本文主要从整体角度介绍推荐系统,先介绍了推荐系统定义与系统架构等背景,然后详细说明如何评价一个推荐系统。
推荐系统简介
推荐系统可以说是机器学习和深度学习应用最广泛的领域,而且预期未来会更加流行和深入。它本质上是为用户和商品或服务之间建立一种连接,帮助用户更高效地享受到服务。
从用户的角度看,用户的个人偏好(兴趣)、历史行为、用户个人属性、用户关系网络等等都可以被称为 “用户信息”;从商品或服务角度看,名称、属性、标签、内容等等都是 “商品信息”;另外,在具体的场景中,用户的选择可能受时间、地点等一系列环境信息影响,这类信息被称为 “场景信息/上下文信息”。
由此,借用王喆老师的描述,可以得出推荐系统要处理的问题形式化定义:对于某个用户 U,在特定场景 C 下,针对商品构建一个函数,预测用户对特定候选商品 I 的效用,并据此对候选商品排序得到推荐列表的问题。定义中的函数在推荐系统中一般被称为 “推荐系统模型”。
推荐系统架构
提到 “系统”,那自然是个有机整体,其中一般会包括多个组成部分。推荐系统从大的层面来看主要包括两个方面:
数据和信息: 用户、场景、商品信息的定义、组成是什么?如何获取信息?如何处理、更新信息?如何传输、存储信息?
模型和算法: 如何选择模型、算法?如何训练?如何更新?如何评估?如何部署推理?

从系统运行的角度看推荐系统,可以参考下面 Netflix 的推荐系统经典架构图: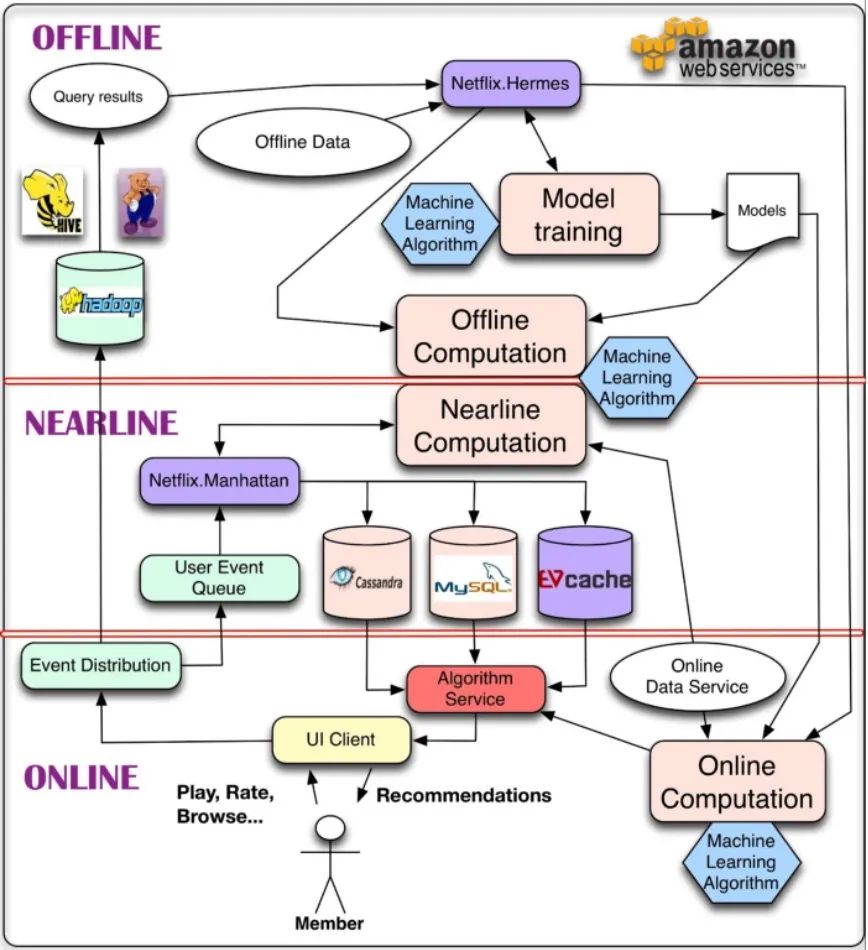
推荐系统评价方法
推荐系统的评价涉及到多个方面,除了机器学习相关的指标外,还有大量工程、甚至产品和运营方面的指标。
1.用户偏好/满意度
评价系统好坏最直接的方法是让用户投票,选择票数高的。或者也可以通过一些间接指标来衡量,比如购买率、停留时长、转化率等。
使用这种方法有一个注意事项:
该方法假定用户的权重一致,这在实际中很难应用,因为购买多次多个产品的用户显然比只购买过几次产品的用户重要。我们可以给用户分配权重,但如何确定权重并不容易。如果按照一定时间范围内购买金额来衡量,可能存在有着明确品牌偏好的高购买额用户,购买产品时绕过推荐直接定位该产品。相对可操作的方法,可能是首先对用户分组(根据购买额或其他特征),然后对不同分组赋予权重。
一种特例是,偏好系统 A 的用户只是稍微偏好一点点,但偏好 B 的用户非常不喜欢 A。对这种情况,即使偏好 A 的票数高于 B 的,也应该选择 B 而不是 A。
最后,当改进这个系统时,重要的是知道用户为什么偏好某一个。所以将满意度分解成更小的组件有助于系统的改进。
2.预测准确率
即根据推荐模型预测用户偏好的准确性。具体包括:评级准确性、使用准确性和排名准确性。
2.1 评级预测
即预测用户评级(评级高的自然可以推荐)。具体指标包括:
1.均方根误差 RMSE(Root Mean Squared Error):
其中,T 是测试集,u 和 i 分别表示用户和商品 Item,r 表示评级。
2.平均绝对误差 MAE(Mean Absolute Error)
比较RMSE与MAE,RMSE 会不成比例(平方项)地惩罚较大的误差。
在此基础上,还有NRMSE 和 NMAE 是 RMSE 和 MAE 的归一化版本,具体做法是对每一项除以 r_max-r_min;平均 RMSE 和平均 MAE 针对测试集分布不均衡的情况。比如测试集中 Item 的分布不均衡,此时可以分别计算每个 Item 的 RMSE 或 MAE,然后再求所有 Item 的平均值。
3.失真度 d(r', r)
有些时候误差不仅仅取决于幅度,此时可以使用失真度 d(r', r) 来度量。比如有三个等级的某评级系统,123 分别表示 “不喜欢、中立、喜欢”,推荐一个不喜欢的商品还不如不推荐,此时失真度可以这么衡量:d(3,1) = 5, d(2,1) = 3, d(3,2) = 3, d(1,2) = 1, d(2,3) = 1, d(1,3) = 2。意思就是 d(1,3) 比 d(3,1) 误差小,也就是说 “真实值为 3 预测为 1” 要比 “真实值为 1 预测为 3” 好。
2.2 使用预测
