编者按:本文由 Teamwork 高级工程师 Peter Kelly 授权「高可用架构」发布中文版。转载请注明来自高可用架构公众号「ArchNotes」。

我们爱 Go。
在过去的一年中,我们为了构建 Teamwork Desk 多个服务,写下了将近 20 万行 Go 代码。我们已经构建了该产品的十多个小型 HTTP 服务。
为什么要使用 Go?
Go 是一种快速(非常快)的静态类型编译语言,它有强大的并发模型、垃圾收集、优异的标准库、无继承、传奇的作者、多核支持以及非常不错的社区。更别说对于我们这种写 Web 应用的程序员,它的 goroutine-per-request 设置可以避免事件循环和回调地狱。
在构建系统和服务器方面尤其是微服务,Go 语言已经成为了大热门。
正如使用任何新语言和技术一样,我们在早期的实践中经历了一段跌跌撞撞的过程。Go 语言确实有自己的风格和语言特性,尤其当你原来使用的语言是 OO 语言(比如 Java)或脚本语言(比如 Python)时需要适应的过程。所以我们也犯了一些错误,我们愿意和大家分享这些错误以及我们从中得到的教训。
如果你在生产环境中使用 Go,你可能对所有问题似曾相识。如果你刚开始使用 Go,希望你能从下面的总结中找到一些借鉴。
1. 不用 Revel

刚开始使用 Go?构建 Web 服务器?需要一个框架吧?你可能会这么认为。使用 MVC 框架确实有一些优势,这些优势主要来自于“约定优于配置”,它给予项目的结构,这种方式可以提供一致性并且降低跨项目开发的门槛。
我们的观点是相比于约定的优势,我们更倾向于配置的力量,特别是用 Go 语言写 Web 应用毫不费力,我们的很多 Web 应用都是小型服务。总的来说,这种方法不符合我们的语言习惯。
Revel 的基本观念在于努力向 Go 中引入类似于 Play 或 Rails 这样的框架,而不是使用 Go 和 stdlib 的力量并以此为基础向上构建。
Revel 作者是这样说:
一开始这只是一个好玩的项目,我想看看是否可以复制神奇的 Play! 1.x 到不那么神奇的 Go 语言中。
公正地说,在新语言中使用 MVC 框架对于当时的我们来说是很适合,因为这样做可以去除关于结构的争论,让新的团队可以以一种连贯的方式开始构建。在使用 Go 语言之前,几乎所有我写的 Web 应用都多少借助了一些 MVC 框架的方式。C#、ASP.NET MVC、Java SpringMVC。PHP Symfony、Python CherryPy、Ruby RoR……最后我们意识到我们不需要在 Go 中使用框架。标准库 HTTP 程序包已经拥有你需要的东西了,你通常只需要添加一个 multiplexer 多路复用器(比如 mux)用于路由选择,以及一个中间件(比如 negroni)的 lib 用于处理认证和登录等,这就是你需要的全部了。
Go 的 HTTP 程序包设计让一切都很简单。你还会意识到 Go 的一些能力就存在于 Go 的工具链和 Go 周围的工具中,这些工具会提供给你广泛而强大命令。
但是在 Revel 中,因为项目结构的设置,并且因为其中不支持 package main 和 func main() {} 入口,对于很多 Go 命令来说这是符合习惯且必要的,但 Revel 不能使用这些工具。事实上 Revel 带有自己的命令包,它会镜像一些像 run 和 build 这样的命令。
总结以下,使用 Revel:
-
不能运行 go build 及 go install
-
不能运行 race 探测器 (--race)
-
