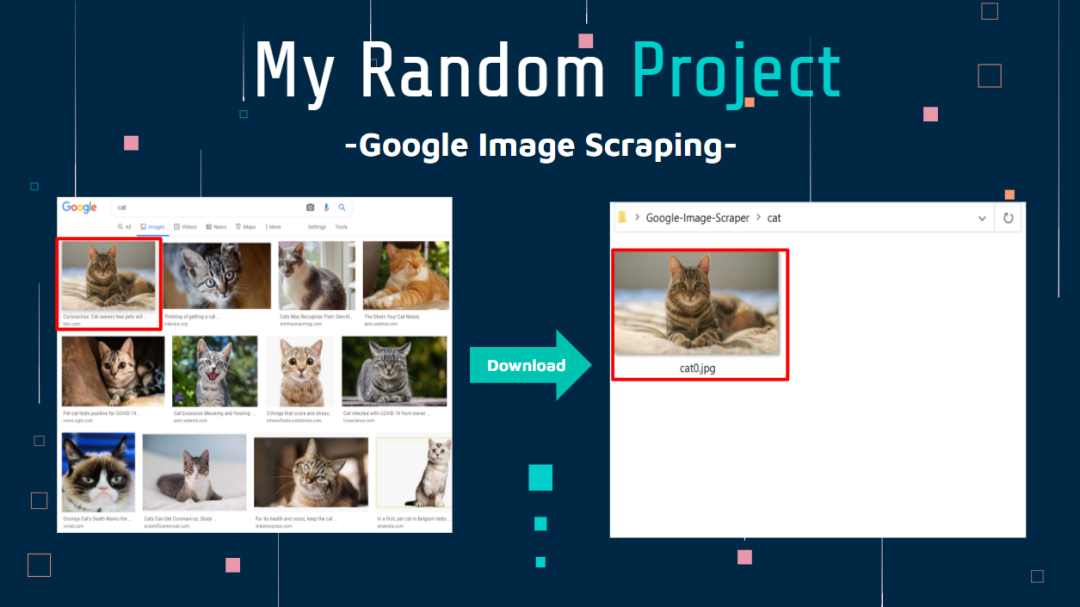
Google Image Scraper
Google图片爬虫库
描述:一个用来抓取Google图片的库
算法链接
https://github.com/ohyicong/Google-Image-Scraper#setup先决条件:
-
Pip 安装 Selenium 库
-
Pip安装 PIL
-
下载谷歌浏览器
-
根据您的 Chrome 版本下载 Google Webdriver
设置:
-
打开命令终端
-
克隆或者下载存储库
git clone https://github.com/ohyicong/Google-Image-Scraper-
安装依赖项
pip install selenium, requests, pillow-
运行代码
python main.py用法:
#Import libraries (Don't change)from GoogleImageScrapper import GoogleImageScraperimport osfrom patch import webdriver_executable#Define file path (Don't change)webdriver_path = os.path.normpath(os.path.join(os.getcwd(), 'webdriver', webdriver_executable()))image_path = os.path.normpath(os.path.join(os.getcwd(), 'photos'))#Add new search key into array ["cat","t-shirt","apple","orange","pear","fish"]search_keys= ["cat","t-shirt"]#Parametersnumber_of_images = 10headless = Truemin_resolution=(0,0)max_resolution=(1920,1080)#Main programfor search_key in search_keys:image_scrapper = GoogleImageScraper(webdriver_path,image_path,search_key,number_of_images,headless,min_resolution,max_resolution)image_urls = image_scrapper.find_image_urls()image_scrapper.save_images(image_urls)
Youtube 视频:

文章评论