新智元报道
新智元启动新一轮大招聘:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。
简历投递:j[email protected]
HR 微信:13552313024
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。
加盟新智元,与人工智能业界领袖携手改变世界。
【新智元导读】今天,机器学习诸多理论的主要奠基人、美国三院院士 Michael I. Jordan受聘为清华大学访问教授,同时发表主题报告。Jordan认为,大数据的增长对传统的数据科学理论提出了改变的需求,特别是统计学和计算学的相关理论,应该呈融合式的发展。Jordan 特别提到,要在明年1月正式发布他们研究室的分布式机器学习框架 Ray,集统计推理、机器学习、大数据处理、计算等为一体,超越 Spark。

12月20日,清华大学正式宣布聘请计算机科学机器学习领域顶级学者 Michael I. Jordan 为访问教授,聘请仪式在清华大学主楼进行。

除了清华大学校领导,来自人大、北大等高校的代表,以及企业界代表——百度副总裁王海峰出席了聘请仪式。
Michael I. Jordan 是美国国家科学院院士、美国国家工程院院士以及美国艺术与科学院院士。Jordan教授也是美国加州大学伯克利分校 Pehong Chen 特聘教授,担任大数据实验室(AMPLab)共同主任、统计人工智能实验室(SAIL)主任、统计系系主任。长期引领着机器学习、统计学的理论、方法与系统研究,是贝叶斯网络、概率图模型、层次随机过程等多个重要方向的主要奠基者之一,也是统计学与机器学习交叉融合的主要推动者之一。
2016年4月,位于美国西雅图的艾伦人工智能研究院(AI2)名叫 Semantic Scholar 的程序基于400万份计算机领域的论文,计算出了最有影响力的学者排名。其中在机器学习领域的Michael I. Jordan 以1185的得分位居第一。