不能使用 go-fuzz 或其他任何需要可构建 Go 源的工具
-
不能使用其他中间件或路由器
-
热重载虽然简洁,但很慢,Revel 在源代码上使用反射,并且根据我们使用 1.4 版的经验,增加了约 30% 的编译时间。而且它还不使用 go install 因此包不会被缓存
-
不能迁移到 Go 1.5 或更高版本,因为在 Revel 中的编译时间还要更慢。我们去掉了 Revel 并且把内核迁移到了 1.6 上。
-
Revel 把测试挪到了 /test 目录下面,违反了 Go 把 _test.go 文件和被测试的文件一起放进相同程序包的惯例。
-
Revel 测试如果要运行,就会启动你的服务器,从而进行集成测试。
我们发现 Revel 严重偏离了符合 Go 语言使用习惯的构建方式,而且我们失去了 Go 工具箱中的一些强大的部分。
2. 善用 Panic
如果你原来是一位 Java 或 C# 开发者,你可能需要适应一下在 Go 中处理错误的方式。Go 可以从函数返回多个值,所以调用结果和 error 一起返回是一种非常普通的情况。当然如果没有异常的话 error 就会是 nil (nil 是 Go 中引用类型的默认值)。
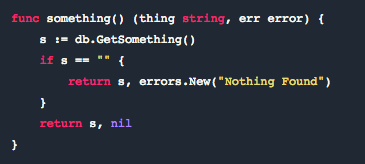
我们最终也开始使用 panic,其实我真正想要的是想创建一个错误,并让其被调用栈的上一级处理。
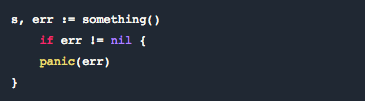
在 Go 中,通常 error 也是个返回值,而且是调用函数返回的正常的一部分。但 panic 就像一个 runtime 异常会搞挂你的应用。如果只是一个函数返回了一个 error,你为什么要使用 panic?这是我们得到的心得体会。
在 1.6 之前,如果 panic dump 会把所有运行的 goroutines 全部 dump 出来,所以要定位出错的点非常困难。你最终不得不费力做很多本不需要做的事。
哪怕你真的有一个不可恢复的错误,或者你遇到了一个运行时 panic,你大多并不想要停你的整个 Web 服务器,你的服务器可能还在处理其他事情(比如正在进行的数据库事务)。
所以我们学会了如何处理这些事件,在 Revel 中添加过滤器,它可以恢复 panic 并且捕捉日志文件的 stack trace,并发送到 Sentry (https://getsentry.com/welcome/),于是我们就会马上在邮件和 Teamwork Chat 中获得提醒。 API 会向前端返回 500 Internal Server Error。
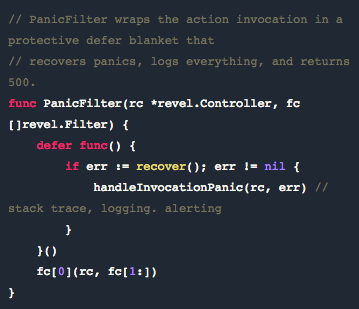
3. Request.Body 那些坑
在读取了 http.Request.Body 之后,Body 就被读空了,而随后的读取就会返回 []byte{} —— 一个空的 body。 这是因为当你在读取 http.Request.Body 的字节时,读取器处于这些字节的结尾,需要重置才能再次读取。但是 http.Request.Body 是一个 io.ReadWriter,并没有 Peek 或 Seek 这样的方法。
一个解决方法是先把 body 复制进存储空间,然后在读取之后把原来的设置回去。如果你的请求都很大,这么做的成本很高。
下面是一个简短但是完整的展示程序
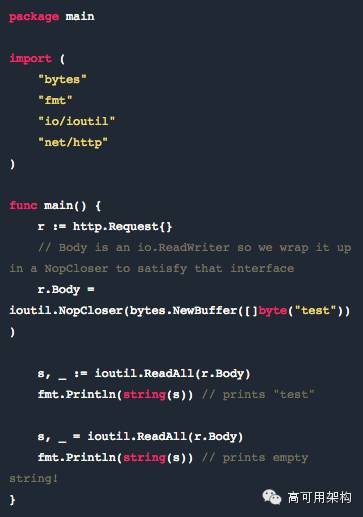
下面是复制并执行回种的代码
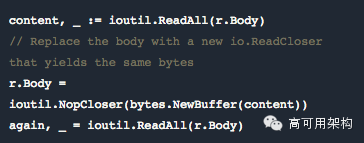
