我是一只可爱的土拨鼠,专注于分享 Go 职场、招聘和求职,解 Gopher 之忧!欢迎关注我。 欢迎大家加入Go招聘交流群,来这里找志同道合的小伙伴!跟土拨鼠们一起交流学习。
相信模糊测试大家已经很熟悉了,还没开始使用的同学可以看看官方的教程 https://go.dev/doc/tutorial/fuzz 和煎架写的这篇我要提高 Go 程序健壮性,Fuzzing 来了!。今天小土给大家带来一篇关于模糊测试原理的文章。
本文由小土翻译自 Internals of Go's new fuzzing system[1],翻译不当之处,烦请指出。
Go 1.18很快就要发布了,希望在几周后。这是一个巨大的版本,有很多值得期待的东西,但原生模糊测试在我心中有一个特殊的位置。(当然我是超级偏心的:在我离开谷歌之前,我和Katie Hockman和Roland Shoemaker一起工作,建立了fuzzing系统)。我想,泛型也很酷,但将模糊测试集成到testing包和go test中,将使模糊测试更容易被大家接受,这使得在Go中编写安全、正确的代码更加容易。
关于Go的模糊测试系统究竟是如何工作的,目前还没有太多的文章,所以我将在这里谈一谈这个问题。如果你想尝试一下,Getting started with fuzzing[2]是一个不错的教程。
什么是模糊测试?
Fuzzing是一种测试技术,测试基础设施用随机生成的输入调用你的代码,以检查它是否产生正确的结果或合理的错误。模糊测试是对单元测试的补充,在单元测试中,你要测试你的代码在一组静态输入的情况下是否产生了正确的输出。单元测试的局限性在于,你只能用预期的输入进行测试;模糊测试在发现暴露出奇怪行为的意外输入方面非常出色。一个好的模糊测试系统也会对被测试的代码进行分析,因此它可以有效地产生输入,从而扩大代码覆盖面。
模糊测试通常用于检查解析器(parsers)和验证器(validators),特别是用于安全上下文中的任何东西。模糊测试非常善于发现导致安全问题的错误,如二进制编码中的无效长度、被截断的输入、整数溢出、无效的unicode等等。
也有其他方法可以使用模糊测试。例如,差分模糊法通过向两个实现提供相同的随机输入并检查输出是否匹配,来验证同一事物的两个实现是否具有相同的行为。你也可以将模糊测试用于UI的 monkey测试:模糊引擎可以产生随机的敲击、击键和点击,而测试则验证应用程序是否不会crash。
Go中的模糊测试发生了什么
模糊测试对Go来说并不陌生。go-fuzz[3]可能是目前使用最广泛的工具,我们在开发原生模糊测试时当然也借鉴了其设计。Go 1.18中的新东西是,模糊处理被直接整合到go test和testing包中。其interface与测试testing.T的interface非常相似。
例如,如果你有一个名为ParseSomething的函数,你可以写一个像下面这样的模糊测试。这将会对于任何随机输入进行检查,ParseSomething要么成功,要么返回一个 ParseError。
package parser
import (
"errors"
"testing"
)
var seeds = [][]byte{
nil,
[]byte("123"),
[]byte("(12)"),
}
func FuzzParseSomething(f *testing.F) {
for _, seed := range seeds {
f.Add(seed)
}
f.Fuzz(func(t *testing.T, input []byte) {
err := ParseSomething(input)
if err == nil {
return
}
if parseErr := (*ParseError)(nil); !errors.As(err, &parseErr) {
t.Fatal(err)
}
})
}
当go test正常运行时(没有-fuzz参数),FuzzParseSomething会被当作一个单元测试。提供给`F.Fuzz`[4]的模糊函数被调用,其输入来自种子语料库:用F.Add注册的输入和从testdata/corpus/FuzzParseSomething的文件中读取的输入。如果模糊函数panic或调用T.Fail,测试就会失败,并且go test以非零状态退出。
可以通过运行带有-fuzz参数的go test来启用模糊测试,比如这样。
go test -fuzz=FuzzParseSomething
在这种模式下,模糊测试系统将以随机生成的输入调用模糊函数,使用种子语料库和缓存语料库的输入作为起点。扩大覆盖范围的输入被最小化并添加到缓存语料库中。产生的导致错误的输入被最小化并添加到种子语料库中,有效地成为新的回归测试用例。以后的go test运行将失败,直到问题被修复,即使没有启用模糊测试。
同样,与其他系统相比,这里也没有什么真正的创新。它的优势在于interface的熟悉度和使用的方便性。编写你的第一个模糊测试很容易,因为模糊测试遵循测试包的惯例。无需让团队中的每个人都去安装和学习一个新工具。
模糊测试系统是如何工作的?
