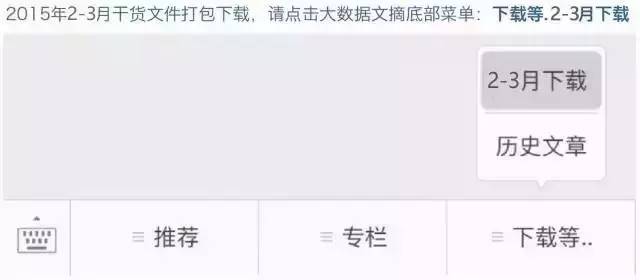
作者:赵一鸣 摘自:微信公号“沙漠之鹰”
大数据文章-数据抓取交流学习群成立啦!
想要跟大神级别的本文作者同群交流学习爬虫?
想要跟小伙伴一起组团打怪爬下某网站并交流心得?
想获取第一手数据抓取咨询和工具?
点击文末“阅读原文”报名加入
◆ ◆ ◆
不少朋友都会问:几十万条租房,二手房,薪酬,乃至天气数据都是从哪里来的?其实这些数据在十几分钟内就可以采集到!
一般我会回答,我用专门的工具,无需编程也能快速抓取。之后肯定又会被问,在哪里能下载这个工具呢?
最近比较忙乱,说好的一大堆写作任务都还没有完成。授人以鱼不如授人以渔,我做了一个决定,将这套软件全部开源到GitHub。
免费使用,开放源代码! 从此以后,估计很多做爬虫的工程师要失业了。。。因为我的目标是让普通人也能使用!
这篇文章介绍爬虫大概的原理,文末会有程序地址。
◆ ◆ ◆
什么是爬虫
什么是爬虫
互联网是一张大网,采集数据的小程序可以形象地称之为爬虫或者蜘蛛。
爬虫的原理很简单,我们在访问网页时,会点击翻页按钮和超链接,浏览器会帮我们请求所有的资源和图片。所以,你可以设计一个程序,能够模拟人在浏览器上的操作,让网站误认为爬虫是正常访问者,它就会把所需的数据乖乖送回来。
爬虫分为两种,一种像百度(黑)那样什么都抓的搜索引擎爬虫。另一种就是开发的,只精确地抓取所需的内容:比如我只要二手房信息,旁边的广告和新闻一律不要。
爬虫这样的名字并不好听,所以我给这套软件起名为Hawk,指代为"鹰",能够精确,快速地捕捉猎物。 基本不需编程,通过图形化拖拽的操作来快速设计爬虫,有点像Photoshop。它能在20分钟内编写大众点评的爬虫(简化版只需3分钟),然后让它运行就好啦、
下面是使用Hawk抓取二手房的视频,建议在wifi环境下观看:
◆ ◆ ◆
自动将网页导出为Excel
那么,一个页面那么大,爬虫怎么知道我想要什么呢?
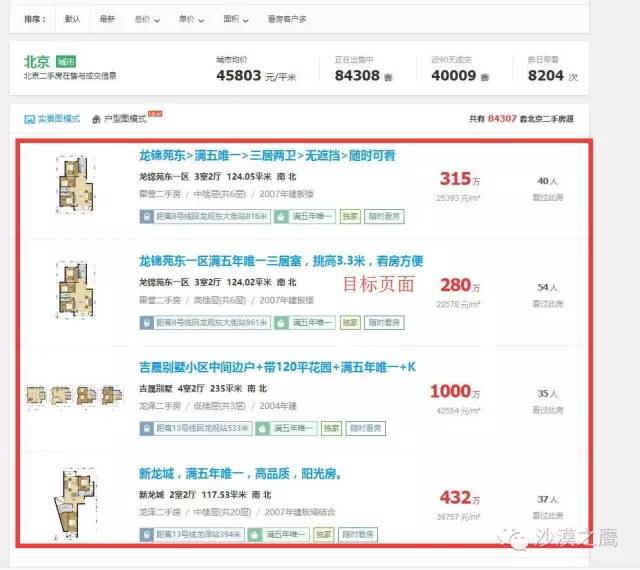
人当然可以很容易地看出,上图的红框是二手房信息,但机器不知道。
网页是一种有结构的树,而重要信息所在的节点,往往枝繁叶茂。 举个不恰当的比方,一大家子人构成树状族谱,谁最厉害?当然是:
-
孩子多,最好一生20个
-
孩子各个都很争气(生的孙子多)
-
最好每个孩子还都很像(清一色的一米八)
大家就会觉得这一家子太厉害了!
我们对整个树结构进行打分,自然就能找到那个最牛的节点,就是我们要的表格。找到最牛爸爸之后,儿子们虽然相似:个子高,长得帅,两条胳膊两条腿,但这些都是共性,没有信息量,我们关心的是特性。大儿子锥子脸,跟其他人都不一样,那脸蛋就是重要信息;三儿子最有钱——钱也是我们关心的。 因此,对比儿子们的不同属性,我们就能知道哪些信息是重要的了。
回到网页采集这个例子,通过一套有趣的算法,给一个网页的地址,软件就会自动地把它转成Excel! (听不懂吧?听不懂正常, 不要在意这些细节!)