你可以创建一个小 util 函数
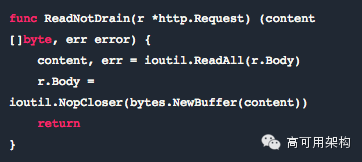
然后调用它而不是使用像 ioutil.ReadAll 这样的命令。

当然现在你已经用一个空操作替换了 r.Body.Close(),当你在 request.Body 上调用 Close 时,这个空操作什么也不会做。这就是 thehttputil.DumpRequest 的工作方式。
4. SQL 框架
Teamwork Desk 向用户提供 Web 应用时,需要完成的核心工作涉及很多 MySQL。我们不使用存储过程,所以我们在 Go 中的数据层包含有一些很复杂的 SQL......感觉有些代码都可以因为其复杂查询而赢得奥林匹克体操比赛的金牌。
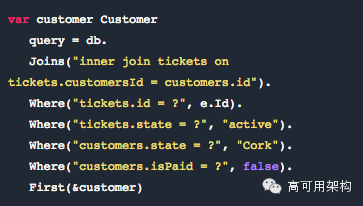
我们开始时使用 Gorm (http://jinzhu.me/gorm/)和 它的链式 API 来构建我们的 SQL。你在 Gorm 中还是可以使用原始 SQL,并且把结果打包进你的结构。(值得注意的是,我们发现我们执行这项操作的次数越来越多,这可能说明我们需要重新回到使用 Gorm 的真正方法,并且保证对其善加利用,否则我们就需要寻找其他替代品了——当然这种情况也没什么可怕的。)
对于一些人来说,ORM 是一个挺 low 的做法(它会让你失去控制力、理解力、以及优化查询的可能性)。但我们只是把 Gorm 作为构建查询的封装器,我们理解它给我们的输出,我们并没有把 Gorm 作为一个完整的 ORM 来使用。
Gorm 允许你利用它的链式 API 并且把结果打包到结构中。Gorm 的很多特性可以让你免受代码中的手工 SQL 折磨。它还支持 Preloading,Limits,Grouping,Associations,原始 SQL,Transactions 等。
总结下,如果你正在 Go 中手写 SQL 的话,Gorm 绝对值得关注。
5. 滥用指针
这里主要只是针对切片(slice)来说的,使用切片作为参数传个一个函数。在 Go 里,由于数组如果作为参数会传值,所以如果有一个很大的数组,你不想每次传递和赋值它的时候都要复制一下吧?没错,到处传递数组对于存储空间来说是一个昂贵的开销。
但是在 Go 中,99% 的时间你都在和 slice 打交道,而不是数组。Slice 可以被看做用来描述数组某些部分(经常是全部)的东西,它含有一个指向数组开始元素的指针、slice 的长度,以及 slice 的容量。
Slice 的每部分只需要 8 个字节,所以它永远都不会超过 24 个字节,无论其下的数组有多少内容,有多大。

我们经常把 slice 指针传给一个函数,并且误以为我们节省了存储空间。
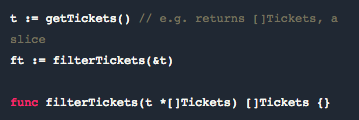
上例中,如果我们在 t 中有很多数据,我们以为通过把数据传给 filterTickets, 就避免了存储空间中的大型数据拷贝。
鉴于我们现在对 slice 的理解,我们可以愉快地把这个 slice 按照值来传递,而不用考虑存储空间问题。
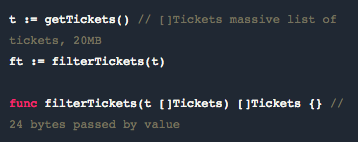
当然,不按引用传递也意味着避免了错误地改变指针指向的问题,因为 slice 自身就是引用类型。
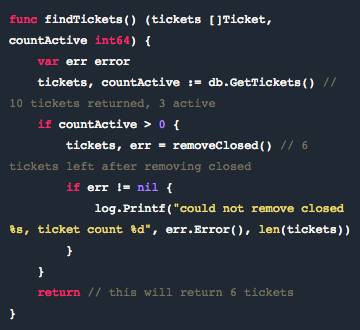
6. 非命名返回的可读性