2015年秋天,由微软联合创始人保罗·艾伦创立的艾伦人工智能研究所(Allen Institute for Artificial Intelligence)发布了一款名为Semantic Scholar的搜索服务,其瞄准的竞争对手是Google Scholar、PubMed和其他在线学术搜索引擎。这项计划最初的目标是让这款由人工智能驱动的搜索引擎能在一定程度上真正理解搜索出来的论文。但后来,Semantic Scholar有了一个新目标:衡量一位科学家或一所研究机构对之后研究的影响。
根据Science报道,Semantic Scholar将不仅仅为论文排名,也会根据某一影响因素为作者、机构排名。例如,Semantic Scholar发现,MIT是当今计算机科学领域影响力最大的机构——这并不奇怪。不过,谁是计算机科学领域影响力最大的科学家呢?
如果你要看原始引用次数最高的人,那么计算机科学领域当前顶尖科学家是加州大学伯克利分校的Scott Shenker。但使用Semantic Scholar得出的结果是,影响力最大的是Shenker的同事——同样在加州大学伯克利分校工作的Michael I. Jordan。Jordan是人工智能领域的先驱,但他的名字极少为外人所知。艾伦人工智能研究所所长、Semantic Scholar的研发负责人Oren Etzioni戏称其为“机器学习领域的迈克尔·乔丹”。
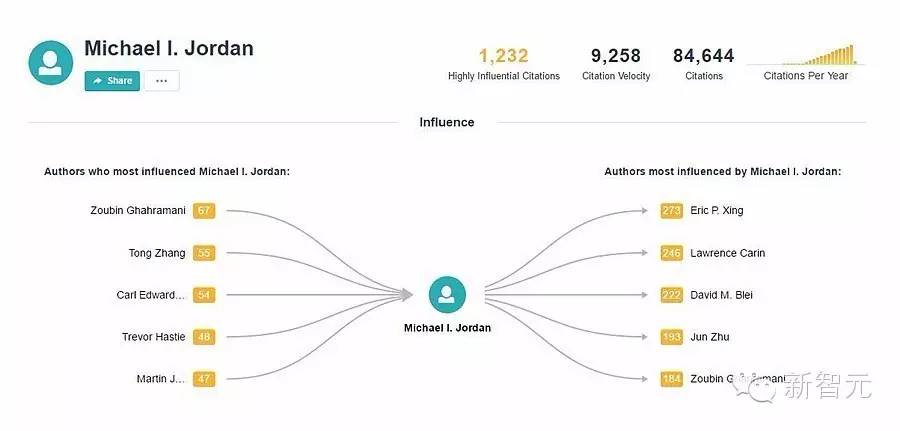
使用Semantic Scholar搜索Michael I. Jordan的结果。来源:semanticscholar.org
聘请仪式结束后,Michael I. Jordan 现场作了题为《On Computational Thinking, Inferential Thinking and Data Science》的报告分享。
科学和技术界中数据集大小和规模的快速增长,已经创造了关于数据科学的、新颖的基础性视角的需求,这种视角应该是融合了推理(Inferential)和计算机科学的。
这些领域中传统的视角和思路不足以解决“大数据”中凸显的难题,这显然是由于在基础性的层面,二者存在突出的分歧。在计算机科学中,数据点数量的增长是”复杂性“的来源,必须通过算法或者硬件来训练。而在统计学中,数据点数量的增长是”简单性“的来源,它能让推理在总体上变得更强大,引出渐进式的结果。
在形式层上,核心的统计学理论中缺乏计算机理论中的概念,比如“runtime”(运行时)的作用,而在核心的计算理论中,又缺乏统计学概念,比如“risk”的作用。二者之间的差异(Gap) 显而易见。
演讲展示了几个研究,用以为计算学和统计学搭建起桥梁,其中包括在隐私和交流限制下的推理问题,以及推理的速度和准确率之间达成平衡的方法。
值得一提的是,在演讲完后的问答环节中,有两位提问的人总想让 Jordan 在图模型(graph model)和深度神经网络(DNN)上选择一种。不过,Jordan 认为,两种方法都同样属于将统计融入了计算理论,因此——他不做选择。
此前,新智元特邀编辑小猴机器人 2011 年曾对话 Michael I. Jordan 教授,并在 InfoQ 发表文章《对话机器学习大神 Michael Jordan:深度模型》。
在 5 年以前,乔丹教授就认为,统计或者机器学习需要更加深入的与计算机科学系统和数据库接触,并不仅仅与具有人工智能的人。这一直是过去的几十年里正在进行的,并且直到现在仍然保持着“机器学习”的热点。在当时的采访中,小猴机器人了解到,乔丹教授从2006年到2011年在伯克利分校“RAD实验室”,直到现在在“AMP实验室”,在这段时间里一直都做着这样的事情。