◆ ◆ ◆
破解翻页限制
获取了一页的数据,这还不够,我们要获取所有页面的数据!这简单,我们让程序依次地请求第1页,第2页...数据就收集回来了
就这么简单吗?网站怎么可能让自己宝贵的数据被这么轻松地抓走呢?所以它只能翻到第50页或第100页。链家就是这样:
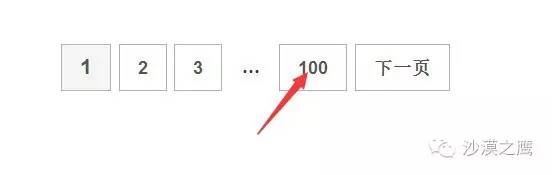
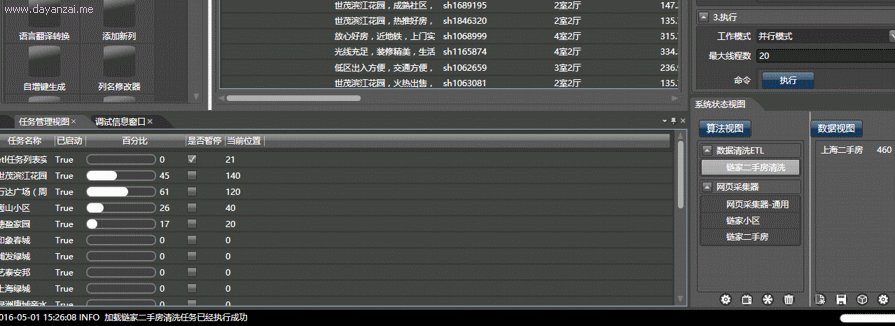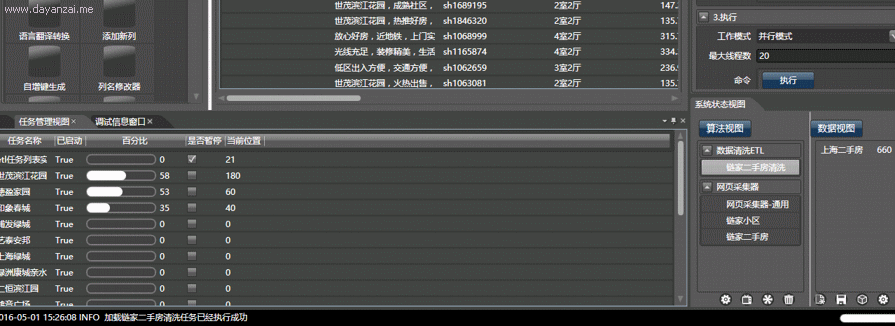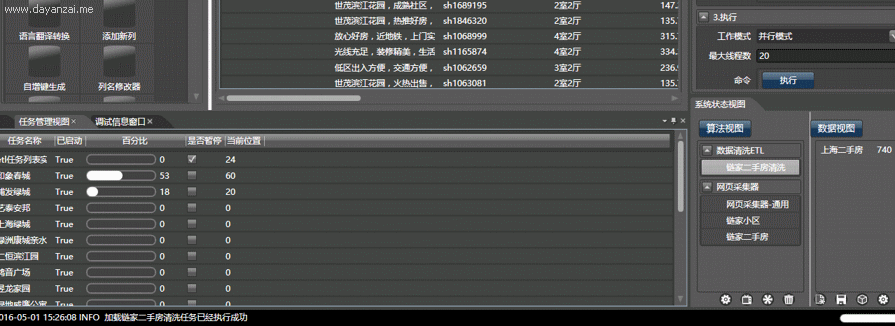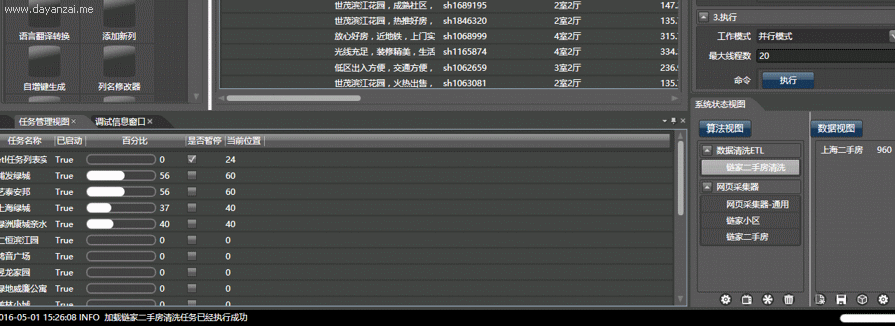
这也难不倒我们,每页有30个数据,100页最多能呈现3000条数据。北京有16个区县两万个小区,但每个区的小区数量就没有3000个了,我们可分别获取每个区的小区列表。每个小区最多有300多套在售二手房,这样就能获取链家的所有二手房了。
然后我们启动抓取器,Hawk就会给每个子线程(可以理解为机器人)分配任务:给我抓取这个小区的所有二手房! 然后你就会看到壮观的场面:一堆小机器人,同心协力地从网站上搬数据,超牛迅雷有没有?同时100个任务!!上个厕所回来就抓完了!!!
