来源:Demuxed 2021
主讲人:Eric Tang
内容整理:张雨虹
本次演讲主要介绍了如何利用 ffmpeg 对直播流媒体进行自定义的内容分类。首先介绍了 ffmpeg 现有的滤波器,比如超分滤波器或者去雨滤波器。然后讨论了自定义创建场景分类器的过程,介绍了一些训练模型、使用 tensorflow 后端以及利用 GPU 运行模型的经验,该项目已完全开源。
目录
-
背景
-
飞速发展的 ffmpeg AI 滤波器
-
优化 GPU 性能
-
主要工作
-
架构
-
基准测试
-
下一步工作方向
-
链接多个滤波器
-
实时加载更多模型
背景
以 UGC 为中心的直播世界中经常发生用户在某一时间大量涌入的现象,这对于用户规模较大的平台而言是一个亟待解决的问题。Video AI 包含了很多有意思的视频处理功能,包括对低分辨率图像进行超分而获得清晰图像、对视频进行去噪(包括去雨、去雾、去划痕等)、进行对象识别、元数据提取等数百种功能。

对于 Livepeer 而言,由于大量视频都是关于足球和人的,如果我们可以对进入 Livepeer 平台的视频进行场景分类,那我们就可以在后端构建自定义逻辑,来自动化处理这些工作流。同时我们希望借助 ffmpeg 来进行处理。ffmpeg 是视频处理的重要工具。近年来,伴随着基于 AI 的视频处理的流行,ffmpeg 借助于滤波器引入了这些功能。这些滤波器极大地降低了进行AI视频处理的技术障碍。
飞速发展的 ffmpeg AI 滤波器
-
2018 年,引入了超分滤波器(SRCNN 滤波器),创建了通用 DNN 推理接口,引入 Tensorflow 后端。 -
2019 年,作为 GSoC 的一本,使用 tensorflow 后端,引入了去雨滤波器。 -
2020 年,Openvino 被引入,开始拥有了不同类型的 DNN 后端。 -
