钮所对应的名称'span_21770',可以通过浏览器检查网页找到这个名称
elem = driver.find_element_by_id('span_21770')
# 点击这个按钮,进入国债公告查询页面
elem.click()
# 坑:点击后对应更新的页面是在另一个js框架里,需要切换frame以继续接下来的操作
driver.switch_to.frame('ffrIframe')
# 找到网页上“发行计划”按钮所对应的名称'fxjh'并点击,进入发行计划页面
elem = driver.find_element_by_id('fxjh').find_element_by_tag_name('a')
elem.click()
# 和之前一样,把读取到的网页信息拉进BeautifulSoup分析
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 把最新公告的内容拉取进来
news_position = soup.find('li', 'liqxd1')
latest_news_time = news_position.span.string
latest_news = news_position.find('a')['title']
# 比对新老公告,如果有更新则弹窗提醒
if latest_news == old_news:
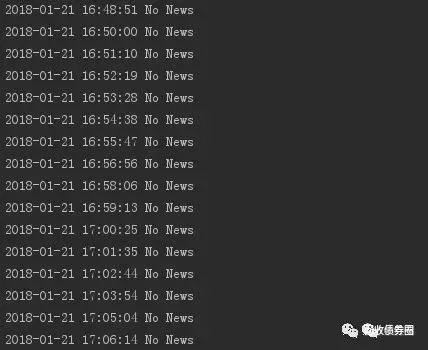
print(str(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))) + ' No News')
else:
print(messagebox.showinfo('最新公告更新', latest_news_time + '\n' + latest_news))
return latest_news
# 建立一个死循环,实现对页面的持续监控
latest_news = None
while True:
latest_news = gz_fxjh_jk(latest_news)
# 每次抓取完后等待60秒后再进行下一次抓取
time.sleep(60)
上述程序跑起来的时候,有新公告时Python会弹窗提醒:
没的话,Python还是会世世生生为你站岗:
这样,每当有什么新消息,我们就能跑得比西方记者还快了。
这种跨frame的操作会在很多网页上出现,比如网易云音乐的网页版播放页面就是这样的,大家可以拿来练手。
我们下一篇见。
END


文章评论