
【CSDN 编者按】程序员刷豆瓣也要刷出技术感,本文爬取豆瓣 TOP250 告诉你这些书“热门”在哪里!案例分析之外,重在梳理编写爬虫的逻辑和链路关键点,手把手教你形成自己编写爬虫的方法论。
Are you ready? Let's go!

作者 | 周志鹏
责编 | 郭 芮
本文以爬取豆瓣TOP250图书为例,但重点并不在案例本身,而在于梳理编写爬虫的逻辑和链路关键点,帮助感兴趣的童鞋逐渐形成自己编写爬虫的方法论(这个是最最最关键的),并在实战中体验requests+xpath绝妙的感觉。没错,这一招requests+xpath(json)真的可以吃遍天。
马克思曾经没有说过——当你浏览网页时,看到的只是浏览器想让你看到的。这句话道出了一个真谛——我们看到的网页只一个结果,而这个网页总是由众多小的“网页(或者说部分)”构成。
就像拼图,我们看到的网页其实是最终拼好的成品,当我们输入一个网址,浏览器会"自动"帮我们向远方的服务器发送构成这个大拼图的一众请求,服务器验证身份后,返回相关的小拼图(请求结果),而浏览器很智能的帮助我们把小拼图拼成大拼图。
我们需要的,就是找到网页中存储我们数据的那个小拼图的网址,并进一步解析相关内容。以豆瓣TOP250图书为例,爬虫的第一步,就是“审查元素”,找到我们想要爬取的目标数据及其所在网址。
豆瓣TOP250图书网址:https://book.douban.com/top250

审查元素,找到目标数据所在的URL
审查元素,就是看构成网页的小拼图具体是怎么拼的,操作起来很简单,进入网页后,右键——审查元素,默认会自动定位到我们所需要的元素位置。
比如我们鼠标移动到“追风筝的人”标题上,右键后审查元素:
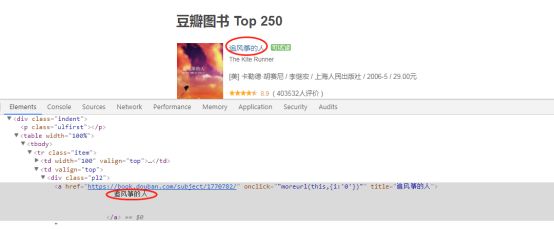
其实,我们需要的数据(图书名称、评价人数、评分等等)都在一个个网页标签中。爬虫这玩意儿就是刚开始看着绕但用起来很简单,极简主义友情提示,不要被复杂的结构迷惑。
在彻底定位目标数据之前,我们先简单明确两个概念。
网页分为静态和动态,我们可以粗暴理解为,直接右键——查看源代码,这里显示的是静态网址的内容,如果里面包含我们需要的数据,那直接访问最初的网址(浏览器网址栏的网址)即可。
而有的数据是在我们浏览的过程中默默新加载(浏览过程中向服务器发送的请求)的,这部分网页的数据一般藏在JS/XHR模块里面。
是这样操作的:审查元素——刷新网址——NETWORK——JS或者XHR。
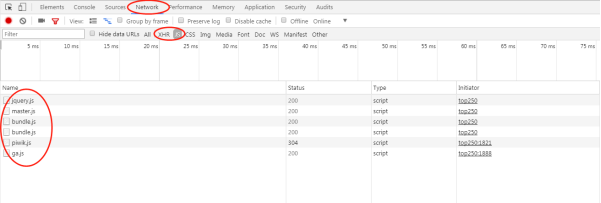
概念讲解到此为止,下面是操作详解,即我们如何找到我们需要的网址。
一般来说,静态网页中的数据比较容易获取,爬取之前我们养成先查看源代码的方式检查所需要的数据是否在静态网页中的习惯。
右键——查看源代码:

验证一下需要的数据在静态网址中是否出现,CTRL+F快捷查找,然后输入我们刚才看到的图书榜第一的“追风筝的人”。
成功找到!得来全不费工夫,朝下拉,发现需要的所有数据都在静态网址中,完全不需要去动态网页中一步步排查了。