采访中提到,乔丹教授相对于术语“神经网络”用法的重塑形象,更偏向于“深度学习”。在其他的工程领域里,利用流水线、流程图和分层体系结构来构建复杂系统的想法非常根深蒂固。而在机器学习的领域,尤其应该研究这些原则来构建系统。这个词“深”仅仅意味着——分层,乔丹教授深深的希望这个语言最终演变成如此简单的文字。他希望并期待看到更多的人开发使用其他类型模块、管道的体系结构,并不仅仅限制在“神经元”的层次。
神经科学——在接下来几百年的重大科学领域之一——我们仍然不是很了解在神经网络中想法是如何产生的,仍然看不到作为思想的主要产生器的神经科学,如何能够在细节上打造推理和决策系统。相比之下,计算机领域的一些假设,比如“并行是好的”或者“分层是好的”,已经足以支撑人们对大脑工作机制的理解。
乔丹教授补充举例道,在神经网络的早期他还是一个博士研究生,反向传播算法还没有被发现,重点在Hebb规则和其他的“神经合理”的算法,任何大脑不能做的事情都被避免了。他们需要变得很纯粹来发现人们思考的新形式。接着Dave Rumelhart开始探索反向传播算法——这显然是跳出于神经合理约束的——突然这个系统变得如此强大。这对他产生了很深刻的影响。这告诉我们,不要对主题和科学的模型强加人工的限制,因为我们仍然还不懂。
乔丹教授的理解是,许多“深度学习成功案例”涉及了监督学习(如反向传播算法)和大量的数据。涉及到大量线性度、光滑非线性以及随机梯度下降的分层结构似乎能够记住大量模式的数字,同时在模式之间插值非常光滑。此外,这种结构似乎能够放弃无关紧要的细节,特别是如果在合适的视觉领域加上权重分担。它还有一些总体上的优点总之是一个很有吸引力的组合。但是,这种组合并没有“神经”的感觉,尤其是需要大量的数据标签。
事实上,无监督学习一直被认为是圣杯。这大概是大脑擅长什么,和真正需要什么来建立真的“大脑启发式电脑”。但是在如何区分真正的进步和炒作上还存有困难。根据乔丹的理解,至少在视觉方面,非监督学习的想法并没有对最近的一些结果负责,很多都是机遇大量数据集的监督训练的结果。
接近非监督学习的一种方式是将好的“特征”或者“表示”的各种正式特点写下来,并且将他们与现实世界相关的各种假设捆绑在一起。这在神经网络文学上已经做了很久,在深度学习工作背景下的也做出了更多的工作。但是乔丹认为,要走的路是将那些正式的特征放进放进优化函数或者贝叶斯先验,并且制定程序来明确优化整合它们。这将是很困难的,这是一个持续的优化的问题。在一些近期的深度学习工作中,有一个不同的策略——使用自己喜欢的神经网络结构来分析一些数据,并且说“看,这表达了那些想要的、并没有包括进去的性质”。这是旧式的神经网络推理,它被认为仅仅是“神经”,仅仅包含了某种特殊的调料。这个逻辑是完全没有用的。
最后,乔丹教授谈到了哲学的层面,他认为神经网络是工具箱中重要工具之一。但当他被业界咨询的时候,却很少提到那种工具。工业界里人往往期望解决一系列的问题,通常不涉及上文所说的神经网络的“模式识别”的问题。比如说如下这些问题:
(1) 该怎样建立一段时间内的预算的模型,能够让我得到想要精确程度的结果,并且不管我有多少数据?
(2) 怎样才能获得我的数据库所有查询的表现的有意义的错误信息或者其他衡量方法的信息?
(3) 怎样才能与数据库思维(如连接)合并统计思维,以使我能够有效地清除数据和合并异构数据源?
(4) 该如何可视化数据,一般我该如何减少我地数据并且将我的推论展示给别人,让他们理解这是怎么回事?
(5) 该如何做诊断,这样我就不会推出一个有缺陷地系统,或者找出一个现有地系统被损坏了?
(6) 该如何处理非平稳性?
(7) 该如何做一些有针对性地实验,其中合并了我巨大地现有数据集,以使我能够断言一些变量有一些因果关系?
以下是今天 Jordan 教授清华大学演讲部分演讲PPT(编注:部分PPT标题显示不完整,原本如此,非拍摄或后期处理原因):

