
导语 | Golang核心开发人员、goroutine调度的设计者Dmitry Vyukov,在2019年的一个talk里深入浅出地阐述了goroutine调度的设计思想以及一些优化的细节。本文是笔者结合自身经验和认知的一点观后感,采用从零开始层层递进的方法,总结剖析了其背后的软件设计思想,希望对读者更好地理解goroutine调度GMP模型会有所帮助。
前言
视频地址:
https://2019.hydraconf.com/2019/talks/7336ginp0kke7n4yxxjvld/
这个视频我以前看过,近几天刷到便又看了一遍,真是有听君一席话受益匪浅之感。毫不夸张地说,本视频在笔者看过的所有资料中,对于GMP为什么要有Processor这点,讲得最为清楚。视频中对goroutine调度模型的讲解,真可谓深入浅出!下面笔者将自己的一些观感整理分享给大家,还没看过视频的同学,建议先看完本文再去看,收获会更大。
为了表达方便,本文会沿用golang里面的GMP缩写:
-
G —— goroutine
-
M —— 机器线程
-
P —— 对处理器的抽象
一、设计并发编程模型
goroutine调度的设计目标,其实就是设计一种高效的并发编程模型:
-
从开发的角度只需要一个关键词(go)就能创建一个执行会话,很方便使用,即开发效率是高效的。
-
从运行态的角度,上述创建的会话也能高效的被调度执行,即运行效率也是高效的。
我们可以近似将goroutine看待为协程(一些代码逻辑+一个栈上下文),如果读者用C/C++造过协程框架的轮子,会很容易理解这点。
注:除了高效之外,还有其他几个目标,如无大小限制的goroutine栈,公平的调度策略等。
二、从零开始:从多线程说起
想要实现并发的执行流,最直截了当的,自然就是多线程。由此便得出初始思路:每个goroutine对应一个线程。
从并发的功能角度来讲,该方案固然可以实现并发,但性能方面却很不堪,尤其是在并发很重的时候,成千上万个线程的资源占用、创建销毁、调度带来的开销会很巨大。
三、更进一步:线程池的方案
既然线程太多不好,那我们可以很轻易地做出一点改善,控制一下线程数量,如此便得到更进一步的方案:线程池,限定只启动N个线程。
由于该方案下,可能是M个goroutine,N个线程,因而显然需要考虑一个问题:对于一个goroutine,它到底该由哪个线程去执行?我们可以简单地采用一个全局的Global Run Queue,然后让所有线程主动去获取goroutine来执行,示意如下:
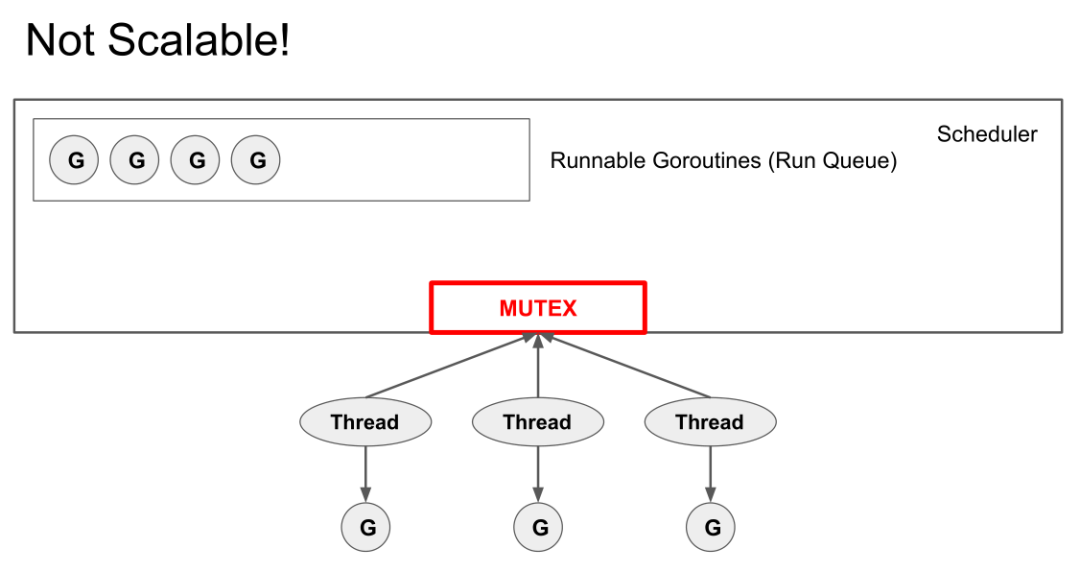