2021 年,可以为 Tensorflow 执行异步模式,以使其获得更高的性能。
目前,融入这些滤波器,利用 ffmpeg 我们可以进行隔行扫描、去雨、超分等。也可以训练自定义模型来进行分类、检测以及图像处理等,可以将自己的模型加载到后端。
但是对于我们所面临的问题而言,单纯地使用这些滤波器,并不能完全有效解决。我们期望在 UGC 案例中对直播流媒体进行操作,同时解决数千个并发流的操作,真正有效解决这一问题。
优化 GPU 性能
为了能够有效解决这个问题,我们对 GPU 架构进行了研究。
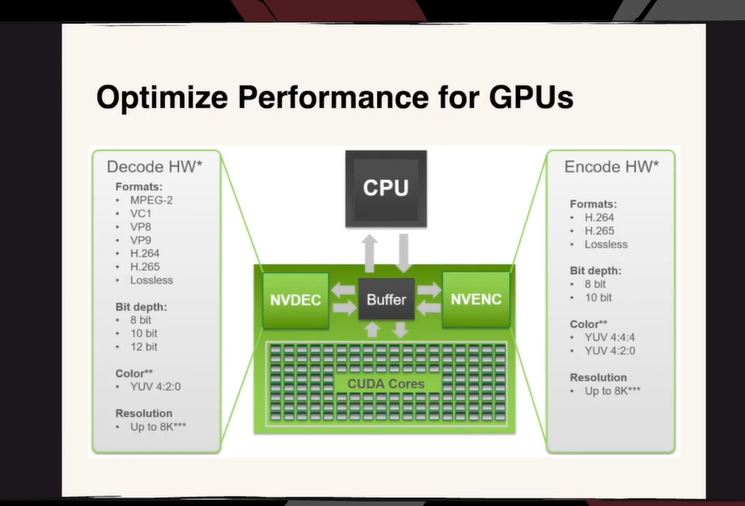
由于 Livepeer 上的大多数视频都在 GPU 上进行了转码,因此研究 GPU 的性能优化是有所帮助的。如果我们能一次性将所有内容都移动到 GPU 上并一次性完成所有内容的操作,这将会节省大量开销,使得事情变得非常高效且节能。
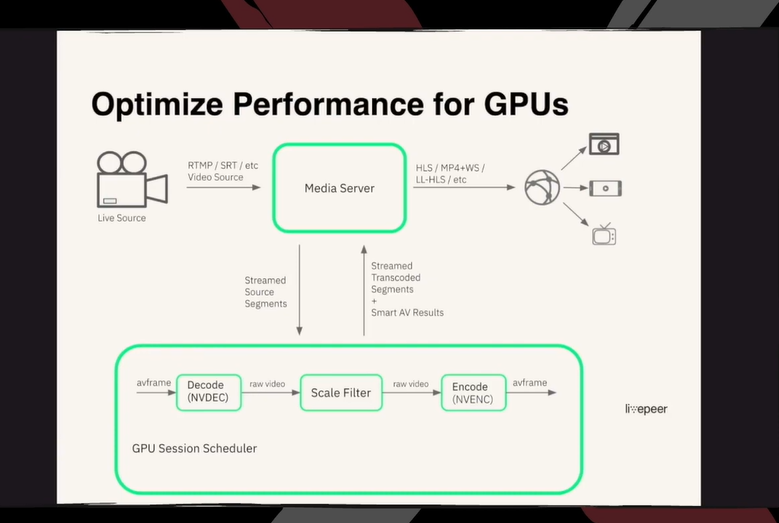
上图底部展示了 GPU 模块工作流程,首先,AV 帧进入解码器,解码器得到源视频;然后源视频进入尺度滤波器,经过滤波,源视频转换为不同大小不同比特率和帧率的视频;最后源视频被送入编码器,重新打包成 HLS 或者 DASH 之类的网络流,发送给用户。因此对于这个处理流程,最好的解决方案是引入一个同样在 GPU 上并行运算的 AI 滤波器,从而使得编解码和 AI 滤波同时发生。基以上设想,我们构建了一个自定义 AI 滤波器。
主要工作
-
训练了自己的模型来检测足球和人。 -
使用 MobileNet v2 来获得真正快速和轻量级的性能。 -
使用 8000 帧图像进行训练,80% 用作训练集,20% 用作测试集。 -