Jordan 从一个职位描述讲起,介绍大数据带来的挑战,引出演讲主题:“大数据”时代同时需要计算思维和推理思维。


计算思维指的是:提取、建模、扩展性、鲁棒性等等
推理思维指的是:思考数据背后的真实世界现象;考虑抽样模型;开发能从数据“回馈”到潜在现象的程序。


隐私与推理:差分隐私
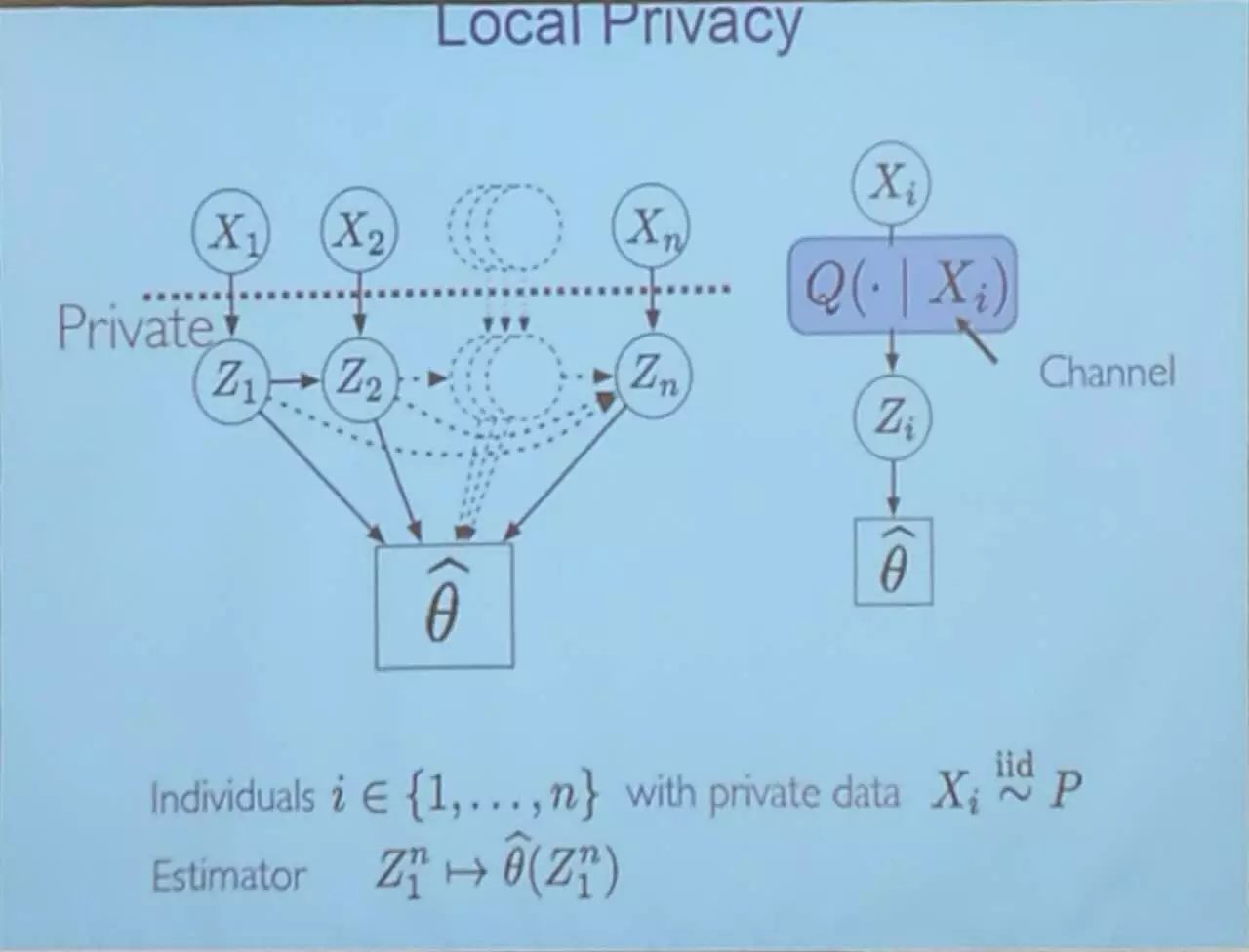


计算与推理
-
推理质量与经典的计算资源,比如时间和空间,如何平衡?
-
很难!