非命名返回(Naked returns)这个名词描述的是在 Go 语言中,你从一个函数返回时不明确说明你返回的是什么。
在 Go 中,你 可以有命名返回值,比如 func add(a, b int) (total int) {}。我可以只用 return 而不写 return total。在小函数中使用非命名返回是简洁而有效的。
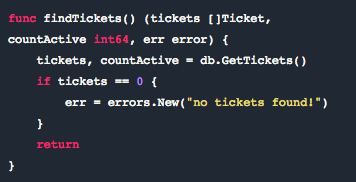
这里运行的结果情况显而易见。如果没有 tickets,那么就会返回 0, 0, error。如果找到了tickets, 那么类似 120, 80, nil 这样的东西就会被返回,这取决于 ticket count 等因素。
这里的关键在于如果你在函数签名中有命名返回值,那么你可以使用 return(非命名返回),当调用 return 时,它会在每个命名返回值的所处状态中为命名返回值返回数值。
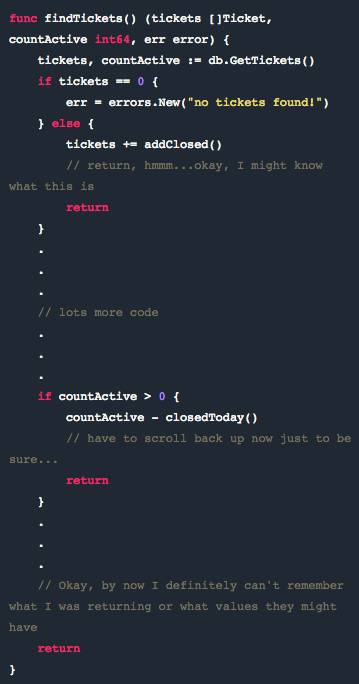
但是我们曾有一些比较大的函数。函数中任何长到你需要滚动浏览的非命名返回都是潜在的漏洞,对于可读性来说也是灾难。
特别是当你还有多个返回点时,千万不要这么做。两种做法都不可取——无论是非命名返回还是大函数。
以下是一个假设的例子:
7. 作用域和局部变量
一个程序可能会有多个相同的变量名,只要它们的声明在不同的词法块就好。例如,你可以在函数内声明一个局部变量 x,同时再声明一个包级的变量 x,这是在函数内部,局部变量 x 就会替代后者,这里称之为 shadow,意味着在函数作用域内局部变量将包变量隐藏了。
当你利用作用域 := 用相同的名字在不同块中声明变量时(被称为 shad
ow),你可能会因为 Go 中作用域的问题引入不为人知的 bug。
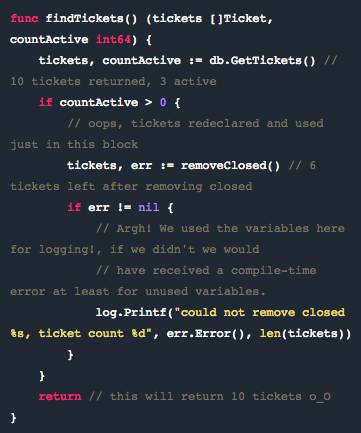
这里注意的的问题存在于 := 局部变量声明和赋值之间。通常来说当你在左边声明新变量时 := 只会编译。但是如果左边有任何变量是新的话,它也会这样运行。在上面的例子中 err 是新的,所以你期待 tickets 被覆写,就像是已经在上面的函数返回参数中声明了一样。但是实际情况并非如此。
原因在于块作用域——一个新的被声明的 ticket 变量被分配出去,并且一旦块完成之后就会丢失自己的作用域。要改变这一点,只要在块外声明变量 err,并且使用 = 而非 := 。一个好的编辑器,比如 Emacs 或 Sublime 会解决这个 shadow 问题。
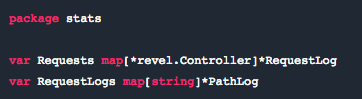
8. Map 并发访问的崩溃问题
并发方式访问 Map 并不安全。我们曾经发生过一个场景,我们设置了一个应用生命周期都能访问的包级别变量的 map。这个 map 用于回收应用中每个控制器的数据。当然在 Go 中,每个 HTTP 请求都有它自身的 goroutine。
你能看出来将会发生什么——最终不同的 goroutine 会试图同时访问 map,无论是读还是写。这会造成 panic,而我们的进程将会崩溃。(当进程停止时,我们用 Ubuntu 上的 upstart 脚本来重启应用,至少保持让应用“不死”。)
寻找这类 panic 原因的过程很笨重,有点像 1.6 版以前的情况,当堆栈 dump 会把所有运行的 goroutine 都包括进来时,就会产生大量需要筛查的日志。
Go 团队确实考虑过使 map 在并发访问时更安全,但是最终决定放弃,因为这会为一般场景造成不必要的开支——这是一种让事情保持简单的实用的做法。