尝试请求,报错中前行
我们刚才发现目标数据是在静态网址中,直接访问https://book.douban.com/top250就可以拿到。下一步,借助PYTHON中requests的get方法很高效的实现网页访问。
import requests
html = requests.get('https://book.douban.com/top250')requests.get函数第一个参数默认是请求的网址,后面还有headers,cookeis等关键字参数,稍后会讲。
OK,一个访问请求完成了,是不是超级简单?访问完成后,我们可以看一下返回的内容:

一般都会讲返回的状态码以及对应的意义,但个人觉得直接暴力抽看返回内容也很方便。
很尴尬,没伪装都访问成功了,之前验证headers的豆瓣现在连headers都不验证了。小豆,你堕落了......但关于爬虫模拟用户行为必须敲黑板讲重点!!!
当我们用PYTHON对目标网址进行访问,本质上是用PYTHON对目标服务器发送了一个请求,而这种机器(Python)并不是真实的用户(通过浏览器请求的),这种“虚假”访问是服务器深恶痛绝的(爬虫会对网站服务器造成负荷,而且绝大多数网站并不希望数据被批量获取)。所以,如果想要万无一失,访问行为必须模拟,要尽可能的让你的爬虫像正常的用户。最常规的方法就是通过伪装headers和cookies来让我们的爬虫看起来更像人。
继续举个例子:
你住在高档小区,小P这个坏小伙想伪装你进小区做不可描述的事情。
他知道,门卫会根据身份象征来模糊判断是否是小区业主,所以小P先租了一套上档次的衣服和一辆称得上身份的豪车(可以理解为伪装headers),果然混过了门卫。但是呢,小P进进出出太频繁,而且每次停车区域都不一样,引起了门卫的严重怀疑,在一个星期后,门卫升级检验系统,通过人脸识别来验证,小P被拒绝在外,但很快,小P就通过毁容级别的化妆术(伪装cookies),完全伪装成你,竟然混过了人脸识别系统,随意出入,为所欲为。
此处主要是形象化科普,其实还有IP等更复杂的伪装方式,感兴趣的同学可以自己研究。
所以,为了保险起见,我们还是构造伪装成正常浏览器的请求头。
找到静态网址和其关键参数(请求头headers相关参数都在Request Headers下):
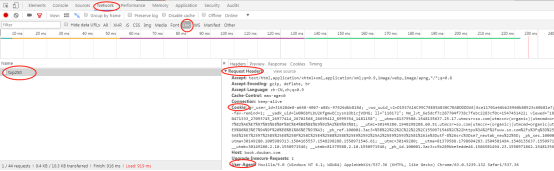
requests库会有默认的headers,关键参数都是字典格式,这里我们把浏览器的参数赋值给headers,从请求头的角度伪装成正常浏览器。
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#再来请求一次
html = requests.get('https://book.douban.com/top250',headers = headers)
html.text[:200]
#成功返回结果

请求成功,解析并定位到我们需要的数据
刚才我们拿到了正确的返回结果html,所有的内容都包在html.text里,我们需要对这一大包内容进行解析和定位,xpath就登场了。
操作如下:
from lxml import etree
bs = etree.xpath(html.text)
#这一步把HTML的内容解析成xpath方法可以很容易定位的对象,其实就是为定位数据做好准备的必要一步,记住这步必要的操作。
先举个例子讲解用法:

注:xpath的索引都是从1开始的,谨记谨记!
这里缩进代表从属关系,我们想要的作者信息被包裹在<p classs = "pl">的标签内,从下到上又从属于上一级的div标签——td标签——tr标签。
怎么用xpath获取?
bs.xpath('//tr[@class = "item"]/td[2]/p')[0].text
//代表从根目录(从上到下)开始定位(初始定位都需要这样),tr[@class = "item"]表示找到class等于item标签,因为可能会有很多个tr标签,我们通过class属性来区分,tr后面的/代表下一级,td[2]表示定位到第二个td标签,然后再下一级的p标签,并获取他的内容text。
如果是要获取p里面class的值:
bs.xpath('//tr[@class = "item"]/td[2]/p/@class'))[0]
还没完全理解?不要紧,用一下就会了,Let's do it!
鼠标移动到"追风筝的人”作者名上,右键——审查元素:
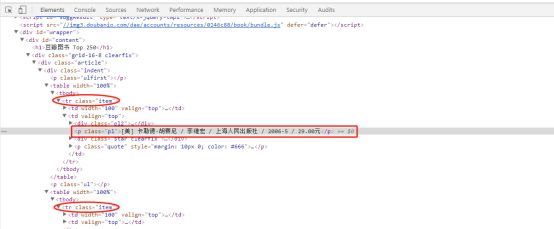
关于书籍作者相关的信息都被包裹在p标签中,而p标签又从属于td-tr-tbody-table。
再进一步点击,书名、评价数、评分等相关信息也都是在类似的链路,所有的信息都被包裹在tr[@class = "item"]这一级,虽然再往上一级的tbody和table也可以,但只要定位到tr就够了。
我们来定位一下:
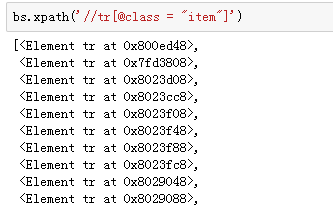
返回了一系列对象,数一数(这个地方没截全),正好25个,对应着我们在浏览器中看到的25本书的相关信息。我们先用第一个对象,来尝试定位需要的关键信息。

注:我们定位了第一个元素,书籍相关信息都被包裹着(从属于他),我们想要进一步定位,很简单,直接调用xpath方法,而且开头不需要加//:
书籍名:

作者、出版社信息:

细心的同学一定发现了,定位返回的值是一个列表,我们通过索引[0]来提取里面的内容,至于定位元素,我们既可以通过序号(td[2]/div[1]这样),也可以通过对属性进行赋值(p[@class = "pl"])来判断。
Emmm,有一个疑惑点非常容易对人造成困扰,就是定位了之后,我们怎么提取我们需要的信息,举个例子:

大家会发现,作者相关信息是被包裹在<p class = "pl">和</p>之间的,具体的HTML语法不用管,我们只要明白,标签中间的内容是文本,而标签内的内容(class或者其他名字)叫属性,xpath提取文本是通过 .xpath('p[@class = "pl"]')[0].text方法。而想要拿到标签内的属性(这里是pl) 是用 ('p[@class = "pl"]/@class') 方法提取。
下面,继续提取关键信息:
评分:

评价人数:

一句话概括:

OKAY,我们把定位提取操作汇总一下:
#这里创建一个DATAFRAME来存储最终结果
result = pd.DataFrame()
for i in bs.xpath('//tr[@class = "item"]'):
#书籍中文名
book_ch_name = i.xpath('td[2]/div[1]/a[1]/@title')[0]
#评分
score = i.xpath('td[2]/div[2]/span[2]')[0].text
#书籍信息
book_info = i.xpath('td[2]/p[@class = "pl"]')[0].text
#评价数量由于数据不规整,这里用PYTHON字符串方法对数据进行了处理
comment_num = i.xpath('td[2]/div[2]/span[3]')[0].text.replace(' ','').strip('(\n').strip('\n)')
#一句话概括
brief = i.xpath('td[2]/p[@class = "quote"]/span')[0].text
#这里的cache是存储每一次循环的结果,然后通过下一步操作循环更新result里面的数据
cache = pd.DataFrame({'中文名':[book_ch_name],'评分':[score],\
'书籍信息':[book_info],'评价数量':[comment_num],'一句话概括':[brief]})
#把新循环中的cache添加到result下面
result = pd.concat([result,cache])
结果像酱紫(截取了部分):
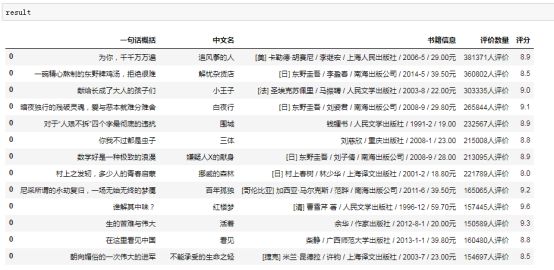
呼~最关键的数据定位,数据获取已经完成了。