◆ ◆ ◆
清洗:识别并转换内容
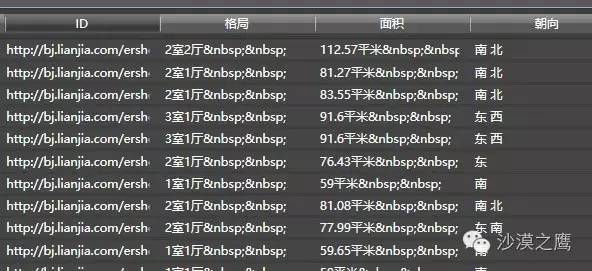
但你会看到,里面会有些奇怪的字符应该去去掉。xx平米应该都把数字提取出来。而售价,有的是2130000元,有的是373万元,这些都很难处理。
BUT,没关系!Hawk能够自动识别所有的数据:
-
发现面积那一列的乱码,自动去掉
-
识别价格,并把所有的价格都转换为万元单位
-
发现美元,转换为人民币
-
发现日期,比如2014.12或2014年12.31,都能转换为2014年12月31日
哈哈,然后你就能够轻松地把这些数据拿去作分析了,纯净无污染!
◆ ◆ ◆
破解需要登录的网站
此处的意思当然不是去破解用户名密码,还没强到那个程度。 有些网站的数据,都需要登录才能访问。这也难不倒我们。
当你开启了Hawk内置了嗅探功能时,Hawk就像一个录音机一样,会记录你对目标网站的访问操作。之后它就会将其重放出来,从而实现自动登录。
你会不会担心Hawk保存你的用户名密码?不保存怎么自动登录呢?但是Hawk是开源的,所有代码都经过了审查,是安全的。你的私密信息,只会躺在你自己的硬盘里。
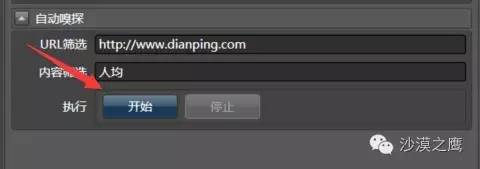
(我们就这样自动登录了大众点评)
◆ ◆ ◆
是不是我也可以抓数据了
理论上是的。但道高一尺魔高一丈,不同的网站千差万别,对抗爬虫的技术也有很多种。而且小虫虫对细节非常敏感,只要错一点,后面的步骤就可能进行不下去了。
怎么办呢?沙漠君把之前的操作保存并分享出来,你只要加载这些文件就能快速获取数据了。
如果你有其他网站的获取需求,可以去找你身边的程序员同学,让他们来帮忙抓数据,或让他们来试试Hawk,看看谁的效率更高。
如果你是文科生妹子,那还是建议你多看看东野奎吾和村上春树,直接上手这么复杂的软件会让你抓狂的。那该找谁帮忙抓数据呢?嘿嘿嘿...
◆ ◆ ◆
在哪里获取软件和教程?
Hawk: Advanced Crawler& ETL tool written in C#/WPF软件介绍
HAWK是一种数据采集和清洗工具,依据GPL协议开源,能够灵活,有效地采集来自网页,数据库,文件, 并通过可视化地拖拽,快速地进行生成,过滤,转换等操作。其功能最适合的领域,是爬虫和数据清洗。
Hawk的含义为“鹰”,能够高效,准确地捕杀猎物。
HAWK使用C# 编写,其前端界面使用WPF开发,支持插件扩展。通过图形化操作,能够快速建立解决方案。
GitHub地址:https://github.com/ferventdesert/Hawk
其Python等价的实现是etlpy:
http://www.cnblogs.com/buptzym/p/5320552.html
笔者专门为其开发的工程文件已公开在GitHub:
https://github.com/ferventdesert/Hawk-Projects
使用时,点击文件,加载工程即可加载。
不想编译的话,可执行文件在:
http://pan.baidu.com/s/1c8zBiQ 密码:4iy0
编译路径在:
Hawk.Core\Hawk.Core.sln
感谢作者授权转载,稿件部分有变动,作者在大数据文摘的其他投稿点击文末推荐文章查看。
◆ ◆ ◆
往期精彩文章推荐,点击图片可阅读
手把手教你用数据分析帮女神学姐选婚房
租房数据分析,2016年如何在北京租到好房子





文章评论