这样做在线程少的时候,如果调度行为不是很频繁,可能问题不大。但当线程较多时,就会有scalable的问题,mutex的互斥竞争会非常激烈(考虑到基于时间片的抢占行为,实际上调度必然是很频繁的)。
四、初具雏形:线程分治
在多线程编程领域中,互斥处理可以称得上是“名声在外”,需极其小心地去应对。最常见的解决方案,并不是如何精妙地去lock free,而是直接通过 “数据分治”和“逻辑分治”来避免做复杂的加锁互斥,将各个线程按横向(载荷分组)或纵向(逻辑划分)进行切分来处理工作。
通过数据分治的思想,我们就可以得到改进的方案:每个线程分别处理一批G,进行线程分治。将所有G分开放到各线程自己的存储中,即所谓的Local Run Queue中。示意如下:
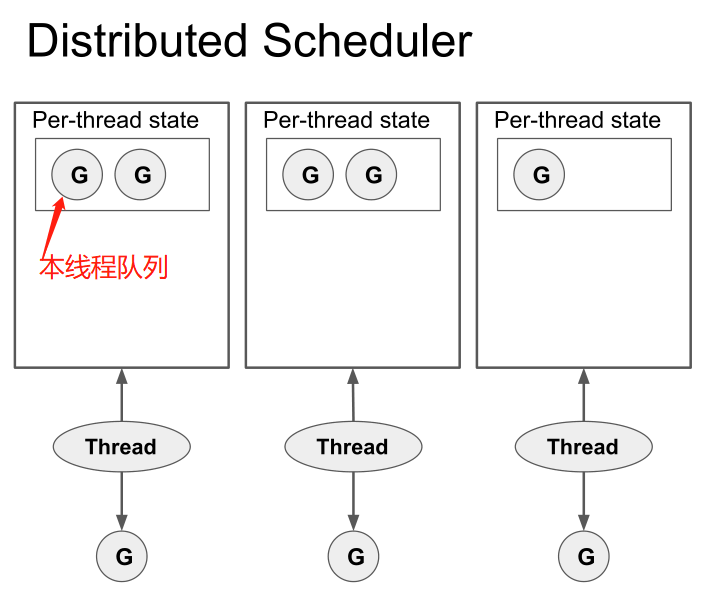
注:Global Run Queue也还继续存在的,有关它存在的细节非本文重点,这里不做展开。
至此,调度模型已具雏形。
让我们继续分析确认一下,该模型是否真的解决了scalable的问题。上述模型下,为了充分利用CPU,每个线程要按一定的策略去Steal其他线程Local Run Queue里面的G来执行,以免线程之间存在load balance问题(有些太闲,有些又太忙)
因此在线程很多的时候,存在大量的无意义加锁Steal操作,因为其他线程的Local Run Queue可能也常常都是空的。还有另一个问题,由于现在的一些内存资源是绑定在线程上面的,会导致线程数量和资源占用规模紧耦合。当线程数量多的时候,资源消耗也会比较大。
注:在N核的机器环境下,假如我们设定线程池大小为N,由于系统调用的存在(关于系统调用的处理见后文),实际的线程数量会超过N。
五、趋于完善:将资源和线程解耦
既然每个线程一份资源也不合适,那么我们可以仿照线程池的思路,单独做一个资源池,做计算存储分离:把Local Run Queue及相关存储资源都挪出去,并依然限定全局一共N份,即可实现资源规模与系统中的真实线程数量的解耦。线程每次从对应的数据结构(Processor)中获取goroutine去执行,Local Run Queue及其他一些相关存储资源都挂在Processor下。这样加一层Processor的抽象之后,便得到众所周知的GMP模型:
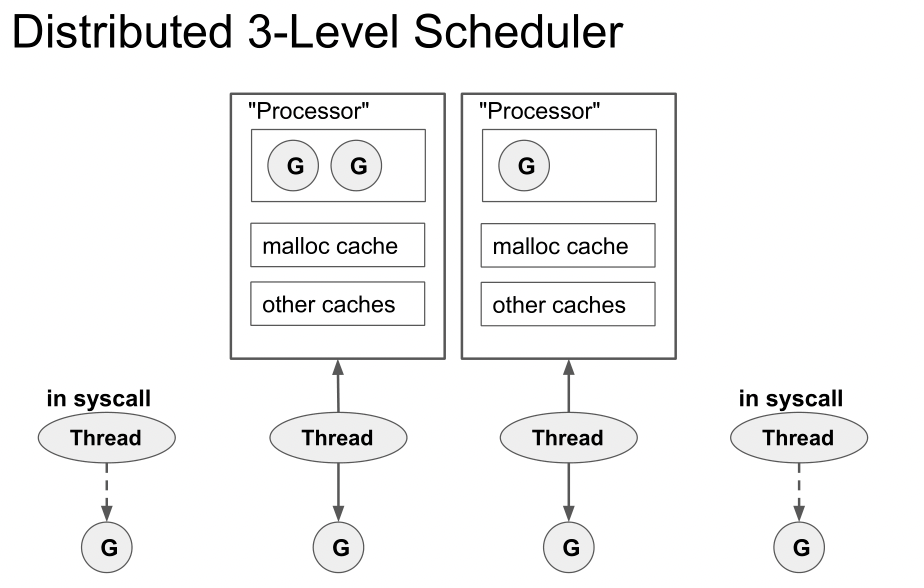
现在的调度模型已趋于完善,不过前面我们主要侧重讲的是如何高效,还未讨论到调度的另一个关键问题:公平性与抢占,接下来我们看看如何实现抢占。
六、还要公平:调度抢占
参考操作系统CPU的调度策略,通常各进程会分时间片,时间片用完了就轮到其他进程。在golang里也可以如此,不能让一些goroutine长期霸占着运行资源不退出,必须实现基于时间片的“抢占”。
