微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第二
【Python】:排名第三
【算法】:排名第四
我们会再接再厉
成为全网优质的技术类公众号
「情感极性分析」是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于情感词典的方法(本次内容)和基于机器学习的方法(下次内容)。
1. 基于情感词典的文本情感极性分析
笔者是通过情感打分的方式进行文本情感极性判断,score > 0判断为正向,score < 0判断为负向。
1.1 数据准备
1.1.1 情感词典及对应分数
词典来源于BosonNLP数据下载
http://bosonnlp.com/dev/resource 的情感词典,来源于社交媒体文本,所以词典适用于处理社交媒体的情感分析。
词典把所有常用词都打上了唯一分数有许多不足之处。
▶ 不带情感色彩的停用词会影响文本情感打分。
▶ 由于中文的博大精深,词性的多变成为了影响模型准确度的重要原因。一种情况是同一个词在不同的语境下可以是代表完全相反的情感意义,用笔者模型预测偏差最大的句子为例(来源于朋友圈文本):
有车一族都用了这个宝贝,后果很严重哦[偷笑][偷笑][偷笑]1,交警工资估计会打5折,没有超速罚款了[呲牙][呲牙][呲牙]2,移动联通公司大幅度裁员,电话费少了[呲牙][呲牙][呲牙]3,中石化中石油裁员2成,路痴不再迷路,省油[悠闲][悠闲][悠闲]5,保险公司裁员2成,保费折上折2成,全国通用[憨笑][憨笑][憨笑]买不买你自己看着办吧[调皮][调皮][调皮]
里面严重等词都是表达的相反意思,甚至整句话一起表示相反意思,不知死活的笔者还没能深入研究如何用词典的方法解决这类问题,但也许可以用机器学习的方法让神经网络进行学习能够初步解决这一问题。
另外,同一个词可作多种词性,那么情感分数也不应相同,例如:
这部电影真垃圾
垃圾分类,很明显在第一句中垃圾表现强烈的贬义,而在第二句中表示中性,单一评分对于这类问题的分类难免有失偏颇。
1.1.2 否定词词典
否定词的出现将直接将句子情感转向相反的方向,而且通常效用是叠加的。常见的否定词:不、没、无、非、莫、弗、勿、毋、未、否、别、無、休、难道等。
1.1.3 程度副词词典
既是通过打分的方式判断文本的情感正负,那么分数绝对值的大小则通常表示情感强弱。既涉及到程度强弱的问题,那么程度副词的引入就是势在必行的。词典可从《知网》情感分析用词语集(beta版)
http://www.keenage.com/download/sentiment.rar
词典内数据格式可参考如下格式,即共两列,第一列为程度副词,第二列是程度数值,> 1表示强化情感,< 1表示弱化情感。

1.1.4 停用词词典
中科院计算所中文自然语言处理开放平台发布了有1208个停用词的中文停用词表,
http://www.datatang.com/data/43894
也有其他不需要积分的下载途径。
http://www.hicode.cc/download/view-software-13784.html
1.2 数据预处理
1.2.1 分词
即将句子拆分为词语集合,结果如下:
e.g. 这样/的/酒店/配/这样/的/价格/还算/不错
Python常用的分词工具(在此笔者使用Jieba进行分词):
结巴分词 Jieba
Pymmseg-cpp
Loso
smallseg
1.2.2 去除停用词
遍历所有语料中的所有词语,删除其中的停用词
e.g. 这样/的/酒店/配/这样/的/价格/还算/不错
--> 酒店/配/价格/还算/不错
1.3 构建模型
1.3.1 将词语分类并记录其位置
将句子中各类词分别存储并标注位置。
1.3.2 计算句子得分
在此,简化的情感分数计算逻辑:所有情感词语组的分数之和
定义一个情感词语组:两情感词之间的所有否定词和程度副词与这两情感词中的后一情感词构成一个情感词组,即notWords + degreeWords + sentiWords,例如不是很交好,其中不是为否定词,很为程度副词,交好为情感词,那么这个情感词语组的分数为:
finalSentiScore = (-1) ^ 1 * 1.25 * 0.747127733968
其中1指的是一个否定词,1.25是程度副词的数值,0.747127733968为交好的情感分数。
1.4 模型评价
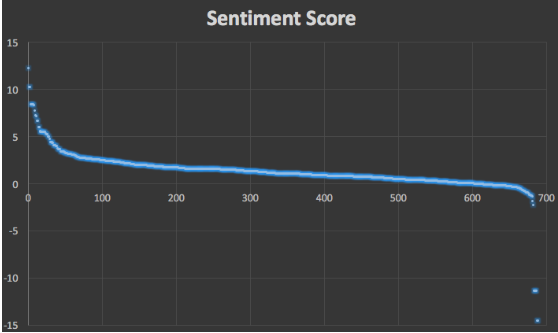
其中大多数文本被判为正向文本符合实际情况,且绝大多数文本的情感得分的绝对值在10以内,这是因为笔者在计算一个文本的情感得分时,以句号作为一句话结束的标志,在一句话内,情感词语组的分数累加,如若一个文本中含有多句话时,则取其所有句子情感得分的平均值。
然而,这个模型的缺点与局限性也非常明显:
首先,段落的得分是其所有句子得分的平均值,这一方法并不符合实际情况。正如文章中先后段落有重要性大小之分,一个段落中前后句子也同样有重要性的差异。
其次,有一类文本使用贬义词来表示正向意义,这类情况常出现与宣传文本中,还是那个例子:
有车一族都用了这个宝贝,后果很严重哦[偷笑][偷笑][偷笑]1,交警工资估计会打5折,没有超速罚款了[呲牙][呲牙][呲牙]2,移动联通公司大幅度裁员,电话费少了[呲牙][呲牙][呲牙]3,中石化中石油裁员2成,路痴不再迷路,省油[悠闲][悠闲][悠闲]5,保险公司裁员2成,保费折上折2成,全国通用[憨笑][憨笑][憨笑]买不买你自己看着办吧[调皮][调皮][调皮]2980元轩辕魔镜带回家,推广还有返利[得意]
Score Distribution中得分小于-10的几个文本都是与这类情况相似,这也许需要深度学习的方法才能有效解决这类问题,普通机器学习方法也是很难的。
对于正负向文本的判断,该算法忽略了很多其他的否定词、程度副词和情感词搭配的情况;用于判断情感强弱也过于简单。
投稿、商业合作
请发邮件到:[email protected]
关注者
从1到18000+
我们每天都在进步

文章评论