你可能已经知道,go test为每个被测试的软件包构建一个测试可执行文件,然后运行这些可执行文件可以获得测试和基准结果。模糊测试也遵循这一模式,尽管有一些不同之处。
当go test以-fuzz参数调用时,go test在编译测试可执行文件时增加了覆盖率工具。Go编译器已经有对libFuzzer[5]的检测支持,所以我们复用了它。编译器为每个基本块[6]添加了一个8位计数器。这个计数器是快速和近似的:它在溢出时被包裹,而且没有跨线程的同步。(我们不得不告诉race检测器不要抱怨对这些计数器的写入)。计数器数据在运行时被internal/fuzz[7]包使用,大部分模糊逻辑都在这里。
在go test构建了一个工具化的可执行文件后,它像往常一样运行它。这就是所谓的coordinator过程。这个进程是以大多数传递给go test的参数启动的,包括-fuzz=pattern,它用来识别要模糊测试的目标;目前,每个go test调用只能模糊测试一个目标( #46312[8])。当该目标调用F.Fuzz时,控制权被传递给fuzz.CoordinateFuzzing,它初始化了模糊测试系统并开始coordinator事件循环。
coordinator启动几个woker进程,它们运行相同的测试可执行文件并执行实际的模糊处理。woker是用一个没有记录的命令行标志启动的,并告诉它们是worker。模糊测试必须在不同的进程中进行,这样,如果一个worker进程完全crash,coordinator仍然可以找到并记录导致crash的输入。
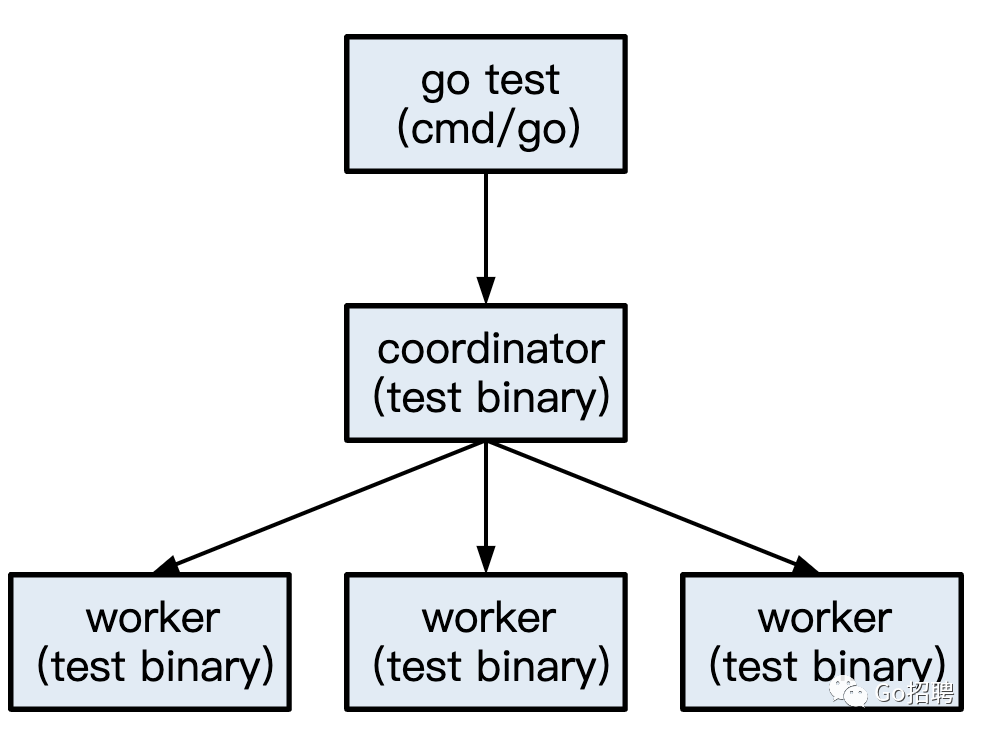
coordinator通过一对管道使用临时的基于JSON的RPC协议与每个worker进行通信。该协议是非常基础的,因为我们不需要像gRPC那样复杂的东西,而且我们也不想在标准库中引入任何新东西。每个worker还在一个内存映射的临时文件中保留一些状态,与coordinator共享。大多数情况下,这只是一个迭代计数和随机数生成器的状态。如果worker完全crash,coordinator可以从共享内存中恢复其状态,而无需worker先礼貌地通过管道发送消息。
在coordinator启动worker之后,它通过向worker发送来自种子语料库和模糊缓存语料库(在 $GOCACHE的一个子目录中)的输入来收集基线覆盖率。每个worker运行其给定的输入,然后报告其覆盖率计数器的快照。coordinator对这些计数器进行粗化,并将其合并为一个综合覆盖率数组中。