那怎么抢占呢,需要监测goroutine执行时间片是否用完了。如果要检查系统中的各种状态变化、事件发生情况,通常会有中断与轮询两种思路,中断是由一个中控方来做检查与控制,而轮询则是各个参与方按一定的策略主动check询问。因此对于goroutine抢占而言,有以下两种解决方案:
-
Signals,通过信号来中断原来的线程执行。
-
Cooperative checks,通过线程间歇性轮询自己check运行的时间片情况来主动暂停。
二者的优劣对比如下:

因为golang其实是有runtime的,而且代码编译生成也都是golang编译器控制的,综合优劣分析,选择后者会比较合理。
对于Cooperative checks的方案,从代码编译生成的角度看,很容易做check指令的埋点。且因为golang本来就要做动态增长栈,在函数入口处会插入检查是否该扩栈的指令,正好利用这一点来做相关的检查实现(这里有一些优化细节,可以使得基于时间片的抢占开销也较小)
插入check指令的做法,会导致该方案存在一个理论缺陷:若有一个死循环,里面的所有代码都不包含check指令,那依然会无法抢占,不过现实中基本不存在这种情况,总会做函数调用、访问channel等类似操作,因此不足为虑。
除此以外还有一个系统调用的问题,当线程一旦进入系统调用后,也会脱离runtime的控制。试想万一系统调用阻塞了呢,基于Cooperative checks的方案,此时又无法进行抢占,是不是整个线程也就罢工了。所以为了维持整个调度体系的高效运转,必然要在进入系统调用之前要做点什么以防患未然。Dmitry这里采用的办法也很直接,对于即将进入系统调用的线程,不做抢占,而是由它主动让出执行权。线程A在系统调用之前handoff让出Processor的执行权,唤醒一个idle线程B来做交接。当线程A从系统调用返回时,不会继续执行,而是将G放到run queue,然后进入idle状态等待唤醒,这样一来便能确保活跃线程数依然与Processor数量相同。
七、设计思想的小结
这里recap一下,把前文涉及到的一些软件设计思想罗列如下:
-
线程池,通过多线程提供更大的并发处理能力,同时又避免线程过多带来的过大开销。
-
资源池,对有一定规模约束的资源进行池化管理,如内存池、机器池、协程池等,前面的线程池也可以算作此类。
-
计算存储分离,分别从逻辑、数据结构两个角度进行设计,规划二者的耦合关系。
加一层,这个是万能大法,不赘述。
-
中断与轮询,用于监测系统中的各种状态变化、事件变化,通常来讲中断会比轮询更高效。