翻页爬取,尽收囊中
俗话说的好,拿一血者拿天下。我们已经拿到了第一页的数据,其他页面数据都是一样的结构,最后只需要我们找到网页变化的规律,实现翻页爬取。
我们在浏览器中翻到下一页(第二页)。当当当当!浏览器网址栏的网址的变化你一定发现了!

再下一页(第三页):

我们有理由进行推断,网址前面的结构都是不变的,决定页数的关键参数是start后面的数字,25代表第二页,50代表第三页,那一页就是0,第四页就是75,以此类推。
来来回回翻页,不出所料,翻页的关键就是start参数的变化。所以,我们只需要设置一个循环,就能够构造出所有的网址。
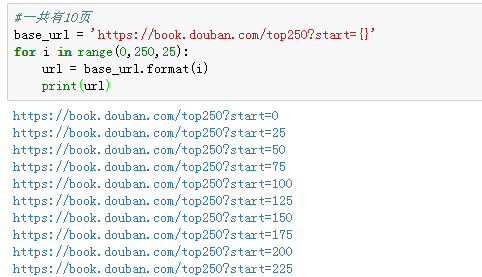
至此,各个模块的代码可谓大功告成!
最后,先来一个TOP50词云版书单,再附上完整代码来抛砖引玉:

import pandas as pd
import requests
from lxml import etree
import time
#循环构造网址
def format_url(base_url,pages = 10):
urls = []
for num in range(0,pages * 25,25):
urls.append(base_url.format(num))
return urls
#解析单个页面
def parse_page(url,headers):
#创建一个存储结果的容器
result = pd.DataFrame()
html = requests.get(url,headers = headers)
bs = etree.HTML(html.text)
for i in bs.xpath('//tr[@class = "item"]'):
#书籍中文名
book_ch_name = i.xpath('td[2]/div[1]/a[1]/@title')[0]
#评分
score = i.xpath('td[2]/div[2]/span[2]')[0].text
#书籍信息
book_info = i.xpath('td[2]/p[@class = "pl"]')[0].text
#评价数量由于数据不规整,这里用PYTHON字符串方法对数据进行了处理
comment_num = i.xpath('td[2]/div[2]/span[3]')[0].text.replace(' ','').strip('(\n').strip('\n)')
try:
#后面有许多书籍没有一句话概括
#一句话概括
brief = i.xpath('td[2]/p[@class = "quote"]/span')[0].text
except:
brief = None
#这里的cache是存储每一次循环的结果,然后通过下一步操作循环更新result里面的数据
cache = pd.DataFrame({'中文名':[book_ch_name],'评分':[score],\
'书籍信息':[book_info],'评价数量':[comment_num],'一句话概括':[brief]})
#把新循环中的cache添加到result下面
result = pd.concat([result,cache])
return result
def main():
final_result = pd.DataFrame()
base_url = 'https://book.douban.com/top250?start={}'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
urls = format_url(base_url,pages = 10)
for url in urls:
res = parse_page(url,headers = headers)
final_result = pd.concat([final_result,res])
#爬虫要文明,这里设置了一个爱心520时间
time.sleep(5.2)
return final_result
if __name__ == "__main__":
final_result = main()作者:周志鹏,2年数据分析,深切感受到数据分析的有趣和学习过程中缺少案例的无奈,遂新开公众号「数据不吹牛」,定期更新数据分析相关技巧和有趣案例(含实战数据集),欢迎大家关注交流。
声明:本文为作者原创投稿,未经允许请勿转载,欢迎大家通过以下方式联系投稿。

热 文 推 荐
☞ 云评测 | OpenStack智能运维解决方案 @文末有福利!
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
![]() 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。


文章评论