计算与推理的机制和边界

Jordan 所在研究机构与合作伙伴

大数据软件的增长情况


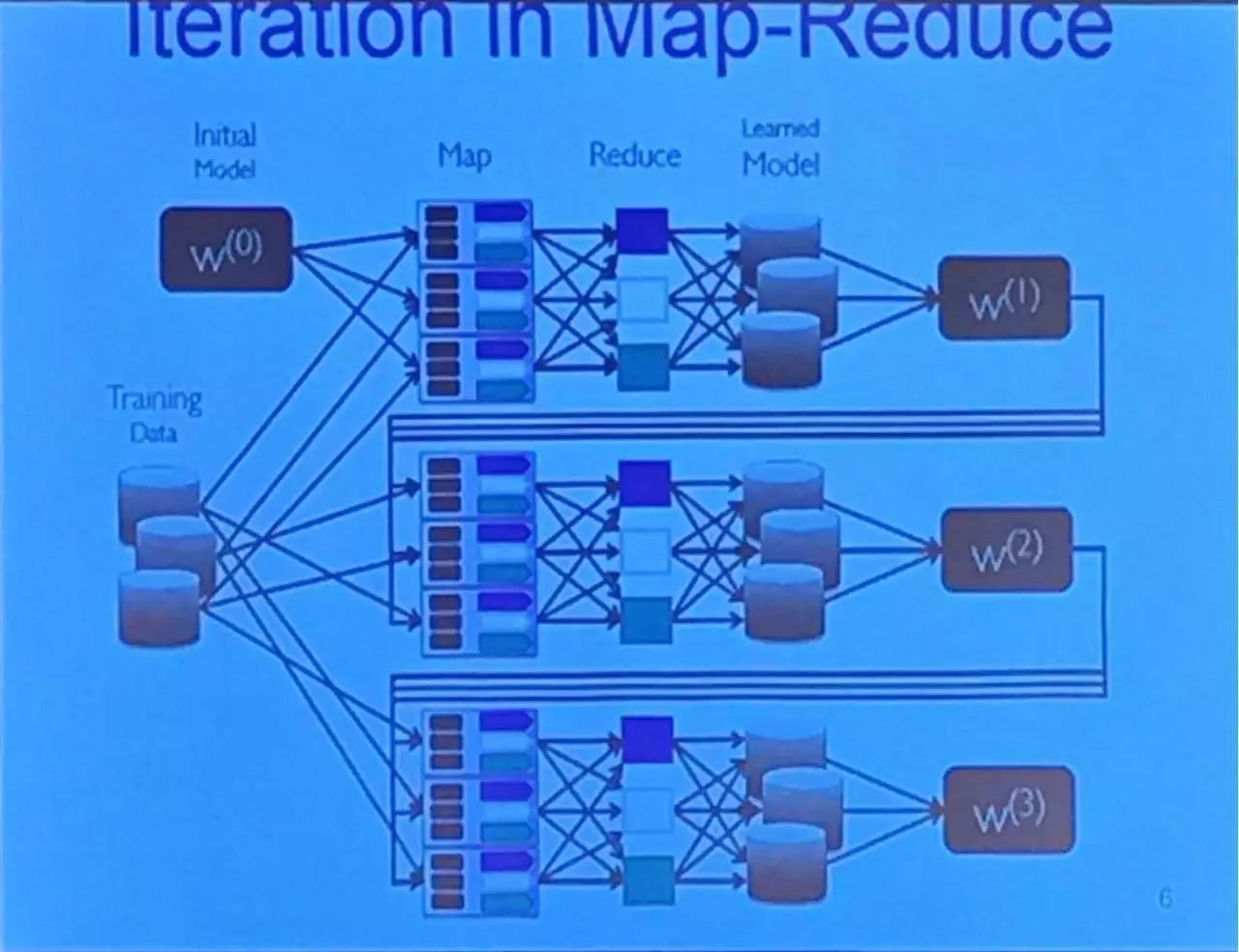
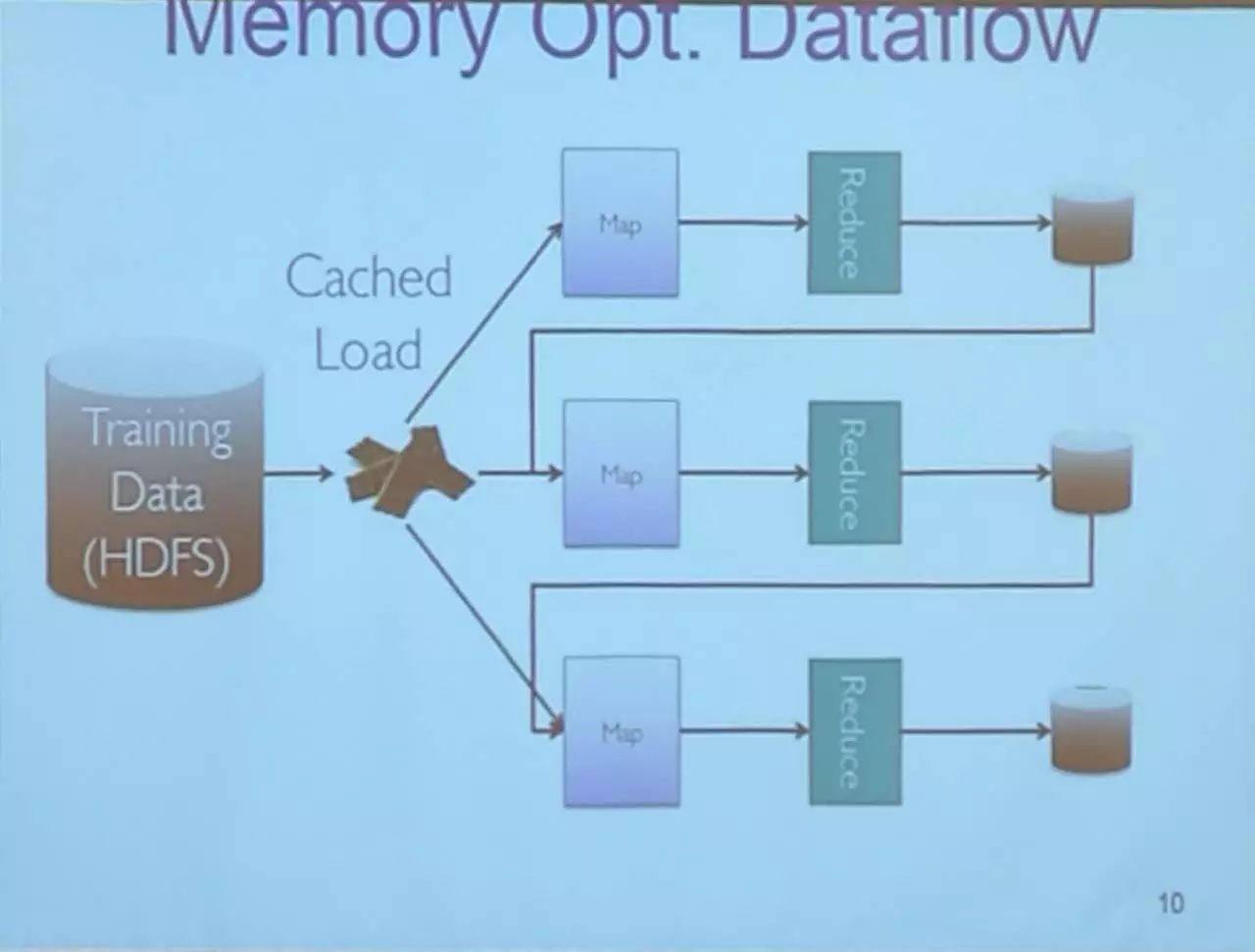
Spark 之后的下一个平台:Ray
Jordan 介绍说,他们研究室开发的 Ray 将于明年一月份左右发布。Ray 集统计推理、机器学习、大数据处理、计算等为一体。