八、视频的其他内容
本文的重点在GMP模型,因此视频里还有一些其他的内容,文中并未详细展开:
-
Local Run Queue里面的G所创建的G会放到同样的Local Run Queue(如果满了还是会放GRQ),而且会限制被偷走,这样可以加强Locality,同时为了保证公平也做了时间片继承,以免不停创建G会长期霸占运行资源。
-
被抢占的G会放到全局的G队列(Global Run Queue),GRQ会每61次tick检查一次,Dmitry针对这个61解释了一番,但笔者认为还是有点拍脑袋的感觉。
-
G的栈采用的是Growable stack方案,在函数入口会有栈检查的指令,如需扩容栈,会拷贝到新申请的更大的栈。
-
Go runtime还会用Background thread来运行一些相对特别的G(如 Network Poller、Timer)。
以上这些内容,大家可以去视频学习。
注:本文基于2019的talk,不知最新版本的调度机制是否有进一步的调整,不过无论调整与否,这并不妨碍我们对GMP设计思想的学习。
九、进一步的改进
有同学在与笔者讨论时提了一个问题:还可以怎么继续优化,这真的是一个非常好的问题,这里将该问题的回答也放入文章。
不单纯针对GMP,话题稍微放大一点,下面简单聊聊goroutine调度机制的一些优化可能。
Dmitry自己在视频最后说的future work方向:
-
在很多cpu core的情况下,活跃线程数比较多,work steal的开销依旧有些浪费。
-
死循环不含cooperative check指令的这种edge情况的还没解决。
-
对于网络和timer的goroutine处理是使用全局方式的,不好scale。
以下纯属个人探讨:
-
首先整体上现在的模型已经比较完善,如何进一步优化要看实践场景遇到的问题,以及profile数据情况,只有问题和数据明确了,才清楚进一步工作的宏观重点(工作中也是,做性能优化需要有宏观视角)。
-
因为goroutine调度是属于协程类的调度,这里或许可以借鉴原来各种协程框架的思路做一些对比考虑。
-
由于笔者并没细看过代码,不大清楚work steal的overhead构成,或许可以设计其他的rebalance方式,例如换个视角,不是去steal,而是由runtime统一rebalance再收集派发。
目前就先想到这些,欢迎讨论。
十、欢乐游戏的协程框架
基于上面那个问题的回答,这里也补充介绍一下欢乐游戏协程框架(基于C++)中采用的处理机制,因为是纯业务自用,所以从设计要求上就低很多,不少点直接都可以不去考虑(这也说明了,有些时候再好的既有流行方案,从性能上讲可能也比不过自家的破轮子,当然自家的轮子泛化不足,肯定普适性就会差很多)