这种情况预测的不是用户对具体 Item 的偏好,而是用户可能使用的 Item。此时可以用 PR 来衡量,对应的混淆矩阵计算方法如下:
| 推荐 | 未推荐 | |
|---|---|---|
| 使用 | TP | FN |
| 未使用 | FP | TN |
当可以向用户提供的推荐数量是预先确定的时,使用 Precision@N 或 Recall@N,否则使用 P-R 或 ROC 曲线。两者的区别可以参考 Metrics | Yam。
2.3 排序预测
此时关注的是相对顺序,而不是绝对值。有两种方法:一种是定义好一组 Item 的顺序,让系统来预测正确的顺序,然后评估接近程度;另一种是评估系统排序对用户的效用。
Reference Ranking
对第一种方法,我们必须要有一个参考。这个参考可以通过用户的评级来确定;或者通过使用/未使用确定,即,使用过的优于未使用过的,比如跳过播放的曲子和听完的曲子。上面这两种情况,Item 之间是没有区别的,比如两个都是 5 星的电影或都是跳过的曲子,但是我们又需要对它们也进行排序。此时可以使用 Normalized Distance-based Performance Measure(NDPM)来评估。给定参考排序 r_ui 和预测排序 r'_ui,有如下定义:
求和的范围是 1/2 * Nu(Nu - 1),也就是两两 Item 一组,Cu 表示参考排序(Label)中能确定顺序的组数,C+ 和 C- 分别表示这些组(即参考排序中能确定顺序的组)预测结果中顺序正确和顺序错误的组数,Cu0 表示参考排序(Label)有序但是预测结果一样(Item 之间无区别)的组数。
最好结果为 0,表示预测到了所有的有序结果;最差结果为 1(不考虑惩罚系数 0.5),表示 Label 中的有序结果要么没预测出来顺序,要么顺序是错的。
有时候,我们明确地知道用户对某些 Item 的真实偏好,此时,如果参考中一组 Item 无序,意味着用户的确不关心它们之间的顺序(比如我们知道用户不喜欢流行音乐,那么跳过的流行音乐之间就应该无序)。因此,预测结果也不应该有序。此时,使用 Spearman ρ 或 Kendall τ 来进行评估。
这里需要注意的是,无序的 Item 应该取平均顺序作为实际的顺序,比如排在 2 和 3 位,则两者的 rank 为 2.5。
Utility-based Ranking
第二种方法假设一列推荐结果的效用是可加的,每个结果的效用根据位置按特定因子递减。大多数情况下,用户实际上只使用了非常少的一组 Item,我们期望是排在推荐结果前面的 Item。此时,可以使用 R-Score 进行评估,该方法假定推荐结果 Item 的价值指数下降:
i_j 表示 Item 在第 j 个位置,r_ui 表示用户 u 对 Item i 的评级,d 是一个任务相关的评级,α 是半衰期参数,它控制最终排序结果中 Item 的价值呈指数下降。
在预测任务中,r_ui 表示用户对 Item 的评级,具体使用时,可以令 r_ui 为 1(i 被选择时)或 0(i 未被选择时),d 为 0;或者让 r_ui = -log(popularity(i))(i 被选择时)或为 0(i 未被选择时),这种算法可以捕获推荐中的信息量。每个用户的分数通过下式最终合并:
其中,Ru* 表示对用户 u 最好的可能排序结果的分数。
有些时候,可能需要较大比例(比如搜索)的一组 Item,这时候需要一个较小的按位置递减的因子,可以使用 Normalized Cumulative Discounted Gain(NDCG)进行评估,它是对数下降的:
假设每个用户 u 在被推荐为 Item i 时都获得收益(g_ui)。
Online Evaluation of Ranking
可以通过用户与系统的行为交互结果进行评估。比如用户选择了第一页的某几个项目,那么可以将结果分为三个部分:用户选择的、第一页用户没选择的、剩余未知的。然后就可以对结果进行评估了。具体而言有两种方式:
-
从上到下:选择的 + 未知的 + 未选择的 -
从上到下:选择的 + 未选择的:在做出不合理假设时比较有用
