
在服务比较少的年代,一个系统的接口响应缓慢通常能够迅速被发现,但如今的微服务模块,大多具有规模大,依赖关系复杂等特性,错综复杂的网状结构使得我们不容易定位到某一个执行缓慢的接口。分布式的服务跟踪组件就是为了解决这一个问题。其次,它解决了另一个难题,在没有它之前,我们客户会一直询问:你们的系统有监控吗?你们的系统有监控吗?你们的系统有监控吗?现在,谢天谢地,他们终于不问了。是有点玩笑的成分,但可以肯定的一点是,实现全链路监控是保证系统健壮性的关键因子。
介绍 Spring Cloud Sleuth 和 Zipkin 的文章在网上其实并不少,所以我打算就我目前的系统来探讨一下,如何实现链路监控。全链路监控这个词意味着只要是不同系统模块之间的调用都应当被监控,这就包括了如下几种常用的交互方式:
1、Http协议,如RestTemplate,Feign,Okhttp3,HttpClient...
2、Rpc远程调用,如Motan,Dubbo,GRPC...
3、分布式Event,如RabbitMq,Kafka...
而我们项目目前混合使用了Http协议,Motan Rpc协议,所以本篇文章会着墨于实现这两块的链路监控
项目结构
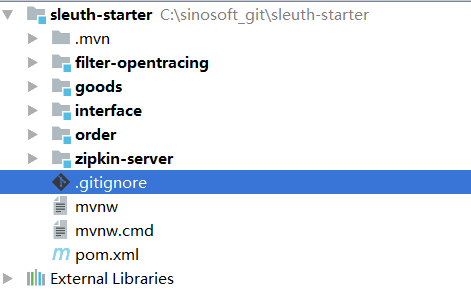
上面的项目结构是本次demo的核心结构,其中
1、zipkin-server作为服务跟踪的服务端,记录各个模块发送而来的调用请求,最终形成调用链路的报告。
2、order,goods两个模块为用来做测试的业务模块,分别实现了http形式和rpc形式的远程调用,最终我们会在zipkin-server的ui页面验证他们的调用记录。
i3、nterface存放了order和goods模块的公用接口,rpc调用需要一个公用的接口。
4、filter-opentracing存放了自定义的motan扩展代码,用于实现motan rpc调用的链路监控。
Zipkin 服务端
• 添加依赖
• 全部依赖
https://github.com/lexburner/sleuth-starter/blob/master/zipkin-server/pom.xml
• 核心依赖
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-storage-mysql</artifactId>
<version>1.28.0</version>
</dependency>
zipkin-autoconfigure-ui提供了默认了UI页面,zipkin-storage-mysql选择将链路调用信息存储在mysql中,更多的选择可以有 elasticsearch,cassandra。
zipkin-server/src/main/resources/application.yml
spring:
application:
name: zipkin-server
datasource:
url: jdbc:mysql://localhost:3306/zipkin
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
zipkin:
storage:
type: mysql
server:
port: 9411
创建启动类
@SpringBootApplication
@EnableZipkinServer
public class ZipkinServerApp {
@Bean
public MySQLStorage mySQLStorage(DataSource datasource) {
return MySQLStorage.builder().datasource(datasource).executor(Runnable::run).build();
}
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApp.class, args);
}
}
当前版本在手动配置数据库之后才不会启动报错,可能与版本有关。mysql相关的脚本可以在此处下载:mysql初始化脚本。(https://github.com/lexburner/sleuth-starter/blob/master/zipkin-server/src/main/resources/mysql.sql)
zipkin-server单独启动后,就可以看到链路监控页面了,此时由于没有收集到任何链路调用记录,显示如下:

HTTP 链路监控
编写order和goods两个服务,在order暴露一个http端口,在goods中使用RestTemplate远程调用,之后查看在zipkin服务端查看调用信息。
首先添加依赖,让普通的应用具备收集和发送报告的能力,这一切在spring cloud sleuth的帮助下都变得很简单
• 添加依赖
• 全部依赖
• 核心依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
spring-cloud-starter-zipkin依赖内部包含了两个依赖,等于同时引入了spring-cloud-starter-sleuth,spring-cloud-sleuth-zipkin两个依赖。名字特别像,注意区分。
以order为例介绍配置文件
order/src/main/resources/application.yml
spring:
application:
name: order # 1
zipkin:
base-url: http://localhost:9411 # 2
sleuth:
enabled: true
sampler:
percentage: 1 # 3
server:
port: 8060
<1> 指定项目名称可以方便的标记应用,在之后的监控页面可以看到这里的配置名称
<2> 指定zipkin的服务端,用于发送链路调用报告
<3> 采样率,值为[0,1]之间的任意实数,顾名思义,这里代表100%采集报告。
编写调用类
服务端order
@RestController
@RequestMapping("/api")
public class OrderController {
Logger logger = LoggerFactory.getLogger(OrderController.class);
@RequestMapping("/order/{id}")
public MainOrder getOrder(@PathVariable("id") String id) {
logger.info("order invoking ..."); //<1>
return new MainOrder(id, new BigDecimal(200D), new Date());
}
}
客户端goods
public MainOrder test(){
ResponseEntity<MainOrder> mainOrderResponseEntity = restTemplate.getForEntity("http://localhost:8060/api/order/1144", MainOrder.class);
MainOrder body = mainOrderResponseEntity.getBody();
return body;
}
<1> 首先观察这一行日志在控制台是如何输出的
2017-11-08 09:54:00.633 INFO [order,d251f40af64361d2,e46132755dc395e1,true] 2780 --- [nio-8060-exec-1] m.c.sleuth.order.web.OrderController : order invoking ...
比没有引入sleuth之前多了一些信息,其中order,d251f40af64361d2,e46132755dc395e1,true分别代表了应用名称,traceId,spanId,当前调用是否被采集,关于trace,span这些专业词语,强烈建议去看看Dapper这篇论文,有很多中文翻译版本,并不是想象中的学术范,非常容易理解,很多链路监控文章中的截图都来自于这篇论文,我在此就不再赘述概念了。
紧接着,回到zipkin-server的监控页面,查看变化



到这里,Http监控就已经完成了,如果你的应用使用了其他的Http工具,如okhttp3,也可以去[opentracing,zipkin相关的文档中寻找依赖。
RPC 链路监控
虽说spring cloud是大势所趋,其推崇的http调用方式也是链路监控的主要对象,但不得不承认目前大多数的系统内部调用仍然是RPC的方式,至少我们内部的系统是如此,由于我们内部采用的RPC框架是weibo开源的motan,这里以此为例,介绍RPC的链路监控。motan使用SPI机制,实现了对链路监控的支持,https://github.com/weibocom/motan/issues/304这条issue中可以得知其加入了opentracing标准化追踪。但目前只能通过自己添加组件的方式才能配合spring-cloud-sleuth使用,下面来看看实现步骤。
filter-opentracing
实现思路:引入SleuthTracingFilter,作为全局的motan过滤器,给每一次motan的调用打上traceId和spanId,并编写一个SleuthTracingContext,持有一个SleuthTracerFactory工厂,用于适配不同的Tracer实现。
具体的实现可以参考文末的地址
order/src/main/resources/META-INF/services/com.weibo.api.motan.filter.Filter
com.weibo.api.motan.filter.sleuth.SleuthTracingFilter
添加一行过滤器的声明,使得项目能够识别
配置 SleuthTracingContext
@Bean
SleuthTracingContext sleuthTracingContext(@Autowired(required = false) org.springframework.cloud.sleuth.Tracer tracer){
SleuthTracingContext context = new SleuthTracingContext();
context.setTracerFactory(new SleuthTracerFactory() {
@Override
public org.springframework.cloud.sleuth.Tracer getTracer() {
return tracer;
}
});
return context;
}
使用spring-cloud-sleuth的Tracer作为motan调用的收集器
为服务端和客户端配置过滤器
basicServiceConfigBean.setFilter("sleuth-tracing");
basicRefererConfigBean.setFilter("sleuth-tracing");
编写调用测试类
order作为客户端
@MotanReferer
GoodsApi goodsApi;
@RequestMapping("/goods")
public String getGoodsList() {
logger.info("getGoodsList invoking ...");
return goodsApi.getGoodsList();
}
goods作为服务端
@MotanService
public class GoodsApiImpl implements GoodsApi {
Logger logger = LoggerFactory.getLogger(GoodsApiImpl.class);
@Override
public String getGoodsList() {
logger.info("GoodsApi invoking ...");
return "success";
}
}
查看调用关系


第一张图中,使用前缀http和motan来区别调用的类型,第二张图中,依赖变成了双向的,因为一开始的http调用goods依赖于order,而新增了motan rpc调用之后order又依赖于goods。
总结
系统间交互的方式除了http,rpc,还有另外的方式如mq,以后还可能会有更多的方式,但实现的监控的思路都是一致的,即如何无侵入式地给调用打上标签,记录报告。Dapper给实现链路监控提供了一个思路,而OpenTracing为各个框架不同的调用方式提供了适配接口....Spring Cloud Sleuth则是遵循了Spring一贯的风格,整合了丰富的资源,为我们的系统集成链路监控提供了很大的便捷性。
关于motan具体实现链路监控的代码由于篇幅限制,将源码放在了我的github中,如果你的系统使用了motan,可以用于参考:https://github.com/lexburner/sleuth-starter
参考
《Spring Cloud微服务实战》-- 翟永超
黄桂钱老师的指导

放弃 Dubbo,选择 Spring Cloud 微服务架构实践与经验总结


文章评论