在 golang.org FAQ 中提到如此选择的原因
“经过漫长的讨论之后,我们决定,map 的一般用法并不需要来自多个 goroutine 的安全访问,在需要的场景中,map 可能处于某些已经被同步保护的大型数据结构或计算中。所以,要求所有 map 操作获取互斥锁会减慢大多数程序,但是却只为很少的程序提供了安全性。
由于不受控制的 map 访问会使进程崩溃,所以这并不是一个轻松的决定。”
我们的代码看起来有点像这个:
我们把它变成使用 stdlib 中的 sync 包来嵌入结构中的读取器/写入器互斥锁,该结构还会封装我们的 map 。我们向结构中添加了一些 helper 方法:Add 和 Get 。
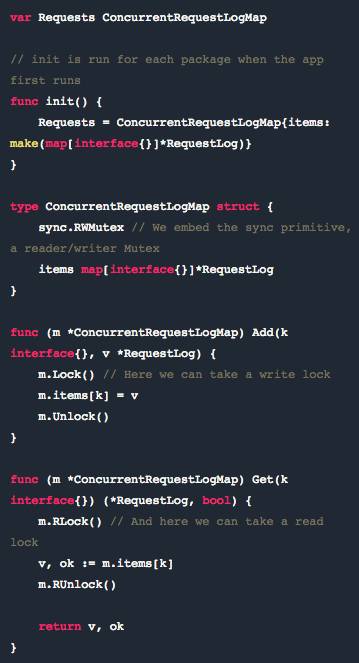
从此终于远离崩溃了。
9. 理解 Vendor——宙斯的胡子
好吧,承认这件事有点不好意思,我们把代码发布到生产环境过程中竟然没用 vendor。
Vendor 是 Go 语言的包及依赖管理工具,如果你不知背景的话,接下来我说明下这件事为什么很糟糕。你通过从你项目的根目录中运行 go get ./... 获得依赖。这会将每一个依赖都需要从 master 上的 HEAD 拉取。
很明显这种情况非常糟糕,除非你在服务器的 $GOPATH 上保存了所需版本的依赖,而且从来不更新(包括从来没有重建或启动新服务器),否则破坏性的改变不可避免,而你也对生产环境中运行的代码失去控制。
在 Go 1.4 中我们 vendor 使用了 Godeps 及其 GOPATH 方法。
在 1.5 中我们使用了 GO15VENDOREXPERIMENT 环境变量。
在 1.6 中,谢天谢地,项目根目录中的 /vendor 终于可以被识别为可以存放你依赖的地方,不再需要额外工具了。你可以使用各种 vendoring 工具中的一种来追踪版本并且更轻松地添加及更新依赖(移除 .git、更新 manifest 等)。
学无止境
上文是我们早期犯下的一部分错误以及从中得到教训的小清单。
我们是一个由 5 个开发者组成的构建 Teamwork Desk 的小团队,但是我们在去年一年的时间里学到了关于 Go 的大量知识,同时我们还以飞快速度交付了大量的优秀功能。今年你会看到我们出席各种 Go 技术大会,包括在丹佛举行的 GopherCon。我很快也将在科克本地的开发者聚会上分享关于 Go 的实践。
我们将会继续关注 Go 开源工具发布,并且回馈已有的库。到目前为止,我们向一些小项目贡献了不算少的代码,我们提出的性能要求也被 Stripe、Revel 以及其他开源 Go 项目所采纳。
-
s3pp https://github.com/Teamwork/s3pp
-
stripehooks https://github.com/Teamwork/stripehooks
-
tnef parser https://github.com/Teamwork/tnef

我们永远都在寻找优秀的开发者,到 Teamwork.com 上来,加入我们吧!
本文作者:Peter Kelly,Teamwork Desk 高级工程师。
英文原文:http://engineroom.teamwork.com/go-learn/
相关文章
本文翻译李盼,想讨论更多 Go 语言开发,请关注公众号获取更多文章。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。
高可用架构
改变互联网的构建方式

长按二维码 订阅「高可用架构」公众号


文章评论