无论选择哪种方式,都要特别注意与离线方式的差别。离线时,我们只有一个参考排序;在线时,参考排序变成了给定系统排序结果下用户偏好的排序,此时不止有一个参考排序。
对于 utility-based ranking,可以通过对选中 Item 的效用求和来评估,接近所有结果开始处的选中的 Item(高效用)将会放在后面,因为这些项目已经出现过了。
3.覆盖率
覆盖率是用来描述一个推荐系统对物品长尾的发掘能力,一个简单的定义可以是:推荐系统所有推荐出来的商品集合数占总物品集合数的比例。
Item Space Coverage
即推荐系统可以推荐的 Item 的比例(推荐出来 Item 集合数/总商品集合数),通常被称为 “catalog coverage”。一个简单的方法是计算推荐给用户的所有 Item 的比例。另一个方法叫做 “sales diversity”,衡量使用特定推荐系统时不相同的 Item 如何被用户选择。假设每个 Item i 占用户选择的比例为 p(i),Gini 指数为:
i_1, ...i_n 表示 Item 根据 p(i) 从小到大排列的列表,G=0 表示所有 Item 被均等选择,G=1 表示单个 Item 经常被选择。
另一个评估分布不均的方法是熵:
0 表示单个 Item 经常被选择,logn 表示 n 个 Item 被选择。
User Space Coverage
覆盖范围也可以是系统可以为其推荐 Item 的用户或用户交互的比例。有些时候,因为 Accuracy 的低信度系统可能不会为某些用户做推荐。在这种情况下,我们可能更喜欢可以为更广泛的用户提供推荐的推荐系统。显然,评估这类推荐系统应该在覆盖率和准确性之间进行权衡取舍。这里的覆盖范围可以通过推荐所需的用户个人资料的丰富程度来衡量。
4.多样性
多样性是相似性的反面,衡量方法是使用 item-item 相似度,通常基于项目内容。然后可以根据【项目对】之间的总和,平均,最小或最大距离来衡量列表的多样性,或者衡量将每个项目添加到推荐列表中的价值,作为新项目与已有项目之间的多样性。
其中,s_ij 表示 Item i 和 Item j 的相似度。
5.新颖性
对用户不知道 Item 的推荐。一种显而易见且易于实现的方法是过滤掉用户已经评分或使用过的项目。但是,在许多情况下,用户不会报告他们过去使用过的所有项目。
除了直接问用户是否对已经推荐的项目熟悉外,离线实验同样可以帮助我们理解新颖性。在该实验中,我们可以将数据集按时间切分,比如隐藏发生在某一特定时点后的用户评分。同时,也可以隐藏一些在该时点前的评分,用于模拟用户熟悉但未报告评分的项目。推荐时,系统会为该时点后推荐和评分的每个项目(新项目)提供奖励,但对推荐的在该时点之前评分的每个项目(旧项目)进行惩罚。在使用这种度量方法时,控制准确性非常重要,因为不相关的商品对于用户可能是新的,但并没有价值。一种解决方法是仅在相关项目中考虑新颖性。
另一种方法也利用了 “流行商品不太可能是新颖的” 假设,把流行度考虑到了准确性的度量中。
其他方面的评估还包括:系统可信度、用户可信度、意外程度(比如根据推荐的电影用户发现一个她喜欢的新演员)、效用、风险、鲁棒性、隐私性、适应性(灵活)、可伸缩性等。
本文是一篇教程学习笔记,源自Datawhale开源的《Fun-Rec》推荐系统中文教程,欢迎感兴趣的伙伴关注,并一起完善!
开源地址:https://github.com/datawhalechina/fun-rec
本文参考资料
-
(PDF) Evaluating Recommendation Systems
下载地址:https://www.researchgate.net/publication/226264572_Evaluating_Recommendation_Systems
-
Datawhale开源教程Fun-Rec -
深度学习推荐系统实战_王喆 -
System Architectures for Personalization and Recommendation | by Netflix Technology Blog | Netflix TechBlog


文章评论