通过实验,输入大小为 224×224 是推理性能和模型精度之间的最佳折衷。 -
训练大概需要 2 天时间。
此外,我们选择了 tensorflow 作为 DNN 后端,以便在 GPU 上运行。ffmpeg 的 DNN 后端为我们提供了进行预处理和后处理的机会,对我们的实现大有益处,比如,预处理阶段,我们可以将源图像缩小到最佳尺寸 224×224。
架构
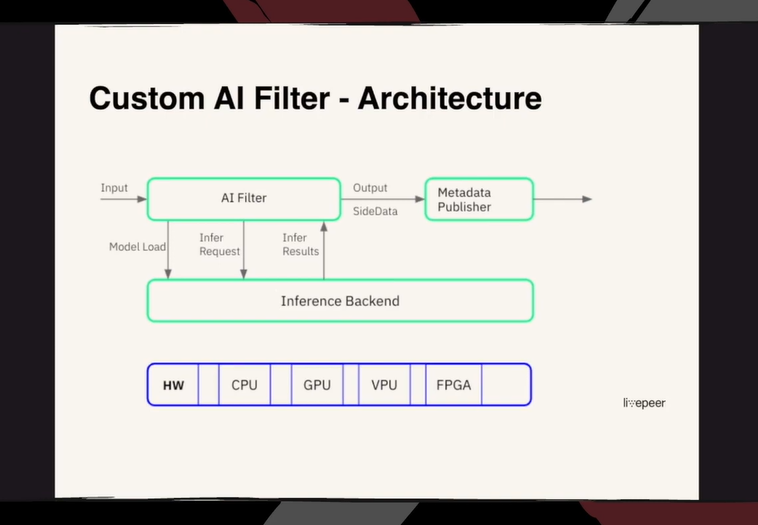
设计的模型架构如上图所示,AI 滤波器接收输入,触发模型加载到推理后端,一旦该模型加载到推理后端,就可以发送推理请求并返回推理结果,推理结果可以作为辅助数据和源视频一起发送到 Metadata Publisher,然后被送入下一段。
基准测试
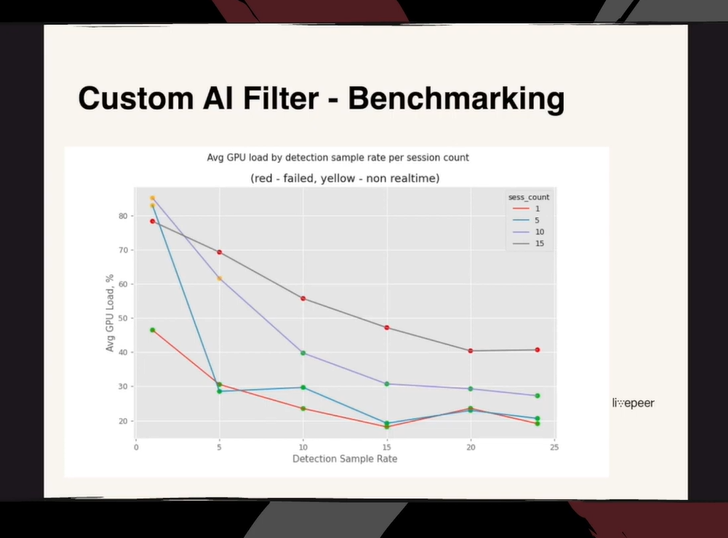
上图展示了实验的测试结果,在单张 RTX 4000 上进行测试,在相同采样率下,该方案可以在进行分类的同时对大约 15 个并发视频流进行全 ABR 梯形 HD 的转码,并且只需要占用大约 40% 的 GPU。
下一步工作方向
链接多个滤波器
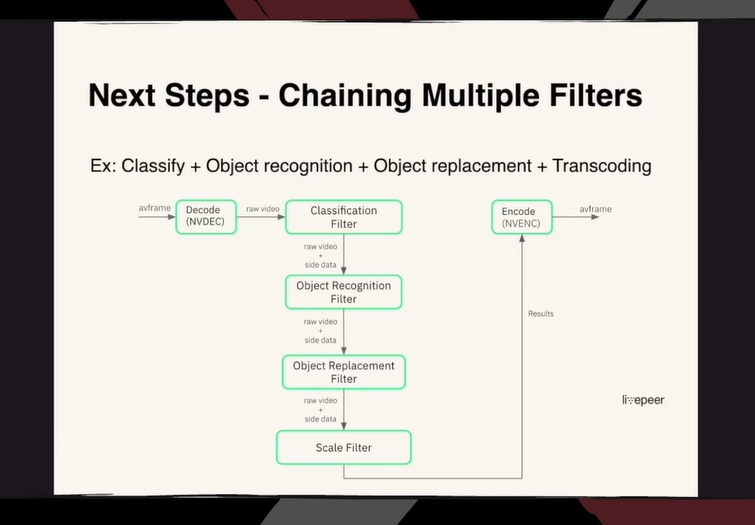
我们期望链接多个滤波器来完成更加复杂和有趣的工作流程。比如,在分类器之后,可以把所有东西送入内容识别滤波器,然后再送入对象替换滤波器,最后再传输视频,这样处理可以帮助我们进行互动性更强的视频处理,取得实时替换视频中对象的效果。
实时加载更多模型
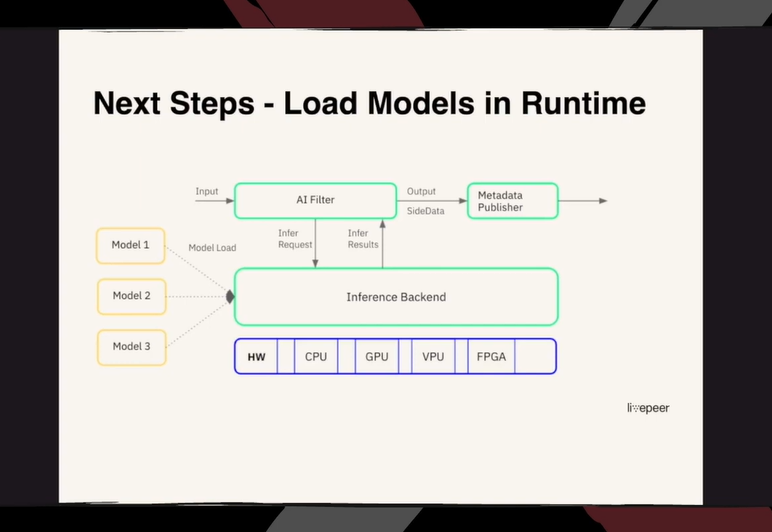
实时加载更多模型有助于拓展工作流程,比如我们可以在开始时进行分类,找出它是什么类型的视频,然后根据视频类型加载不同的模型,以便对视频进行任何类型的操作。
最后附上演讲视频:


文章评论