-
协程调度采用最简单的单线程模型
-
设计之初就没考虑用多线程充分利用多核资源,我们认为直接多部署一些进程就好。
-
对于一定要把单进程承载做的很高的极少数场景,可以专事专办,做专门的方案即可。
-
协程采用固定的栈大小
-
通常几百k就够了(例如256k或者512k),创建协程的时候就预分配好。
-
这点确实不如growable stack那么高明,但是从实践看也算够了,这样就免去了stack动态增长的工作(从应用编程的视角看,其实C++里我们可能因为无法做指令插入埋点,本来就做不到stack动态增长)。
-
我们在相邻stack之间加一些写保护page,这样一旦踩了就会 coredump。
-
同时通过编译选项,限制单层栈大小不能超过某个阈值。
-
协程调度完全不考虑公平性,全部采用主动handoff策略
对于某个协程,如果它要持续运行,就任它运行,直到要进行阻塞类操作(典型如RPC调用),才会交出执行权。实际上对于业务来讲,微观层面几十毫秒内哪个协程多占了一点执行权真的无所谓,不用太讲究公平性。假如真的有些协程饿死了,那说明业务都已经过载了(就是时时刻刻都在跑其他协程,cpu100),此时讨论公平也没什么意义了。假如我们真的要做,因为做不到指令插入,只能采用Signals信号中断的方式,在注册的信号处理函数中直接按需切栈。
-
主协程主控循环tick直接管理协程,协程调度不涉及background thread
-
网络IO、第三方异步API tick驱动、timer管理、协程创建销毁管理等都是主协程在做。
-
主控循环中,如果要创建或恢复协程,就任由它去立即执行,一直跑到它阻塞挂起再返回主协程。
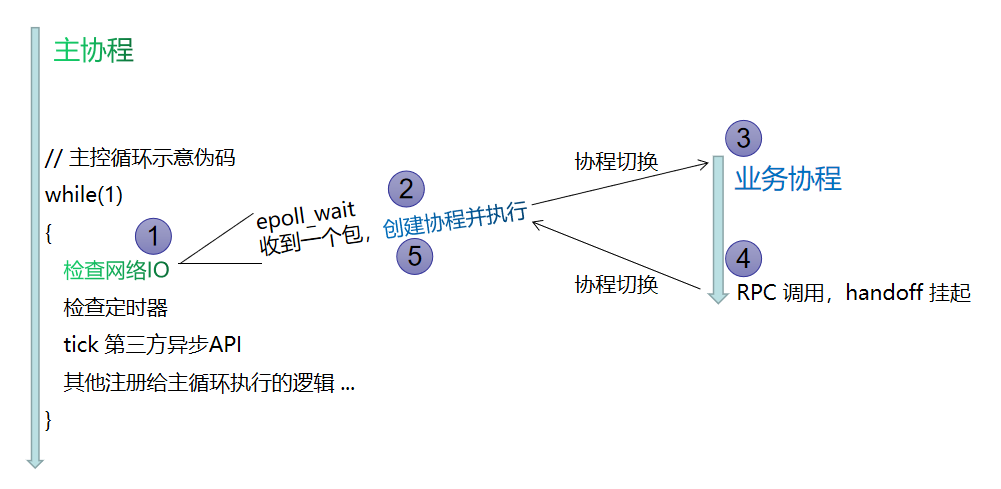
协程切换示意图,图注:1、2、5在主协程,3、4在业务协程,主协程和业务协程都在主线程内。
-
仍可以有基于逻辑分治的多线程
-
框架不是真的只有一个线程,按功能拆分的日志线程,依然可以存在。
-
对于一些第三方异步API,如果其tick本身实现不好,导致大量占据了运行时间,也可以分拆线程,然后用队列之类的机制和主线程的主协程交互即可。
-
对于网络IO也同上。
总之,这种基于逻辑分治做线程拆分的改造都是很简单的,也并不会影响到核心协程调度的机制。


?点击视频号立即预约直播
作者简介

吴连火
腾讯游戏专家开发工程师
腾讯游戏专家开发工程师,负责欢乐游戏大规模分布式服务器架构。有十余年微服务架构经验,擅长分布式系统领域,有丰富的高性能高可用实践经验,目前正带领团队完成云原生技术栈的全面转型。
推荐阅读



文章评论