动力源于构建更好的分布式机器学习框架

目标:
在单机上运行相同的代码和簇;对既有的代码进行最小化的修正,让其变得可分布;有效地支持大量的小任务;在任务间有效地分享数据
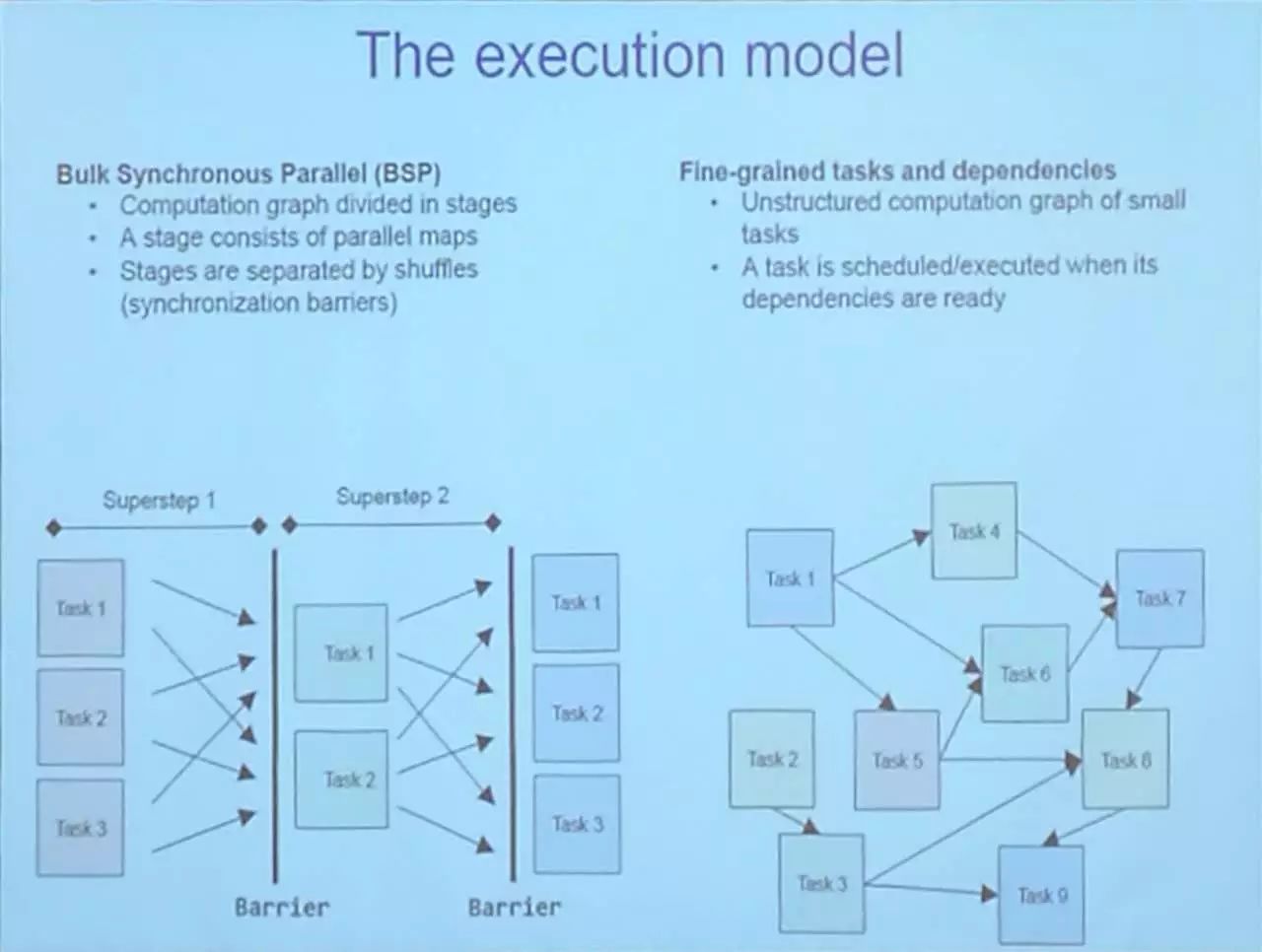
运行模型