接下来,coordinator从种子语料库和缓存语料库中发送输入,进行模糊处理:每个worker都得到一个输入和一个基线覆盖率数组的副本。然后,每个worker随机地改变其输入(flipping bits, deleting or inserting bytes,等),并调用模糊函数。为了减少通信开销,每个worker可以在100毫秒内不断变化和调用,而无需coordinator的进一步输入。每次调用后,worker检查是否报告了错误(用T.Fail)或与基线覆盖率数组相比是否发现了新的覆盖率。如果是这样,worker会立即将 "有趣的 "输入报告给coordinator。
当coordinator收到一个产生新覆盖率的输入时,它将worker的覆盖率与当前的组合覆盖率数组进行比较:有可能另一个worker已经发现了一个提供相同覆盖率的输入。如果是这样,新的输入将被丢弃。如果新的输入确实提供了新的覆盖率,coordinator会将其给一个worker(可能是另一个worker)发送回去进行最小化。最小化就像模糊处理一样,但worker会进行随机变化,以创建一个较小的输入,至少能提供一些新的覆盖范围。较小的输入往往更快,所以值得花时间在前面进行最小化,以使以后的模糊处理过程更快。worker进程在完成最小化后会报告回来,即使它未能找到任何更小的东西。coordinator将最小化的输入添加到缓存的语料库中并继续。稍后,coordinator可能会将最小化的输入发送给worker,以便进一步进行模糊测试。这就是模糊处理系统如何适应寻找新的覆盖范围。
当coordinator收到一个导致错误的输入时,它再次将输入送回给worker进行最小化。在这种情况下,worker尝试找到仍然会导致错误的较小输入,尽管不一定是相同的错误。在输入被最小化后,coordinator将其保存到testdata/corpus/$FuzzTarget中,优雅地关闭worker进程,然后以非零状态退出。
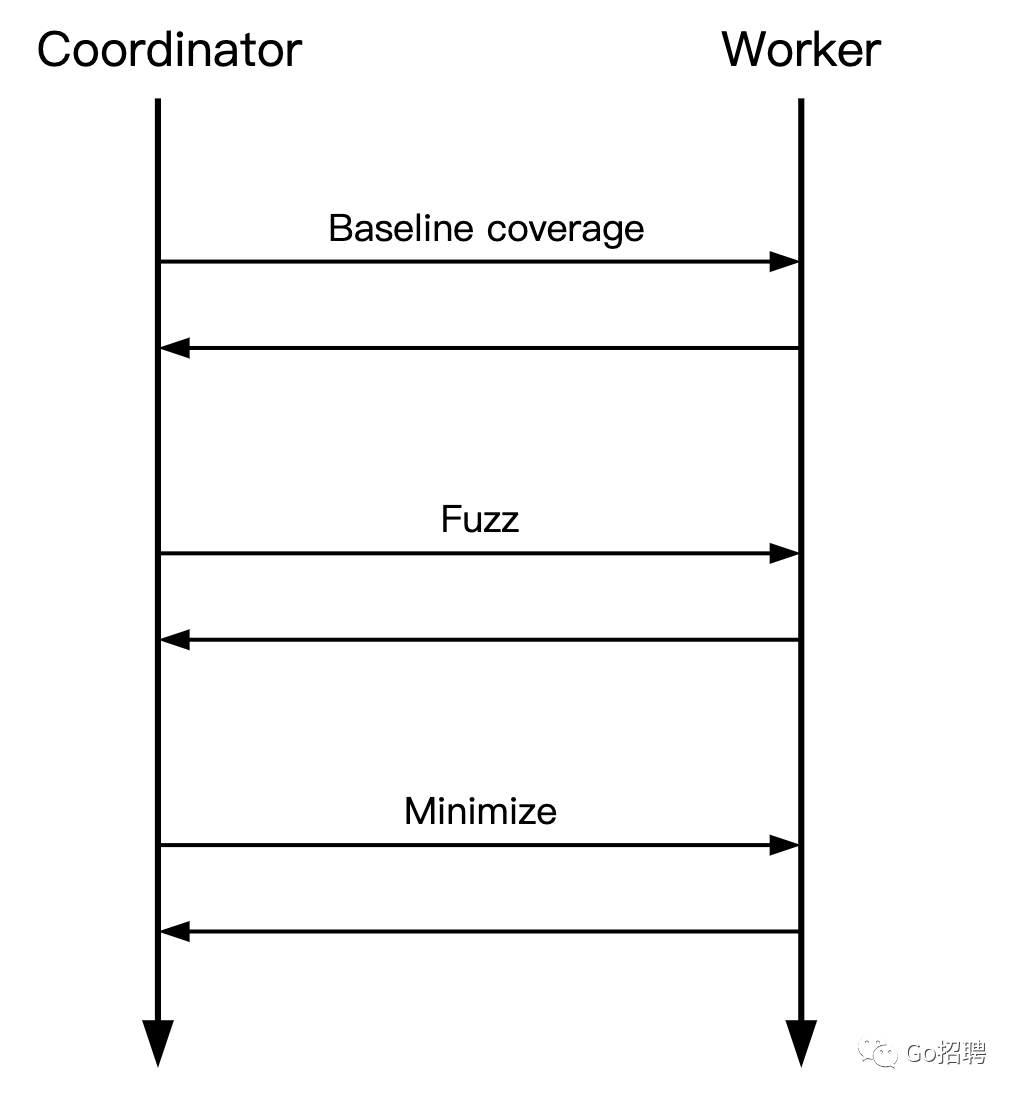
如果worker进程在模糊测试过程中crash,coordinator可以使用发送到worker的输入以及worker的RNG状态和迭代次数(都留在共享内存中)恢复导致crash的输入。crash的输入通常不会被最小化,因为最小化是一个高度有状态的过程,而每次crash都会破坏这个状态。这在理论上[9]是可能的,但目前还没有人做到。
模糊处理通常会持续到发现错误,或者用户按Ctrl-C中断进程,或者通过-fuzztime设置的最后期限。无论中断是传递给coordinator还是worker进程,模糊处理引擎都会优雅地处理它们。例如,如果一个worker在最小化一个导致错误的输入时被打断,coordinator将保存未最小化的输入。
fuzzing的未来
我对这个版本感到非常兴奋,尽管我不得不承认,Go的新模糊引擎离达到与其他模糊系统同等的功能和性能还有一段距离。许多改进是可能的,但它已经处于一个可用的状态,而且API很稳定。
你可以在issue追踪器上找到带有fuzz标签的 open issues[10]列表。那些具有 Go1.19[11]里程碑的问题被认为是最高优先级的,尽管问题可能会根据用户反馈和开发人员带宽重新排序。
总之,去试试吧!如果你在自己的代码中发现任何好的bug(或别人的),请将它们添加到Go wiki上的 Fuzzing trophy case[12]。
参考资料
Internals of Go's new fuzzing system: https://jayconrod.com/posts/123/internals-of-go-s-new-fuzzing-system
[2]Getting started with fuzzing: https://go.dev/doc/tutorial/fuzz
[3]go-fuzz: https://github.com/dvyukov/go-fuzz
[4]F.Fuzz: https://pkg.go.dev/[email protected]#F.Fuzz
libFuzzer: https://llvm.org/docs/LibFuzzer.html
[6]基本块: https://zh.wikipedia.org/wiki/%E5%9F%BA%E6%9C%AC%E5%A1%8A
[7]internal/fuzz: https://pkg.go.dev/internal/fuzz
[8]#46312: https://github.com/golang/go/issues/46312
[9]理论上: https://github.com/golang/go/issues/48163
[10]open issues: https://github.com/golang/go/issues?q=is%3Aissue+is%3Aopen+label%3Afuzz
[11]Go1.19: https://github.com/golang/go/issues?q=is%3Aissue+is%3Aopen+label%3Afuzz+milestone%3AGo1.19
[12]Fuzzing trophy case: https://github.com/golang/go/wiki/Fuzzing-trophy-case
欢迎关注Go招聘公众号,获取Go专题、大厂内推、面经、简历、股文等相关资料可回复和点击导航查阅。

文章评论