例子:递归神经网络计算的依存图

代码运行案例
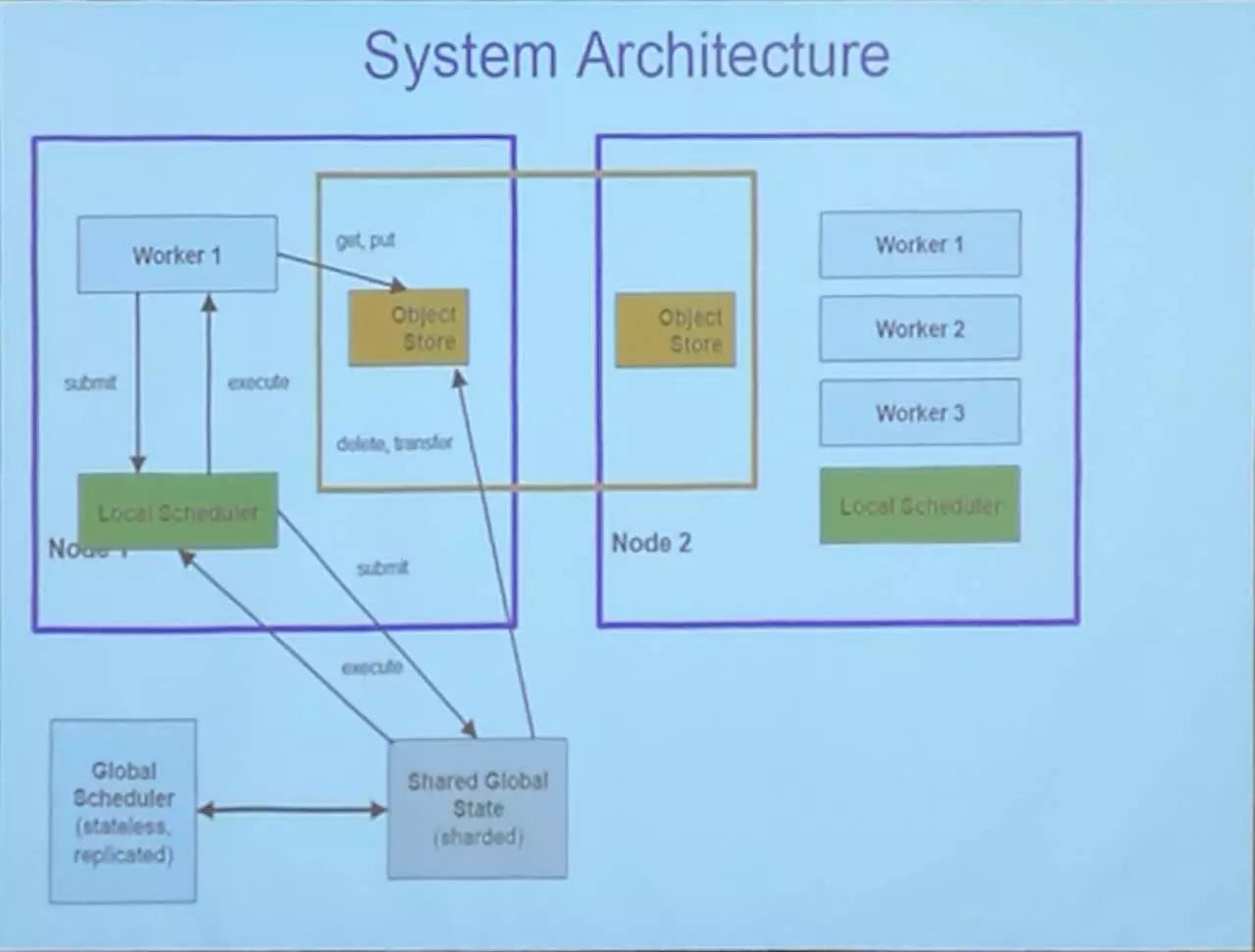
系统架构


应用:商品检测、欺诈检测、认知助手、物联网。
特点:低延迟、个性化和快速变化。
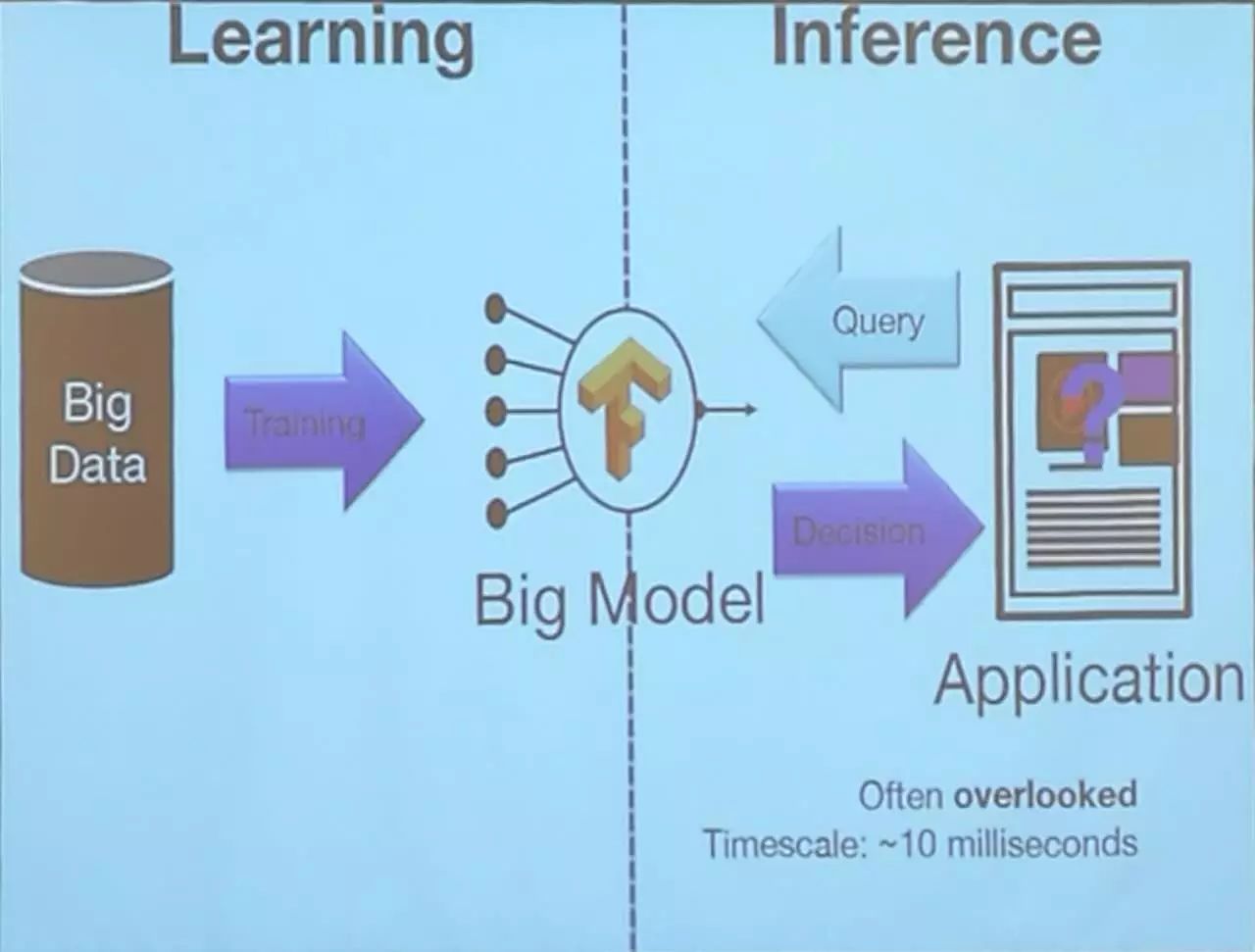

结语:数据变得越来越多,越来越大,计算和推理领域应该在基础层面有更多的融合。
文中部分内容来自 InforQ 《对话机器学习大神Michael Jordan:深度模型》,发布时有改动(原文链接:http://www.infoq.com/cn/news/2014/09/depth-model)
(责编:WF)
新智元招聘
职位 运营总监
职位年薪:36- 50万(工资+奖金)
工作地点:北京-海淀区
所属部门:运营部
汇报对象:COO
下属人数:2人
年龄要求:25 岁 至 35 岁
性别要求:不限
工作年限:3 年以上
语 言:英语6级(海外留学背景优先)
职位描述
-
负责大型会展赞助商及参展商拓展、挖掘潜在客户等工作,人工智能及机器人产业方向
-
擅长开拓市场,并与潜在客户建立良好的人际关系
-
深度了解人工智能及机器人产业及相关市场状况,随时掌握市场动态
-
主动协调部门之间项目合作,组织好跨部门间的合作,具备良好的影响力
-
带领团队完成营业额目标,并监控管理项目状况
-
负责公司平台运营方面的战略计划、合作计划的制定与实施
岗位要求
-
大学本科以上学历,硕士优先,要求有较高英语沟通能力
-
3年以上商务拓展经验,有团队管理经验,熟悉商务部门整体管理工作
-
对传统全案公关、传统整合传播整体方案、策略性整体方案有深邃见解
-
具有敏锐的市场洞察力和精确的客户分析能力、较强的团队统筹管理能力
-
具备优秀的时间管理、抗压能力和多任务规划统筹执行能力
-
有广泛的TMT领域人脉资源、有甲方市场部工作经验优先考虑
-
有媒体广告部、市场部,top20公关公司市场拓展部经验者优先
新智元欢迎有志之士前来面试,更多招聘岗位请访问新智元公众号。


文章评论